本节主要介绍指令选择的具体步骤(select). select是将基于ISD SDNode的DAG替换成基于机器指令节点的DAG的过程.
在完成combine与legalize之后SelectionDAGISel::CodeGenAndEmitDAG()会调用SelectionDAGISel::DoInstructionSelection()进行指令选择.
void SelectionDAGISel::DoInstructionSelection() {
PreprocessISelDAG();
{
DAGSize = CurDAG->AssignTopologicalOrder();
HandleSDNode Dummy(CurDAG->getRoot());
SelectionDAG::allnodes_iterator ISelPosition (CurDAG->getRoot().getNode());
++ISelPosition;
ISelUpdater ISU(*CurDAG, ISelPosition);
while (ISelPosition != CurDAG->allnodes_begin()) {
SDNode *Node = &*--ISelPosition;
if (Node->use_empty())
continue;
Select(Node);
}
CurDAG->setRoot(Dummy.getValue());
}
PostprocessISelDAG();
}
PreprocessISelDAG()与PostprocessISelDAG()是SelectionDAGISel类提供的hook, 用于指令选择前后做架构相关的优化. 在这之前几个架构custom的时间点中DAG combine时不能保证opcode与operand的合法性, custom legalize聚焦于opcode的合法化以保证指令选择时覆盖整个DAG的节点, 而此处两个接口最适合做基于(合法化后的)DAG的窥孔优化.
注意到在指令选择前还会调用一次AssignTopologicalOrder()重新排序, 并且以逆序方式遍历节点, 这种从上往下的遍历方式与SelectCode代码逻辑结合, 保证了最贪婪的tree pattern匹配.
Select()又是一个SelectionDAGISel类提供的hook, 每个后端架构都必须要实现该接口, 仍然以RISCV架构为例.
void RISCVDAGToDAGISel::Select(SDNode *Node) {
if (Node->isMachineOpcode()) {
Node->setNodeId(-1);
return;
}
// Instruction Selection not handled by the auto-generated tablegen selection
// should be handled here.
unsigned Opcode = Node->getOpcode();
MVT XLenVT = Subtarget->getXLenVT();
SDLoc DL(Node);
EVT VT = Node->getValueType(0);
switch (Opcode) {
case ISD::Constant: {
auto ConstNode = cast<ConstantSDNode>(Node);
if (VT == XLenVT && ConstNode->isNullValue()) {
SDValue New = CurDAG->getCopyFromReg(CurDAG->getEntryNode(), SDLoc(Node),
RISCV::X0, XLenVT);
ReplaceNode(Node, New.getNode());
return;
}
int64_t Imm = ConstNode->getSExtValue();
if (XLenVT == MVT::i64) {
ReplaceNode(Node, selectImm(CurDAG, SDLoc(Node), Imm, XLenVT));
return;
}
break;
}
......
}
// Select the default instruction.
SelectCode(Node);
}
static SDNode *selectImm(SelectionDAG *CurDAG, const SDLoc &DL, int64_t Imm,
MVT XLenVT) {
RISCVMatInt::InstSeq Seq;
RISCVMatInt::generateInstSeq(Imm, XLenVT == MVT::i64, Seq);
SDNode *Result = nullptr;
SDValue SrcReg = CurDAG->getRegister(RISCV::X0, XLenVT);
for (RISCVMatInt::Inst &Inst : Seq) {
SDValue SDImm = CurDAG->getTargetConstant(Inst.Imm, DL, XLenVT);
if (Inst.Opc == RISCV::LUI)
Result = CurDAG->getMachineNode(RISCV::LUI, DL, XLenVT, SDImm);
else
Result = CurDAG->getMachineNode(Inst.Opc, DL, XLenVT, SrcReg, SDImm);
// Only the first instruction has X0 as its source.
SrcReg = SDValue(Result, 0);
}
return Result;
}
通常一个后端架构的Select()接口由两部分组成, 手工编码指令选择与通过td自动生成pattern match的匹配代码, 通常不能通过编写pattern获取最佳选择的指令会通过手工编码的方式, 因此这块代码在pattern match代码前执行. 只有在手工选择失败之后才会调用SelectCode()进行pattern match匹配, 如果还失败则会调用SelectionDAGISel::CannotYetSelect()报错(在移植一个新架构时常见情况).
