What is Hadoop
- 官方文档
The Apache? Hadoop? project develops open-source software for reliable, scalable, distributed computing.
- 释义
Apache?Hadoop?项目开发用于可靠、可伸缩的分布式计算的开源软件。
- 广义
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop起源
- Lucene框架是Doug Cutting开创的开源软件,用Java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎。
- 2001年年底Lucene成为Apache基金会的一个子项目。
- 对于海量数据的场景,Lucene面对与Google同样的困难,存储数据困难,检索速度慢。
- 可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
# Google三篇论文
GFS --->HDFS
Map-Reduce --->MR
BigTable --->HBase
- 2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
- 2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
- 2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入到 Hadoop 项目中,Hadoop就此正式诞生,标志着大数据时代来临,而名字来源于Doug Cutting儿子的玩具大象。
Hadoop三大发行版本
Hadoop优势
- 高可靠性
Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性
能够自动将失败的任务重新分配。
Hadoop组成
- HDFS
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)
- MapRedurce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
- Yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
应用场景
Hadoop生态架构图
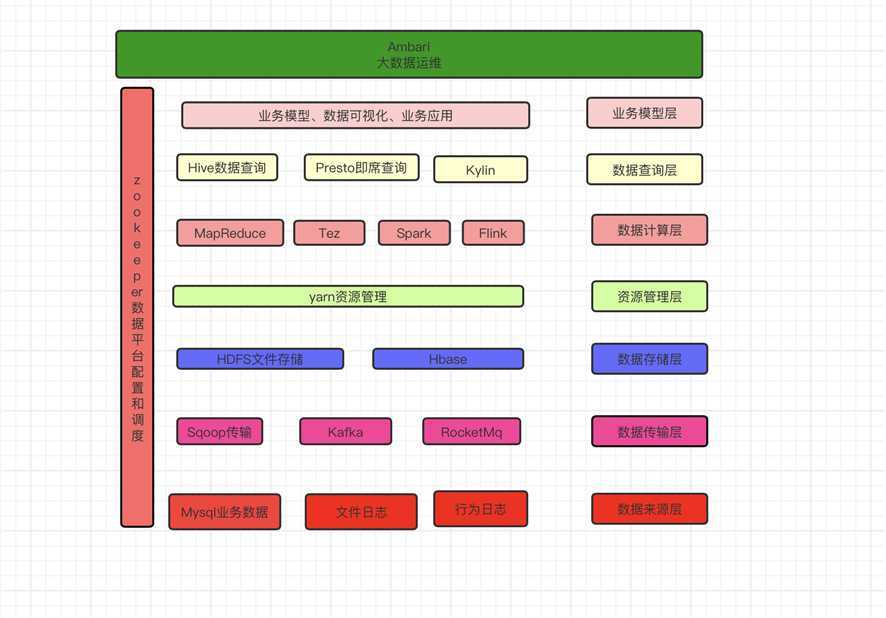
大数据生态hadoop(1):起源
原文:https://www.cnblogs.com/jiejiaobuleng/p/12835244.html