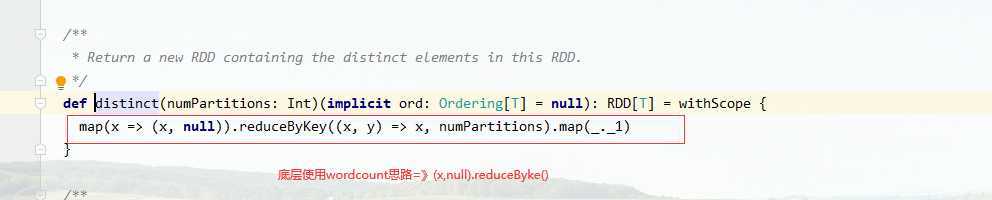
distinct的底层使用reducebykey巧妙实现去重逻辑
//使用reduceByKey或者groupbykey的shuffle去重思想rdd.map(key=>(key,null)).reduceByKey((key,value)=>key) .map(_._1)
spark:distinct算子实现原理
原文:https://www.cnblogs.com/hejunhong/p/12906280.html