我们以RISCV为例看下什么情况需要手工编码指令选择. 其常量赋值(给寄存器)的语义对应的硬件指令比较特殊, 原因是
可见Select()中首先对ISD::Constant节点判断其值是否为0, 为0则直接替换为寄存器拷贝, 其次调用selectImm()中对第二种情况分类讨论.
在选择了最优的指令后调用SelectionDAG::getMachineNode()创建一个新节点, 注意该接口与SelectionDAG::getNode()的区别在于对glue节点处理的不同, 其它处理是一样的.
MachineSDNode *SelectionDAG::getMachineNode(unsigned Opcode, const SDLoc &DL,
SDVTList VTs,
ArrayRef<SDValue> Ops) {
bool DoCSE = VTs.VTs[VTs.NumVTs-1] != MVT::Glue;
MachineSDNode *N;
void *IP = nullptr;
if (DoCSE) {
FoldingSetNodeID ID;
AddNodeIDNode(ID, ~Opcode, VTs, Ops);
IP = nullptr;
if (SDNode *E = FindNodeOrInsertPos(ID, DL, IP)) {
return cast<MachineSDNode>(UpdateSDLocOnMergeSDNode(E, DL));
}
}
// Allocate a new MachineSDNode.
N = newSDNode<MachineSDNode>(~Opcode, DL.getIROrder(), DL.getDebugLoc(), VTs);
createOperands(N, Ops);
if (DoCSE)
CSEMap.InsertNode(N, IP);
InsertNode(N);
NewSDValueDbgMsg(SDValue(N, 0), "Creating new machine node: ", this);
return N;
}
SDValue SelectionDAG::getNode(unsigned Opcode, const SDLoc &DL, EVT VT) {
FoldingSetNodeID ID;
AddNodeIDNode(ID, Opcode, getVTList(VT), None);
void *IP = nullptr;
if (SDNode *E = FindNodeOrInsertPos(ID, DL, IP))
return SDValue(E, 0);
auto *N = newSDNode<SDNode>(Opcode, DL.getIROrder(), DL.getDebugLoc(),
getVTList(VT));
CSEMap.InsertNode(N, IP);
InsertNode(N);
SDValue V = SDValue(N, 0);
NewSDValueDbgMsg(V, "Creating new node: ", this);
return V;
}
SelectCode()是tablegen自动生成的指令选择器的实现, 其定义见llvm build目录下lib/Target/[arch]/[arch]GenDAGISel.inc(其中arch为具体后端架构名). 以RISCV为例其实现如下
void DAGISEL_CLASS_COLONCOLON SelectCode(SDNode *N)
{
// Some target values are emitted as 2 bytes, TARGET_VAL handles
// this.
#define TARGET_VAL(X) X & 255, unsigned(X) >> 8
static const unsigned char MatcherTable[] = {
......
}; // Total Array size is 25735 bytes
#undef TARGET_VAL
SelectCodeCommon(N, MatcherTable,sizeof(MatcherTable));
}
注意到SelectCode()定义了一个非常大的静态数组并将其传给SelectCodeCommon, 该数组是tablegen根据td中定义的pattern生成的一个状态跳转表, 我们将在接下来解释其具体构成.
在这之前我们首先思考一个问题, 给定指令的语义与输入DAG, 如何将其映射到对应的指令? 举个简单的例子一个架构支持三条指令, MUL对应乘法运算, SUB对应减法运算, SRL对应逻辑右移, 那么对应下图1中的DAG我们该如何将其映射为机器指令.
