一、访问网站20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度
url: https://www.so.com/ #360搜索
1 import requests 2 for i in range(20): 3 r = requests.get("https://www.so.com/") 4 print("网页返回状态:{}".format(r.status_code)) 5 print("text内容为:{}".format(r.text)) 6 print("\n") 7 print("text内容长度为:{}".format(len(r.text))) 8 print("content内容长度为:{}".format(len(r.content)))
输出结果如下:
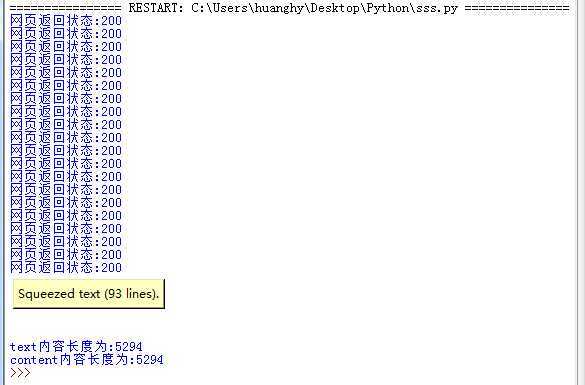
注:Text文本过长这里折叠收缩了
第一步本地建立一个html文件
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runboo.com) 26 </title>
</head>
<body>
<h1>我的第一个标题</h1>
<p id="first">我的第一个段落。</p>
</body>
<table border="1">
<tr>
<td>row 1,cell 1</td>
<td>row 1,cell 2</td>
</tr>
<tr>
<td>row 2,cell 1</td>
<td>row 2,cell 2</td>
</tr>
</table>
</html>
要求:
a打印head标签内容和你的学号后两位
b, 获取body标签的内容
c.获取id为first的标签对象
d.获取并打印html页面中的中文字符
对应代码如下
1 from bs4 import BeautifulSoup 2 import re 3 path = ‘C:/Users/huanghy/Desktop/code.html‘ 4 htmlfile = open(path, ‘r‘, encoding=‘utf-8‘) 5 htmlhandle = htmlfile.read() 6 soup=BeautifulSoup(htmlhandle, "html.parser") 7 print(soup.head,"48") 8 print(soup.body) 9 print(soup.find_all(id="first")) 10 r=soup.text 11 pattern = re.findall(‘[\u4e00-\u9fa5]+‘,r) 12 print(pattern)
输出结果如下:
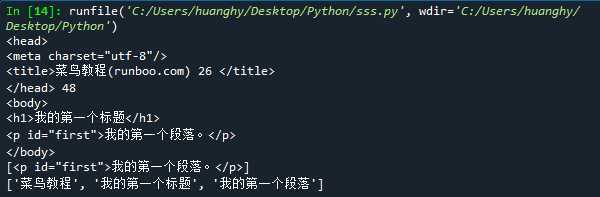
要求: a打印head标签内容和你的学号后两位b,获取body标签的内容c.获取id 为first的标签对象d.获取并打印html页面中的中文字符
原文:https://www.cnblogs.com/serene-zou/p/12883373.html