Elasticsearch 是一款分布式全文检索框架,底层基于基于Lucene实现。
Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单元。
文档会被序列化为 JSON 格式,保存在 Elasticsearch 中。
每个文档都有一个 Unique ID
? 元数据,用于标注文档的相关信息。
-e node.name=node1 来指定。‘? 集群是多个 Elasticsearch 节点的集合,这些节点应对单个节点无法处理的搜索需求和数据存储需求。
? 集群同时也是对于部分机器(节点)运行中断或者升级导致无法提供服务这一问题的利器。
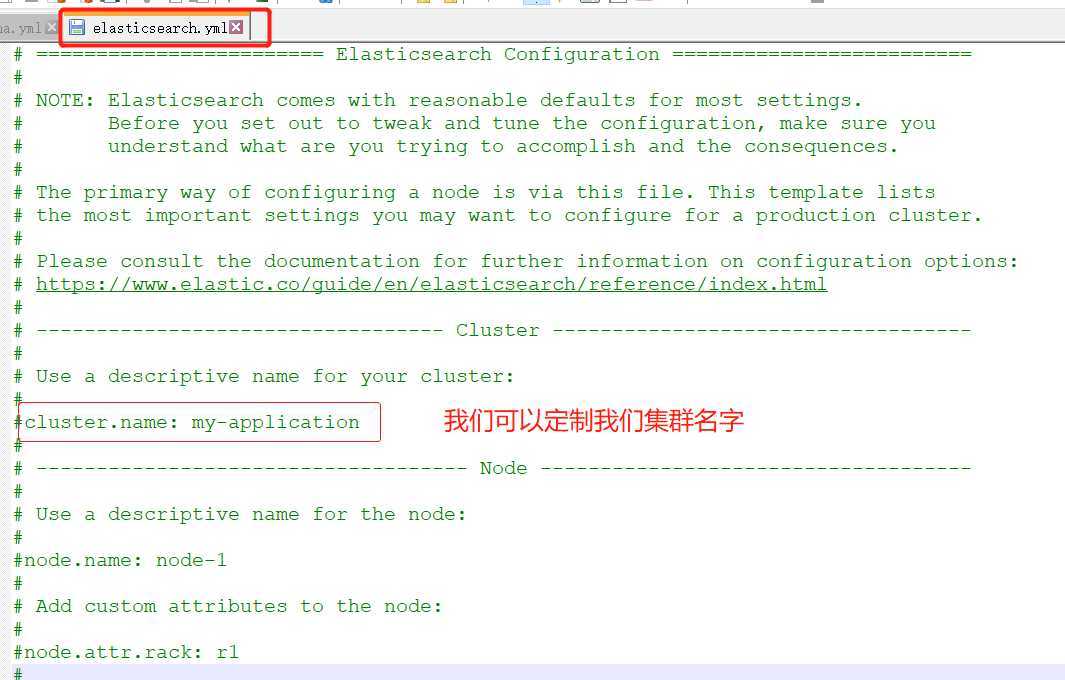
? 我们可以在config/elasticsearch.yml里定制我们的集群的名字:
4、查看集群的健康情况
GET _cluster/health
通过上面的命令来获取整个集群的状态。这个状态只能被 master node 所改变。
es 通过三种颜色来表明集群的建康程度
| 传统数据库 | Elasticsearch |
|---|---|
| Database(数据库) | Index |
| Row(行) | Document |
| Column(字段) | Field |
| SQL | Query DSL |
| SELECT * from table.. | GET http://... |
| UPDATE table set ... | PUT http://... |
Elastchsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),
每个类型下面又包含多个文档(行),每个文档中包含多字段(列);
Elasticsearch在后台默认会把每个索引划成多个分片,每个分片可以在集群不同服务器之间进行迁移。
原文:https://www.cnblogs.com/leizzige/p/12951598.html