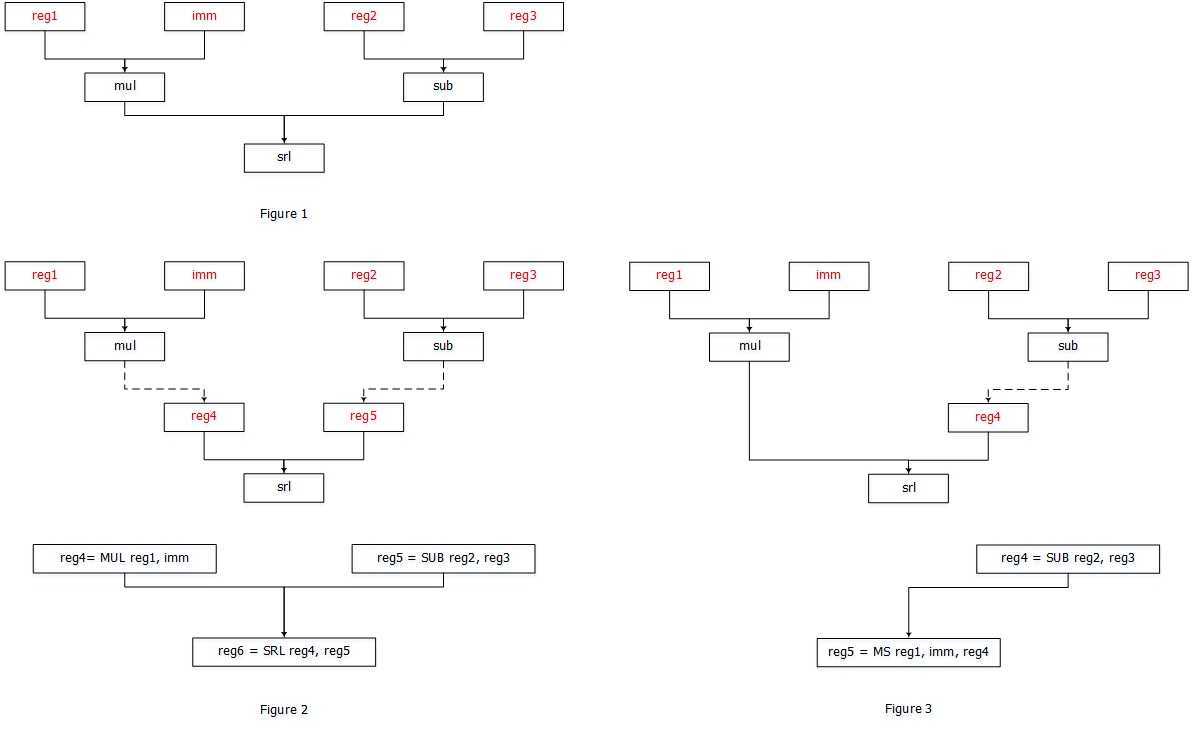
最简单的方式是将指令描述为对应的DAG节点, 然后通过展开的方式一一匹配. 如图2中我们将DAG中每个操作节点分割开来, 然后一一匹配到对应的机器指令.
但是这种方式带来的效率的问题: 选择的指令不一定是最优的. 如果这个架构又支持了一条MS指令, 其作用是将前两个操作数相乘后再逻辑右移, 宏展开的方式无法选择恰当的指令. 对此我们使用DAG covering的方式, 将DAG划分为一个个子图, 对每个子图做检查, 查看指令的语义是否能匹配子图, 如果可以则替换为机器指令, 否则将子图划分为更小的子图递归检查.
如图3所示, 首先从root节点开始搜索, 根据操作符确定候选的SUB/MS两条指令, 再向下搜索第一个来源mul确定候选的MS指令, 依次类推. 再候选过程中可能存在一个DAG对应多个子图划分的情况(比如上文也可以划分为mul一个子图和另一个子图add + sub, 如果架构支持一个指令将add的结果减去另一个值), 在权衡不同划分的优劣时可以使用动态规划来求解.
更进一步的研究建议阅读Survey on Instruction Selection第四章, 本文将聚焦于LLVM的实现.
LLVM的实现与上文描述中稍微有些区别:
LLVM使用tablegen处理td中描述的pattern, 将其分类并设定优先级, 其结果转化成一段特殊格式的数组(也被称作匹配表). 我们截取一段RISCV的匹配表作为例子来解释其含义与构成.
static const unsigned char MatcherTable[] = {
/* 0*/ OPC_SwitchOpcode /*81 cases */, 12|128,5/*652*/, TARGET_VAL(ISD::AND),// ->657
/* 5*/ OPC_Scope, 41|128,4/*553*/, /*->561*/ // 2 children in Scope
/* 8*/ OPC_CheckAndImm, 127|128,127|128,127|128,127|128,15/*4294967295*/,
/* 14*/ OPC_Scope, 75|128,3/*459*/, /*->476*/ // 2 children in Scope
/* 17*/ OPC_MoveChild0,
/* 18*/ OPC_SwitchOpcode /*2 cases */, 96|128,1/*224*/, TARGET_VAL(RISCVISD::DIVUW),// ->247
/* 23*/ OPC_MoveChild0,
/* 24*/ OPC_Scope, 110, /*->136*/ // 2 children in Scope
/* 26*/ OPC_CheckAndImm, 127|128,127|128,127|128,127|128,15/*4294967295*/,
/* 32*/ OPC_RecordChild0, // #0 = $rs1
/* 33*/ OPC_MoveParent,
/* 34*/ OPC_MoveChild1,
/* 35*/ OPC_Scope, 49, /*->86*/ // 2 children in Scope
/* 37*/ OPC_CheckAndImm, 127|128,127|128,127|128,127|128,15/*4294967295*/,
/* 43*/ OPC_RecordChild0, // #1 = $rs2
/* 44*/ OPC_MoveParent,
/* 45*/ OPC_MoveParent,
/* 46*/ OPC_SwitchType /*2 cases */, 24, MVT::i32,// ->73
/* 49*/ OPC_Scope, 10, /*->61*/ // 2 children in Scope
/* 51*/ OPC_CheckPatternPredicate, 0, // (Subtarget->hasStdExtM()) && (Subtarget->is64Bit()) && (MF->getSubtarget().checkFeatures("-64bit"))
/* 53*/ OPC_MorphNodeTo1, TARGET_VAL(RISCV::DIVU), 0,
MVT::i32, 2/*#Ops*/, 0, 1,
// Src: (and:{ *:[i32] } (riscv_divuw:{ *:[i32] } (and:{ *:[i32] } GPR:{ *:[i32] }:$rs1, 4294967295:{ *:[i32] }), (and:{ *:[i32] } GPR:{ *:[i32] }:$rs2, 4294967295:{ *:[i32] })), 4294967295:{ *:[i32] }) - Complexity = 27
// Dst: (DIVU:{ *:[i32] } GPR:{ *:[i32] }:$rs1, GPR:{ *:[i32] }:$rs2)
/* 61*/ /*Scope*/ 10, /*->72*/
/* 62*/ OPC_CheckPatternPredicate, 1, // (Subtarget->hasStdExtM()) && (Subtarget->is64Bit())
/* 64*/ OPC_MorphNodeTo1, TARGET_VAL(RISCV::DIVU), 0,
MVT::i32, 2/*#Ops*/, 0, 1,
// Src: (and:{ *:[i32] } (riscv_divuw:{ *:[i32] } (and:{ *:[i32] } GPR:{ *:[i32] }:$rs1, 4294967295:{ *:[i32] }), (and:{ *:[i32] } GPR:{ *:[i32] }:$rs2, 4294967295:{ *:[i32] })), 4294967295:{ *:[i32] }) - Complexity = 27
// Dst: (DIVU:{ *:[i32] } GPR:{ *:[i32] }:$rs1, GPR:{ *:[i32] }:$rs2)
/* 72*/ 0, /*End of Scope*/
......
};
首先注意到这个表是以unsigned char型数组方式编码的, 每行起始的注释指示行首元素在数组中的下标, 方便我们快速查找.
每行行首的元素是以OPC_起始的枚举值(其值见SelectionDAGISel::BuiltinOpcodes定义), 指示了匹配表要跳转的下一状态. 跟在状态枚举之后的元素的含义由状态机根据当前状态进行解释, 一个状态所需的所有信息均记录在同一行内. 关于状态枚举的具体含义我们结合代码来具体介绍.
行首注释与状态枚举之间的缩进长度指示了该状态的所属的层级. 举例而言对于pattern (add a, (sub b, c)), 检查操作数b的范围与检查操作数c的范围两个状态是平级的, 检查操作数字a的范围肯定优先于检查操作数b的范围(先匹配树的根节点, 再叶子节点). 利用缩进可以图形化阅读状态跳转表.
表中有些特殊的立即数编码, 比如第一行中的下标1和下标2元素(12|128,5/652/). 这么编码的原因是因为这个表是unsigned char型数组, 而许多枚举/下标/立即数范围大于1个byte的大小, 因此需要变长编码(使用定长编码数组会大大增加表的大小, 以X86为例当前大小为500K, 如果使用int数组需要2M空间). 变长编码的方式是取最高位指示是否需要读入后一字节, 即12|128,5的编码值为(12 + 5 << 7 = 652), 正好等于注释里的值. 其解码接口见GetVBR()(defined in lib/CodeGen/SelectionDAG/SelectionDAGISel.cpp).
LLVM_ATTRIBUTE_ALWAYS_INLINE static inline uint64_t
GetVBR(uint64_t Val, const unsigned char *MatcherTable, unsigned &Idx) {
assert(Val >= 128 && "Not a VBR");
Val &= 127; // Remove first vbr bit.
unsigned Shift = 7;
uint64_t NextBits;
do {
NextBits = MatcherTable[Idx++];
Val |= (NextBits&127) << Shift;
Shift += 7;
} while (NextBits & 128);
return Val;
}
我们先回到SelectCodeCommon(), 它接受三个参数, 依次是将被选择的节点, 根据tablegen生成的匹配表, 以及匹配表长度, 如果匹配成功则替换NodeToMatch, 否则调用CannotYetSelect()报错退出. 代码分为两个部分, 第一部分是准备阶段, 判断节点的属性, 加载匹配表, 第二部分是匹配阶段, 根据载入的匹配表进行匹配.
void SelectionDAGISel::SelectCodeCommon(SDNode *NodeToMatch,
const unsigned char *MatcherTable,
unsigned TableSize) {
switch (NodeToMatch->getOpcode()) {
default:
break;
case ISD::EntryToken:
case ISD::BasicBlock:
case ISD::Register:
case ISD::RegisterMask:
case ISD::TargetConstant:
case ISD::TargetConstantFP:
case ISD::TargetConstantPool:
case ISD::TargetFrameIndex:
case ISD::TargetExternalSymbol:
case ISD::MCSymbol:
NodeToMatch->setNodeId(-1);
return;
......
}
SmallVector<SDValue, 8> NodeStack;
SDValue N = SDValue(NodeToMatch, 0);
NodeStack.push_back(N);
// 记录当前匹配的pattern对应匹配表的位置, 如果当前匹配失败则从对应位置继续
SmallVector<MatchScope, 8> MatchScopes;
// 记录已被匹配的节点及其对应的父节点, 根节点的父节点为空
SmallVector<std::pair<SDValue, SDNode*>, 8> RecordedNodes;
// 记录已匹配的pattern的memory信息
SmallVector<MachineMemOperand*, 2> MatchedMemRefs;
// 记录当前的chain与glue依赖信息
SDValue InputChain, InputGlue;
// 记录被匹配的pattern的chain信息
SmallVector<SDNode*, 3> ChainNodesMatched;
// 记录当前所在匹配表的位置
unsigned MatcherIndex = 0;
if (!OpcodeOffset.empty()) {
// OpcodeOffset非空, 即已经加载过整张匹配表
if (N.getOpcode() < OpcodeOffset.size())
MatcherIndex = OpcodeOffset[N.getOpcode()];
} else if (MatcherTable[0] == OPC_SwitchOpcode) {
// 第一次匹配, 从头读入匹配表
unsigned Idx = 1;
while (true) {
// CaseSize等于根节点为该Opc的pattern对应的匹配表的长度
unsigned CaseSize = MatcherTable[Idx++];
if (CaseSize & 128)
CaseSize = GetVBR(CaseSize, MatcherTable, Idx);
// 长度为0表示查找到达表的末尾
if (CaseSize == 0) break;
uint16_t Opc = MatcherTable[Idx++];
Opc |= (unsigned short)MatcherTable[Idx++] << 8;
if (Opc >= OpcodeOffset.size())
OpcodeOffset.resize((Opc+1)*2);
OpcodeOffset[Opc] = Idx;
Idx += CaseSize;
}
// 如果找到对应的opcode则设置下标到起始位置
if (N.getOpcode() < OpcodeOffset.size())
MatcherIndex = OpcodeOffset[N.getOpcode()];
}
while (true) {
BuiltinOpcodes Opcode = (BuiltinOpcodes)MatcherTable[MatcherIndex++];
// 状态机处理
switch (Opcode) {
......
}
// 匹配成功时switch会直接continue
// 匹配失败时才会到此处, 尝试回溯之前的匹配
// 方式是首先检查当前scope的下一元素, 直到遍历所有child
// 如果仍然失败再回溯该scope的父节点
++NumDAGIselRetries;
while (true) {
// scope栈为空, 匹配失败
if (MatchScopes.empty()) {
CannotYetSelect(NodeToMatch);
return;
}
// 回溯最近的scope
MatchScope &LastScope = MatchScopes.back();
RecordedNodes.resize(LastScope.NumRecordedNodes);
NodeStack.clear();
NodeStack.append(LastScope.NodeStack.begin(), LastScope.NodeStack.end());
N = NodeStack.back();
if (LastScope.NumMatchedMemRefs != MatchedMemRefs.size())
MatchedMemRefs.resize(LastScope.NumMatchedMemRefs);
MatcherIndex = LastScope.FailIndex;
InputChain = LastScope.InputChain;
InputGlue = LastScope.InputGlue;
if (!LastScope.HasChainNodesMatched)
ChainNodesMatched.clear();
// 检查该scope的长度, 为0代表是该scope中最后一个pattern
unsigned NumToSkip = MatcherTable[MatcherIndex++];
if (NumToSkip & 128)
NumToSkip = GetVBR(NumToSkip, MatcherTable, MatcherIndex);
if (NumToSkip != 0) {
LastScope.FailIndex = MatcherIndex+NumToSkip;
break;
}
// 该scope中所有匹配失败, 回溯父节点
MatchScopes.pop_back();
}
}
}
第一步首先判断节点类型决定是否选择机器指令.
以上这些指令(除第一类外)会直接设置NodeId为-1表明已被选择.
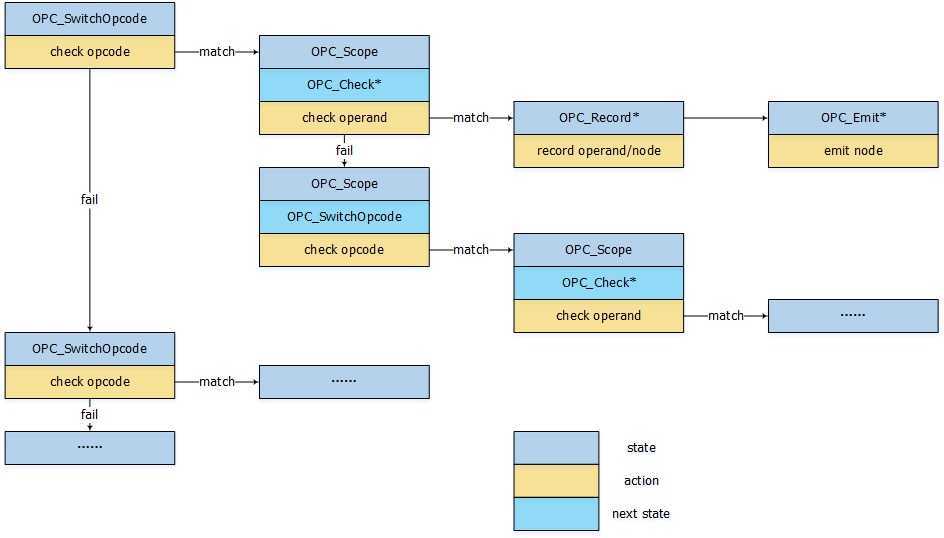
第二步加载匹配表, 从上文介绍可以看到匹配表是一个非常大的数组, 为加速索引SelectionDAGISel类使用一个vector容器OpcodeOffset来缓存不同pattern的根节点在匹配表中的起始位置, 其下标为根节点Opcode的枚举值. 利用这个缓存可以线性查找根节点的匹配.
在第一次调用SelectCodeCommon()时OpcodeOffset为空, 走else分支从头加载匹配表, OPC_SwitchOpcode指示匹配表当前位置用来检查Opcode. 以上文RISCV的匹配表为例, 匹配表第一个元素即OPC_SwitchOpcode, 其后的注释/81 cases/代表与其同级的OPC_SwitchOpcode共有81个(即按根节点的Opcode来分类共有81种分类)(X86是428类). OPC_SwitchOpcode之后跟随的两个元素分别是casesize与opcode, 后者为这个OPC_SwitchOpcode对应的根节点的opcode, 前者为OPC_SwitchOpcode的管理范围(根节点为opcode的pattern在匹配表里的长度), 用来指示当opcode匹配失败时需要跳转到下一个OPC_SwitchOpcode的数组下标.
通常情况下一条指令可能对应多个pattern, 一个DAG Node也可能对应多条指令, 比如(and reg, imm)与(and reg, reg)一定对应不同指令, 考虑到一些复杂pattern比如(and (mul reg, reg), imm)或者(and reg, (shl reg, imm)), 如果一一比较效率较低. 一个办法是根据匹配的条件对这些pattern分类, 形成树状的结构来快速索引pattern, OPC_Scope的作用就是分类匹配条件. 假定我们当前匹配的是and节点, 接下来读取的第一个OPC_Scope指示当前需要检查一个匹配条件, 紧跟在它后面的值指示该scope的长度(即条件判断失败时下一个判断条件的位置, 该值为41|128,4/553/), 再后面是OPC_CheckAndImm, 指示该scope中的pattern需要满足输入的节点的第二个操作数为立即数的条件.
case OPC_Scope: {
// 顺序查找当前scope中满足条件的匹配
// 只有在找到一个匹配后再将其加入MatchScopes中
unsigned FailIndex;
while (true) {
// 获取该scope的长度(匹配失败时跳转到下一scope的数组下标)
unsigned NumToSkip = MatcherTable[MatcherIndex++];
if (NumToSkip & 128)
NumToSkip = GetVBR(NumToSkip, MatcherTable, MatcherIndex);
// 长度为0表明到达该scope的末尾
if (NumToSkip == 0) {
FailIndex = 0;
break;
}
FailIndex = MatcherIndex+NumToSkip;
unsigned MatcherIndexOfPredicate = MatcherIndex;
// 判断是否匹配
bool Result;
MatcherIndex = IsPredicateKnownToFail(MatcherTable, MatcherIndex, N,
Result, *this, RecordedNodes);
// 成功则跳出循环
if (!Result)
break;
++NumDAGIselRetries;
// 否则检查下一scope
MatcherIndex = FailIndex;
}
// If the whole scope failed to match, bail.
if (FailIndex == 0) break;
// 记录当前scope的位置, 若子节点匹配失败时需要从该位置回溯
MatchScope NewEntry;
NewEntry.FailIndex = FailIndex;
NewEntry.NodeStack.append(NodeStack.begin(), NodeStack.end());
NewEntry.NumRecordedNodes = RecordedNodes.size();
NewEntry.NumMatchedMemRefs = MatchedMemRefs.size();
NewEntry.InputChain = InputChain;
NewEntry.InputGlue = InputGlue;
NewEntry.HasChainNodesMatched = !ChainNodesMatched.empty();
MatchScopes.push_back(NewEntry);
continue;
}
由于匹配表是顺序查找的, 一开始匹配到的pattern不一定是最终的pattern, 因此我们需要记录每次匹配的位置, 当匹配失败时可以从对应的位置重新开始匹配, 这个信息存放在MatchScopes中.
回到SelectCodeCommon(), 匹配成功时switch会continue跳过剩余代码. 而匹配失败时会检查MatchScopes是否非空, 若非空则取出最后一个节点重新开始匹配. 如果scope对应的所有元素都匹配失败则返回父节点重新开始匹配, 直到匹配成功或者MatchScopes为空.
到这匹配表的构成基本上已经解释的七七八八了, 现在我们可以回头看下OPC_*枚举, 其大致分类如下.
遗留问题:
原文:https://www.cnblogs.com/Five100Miles/p/12903057.html