Distributional Hypothesis是说,上下文环境相似的两个词有着相近的语义。word2vec算法也是基于Distributional的假设。
语言模型:在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
word2vec:将词语从高维稀疏向量表示转为低维稠密向量,word2vec是用一个一层的神经网络(即CBOW)把one-hot形式的稀疏词向量映射称为一个n维(n一般为几百)的稠密向量的过程。为了加快模型训练速度,其中的tricks包括Hierarchical softmax,negative sampling, Huffman Tree等。
Word2vec目的:它的最终目的,不是要把语言模型f训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量
上面我们提到了语言模型
如果将Skip-gram模型的前向计算过程写成数学形式,我们得到:
其中,????是Embedding层矩阵里的列向量,也被称为????的input vector。????是softmax层矩阵里的行向量,也被称为????的output vector。
因此,Skip-gram模型的本质是计算输入word的input vector与目标word的output vector之间的余弦相似度,并进行softmax归一化。我们要学习的模型参数正是这两类词向量。
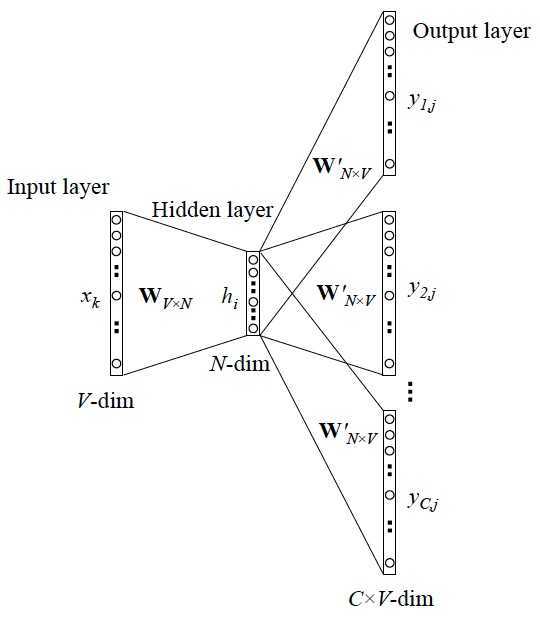
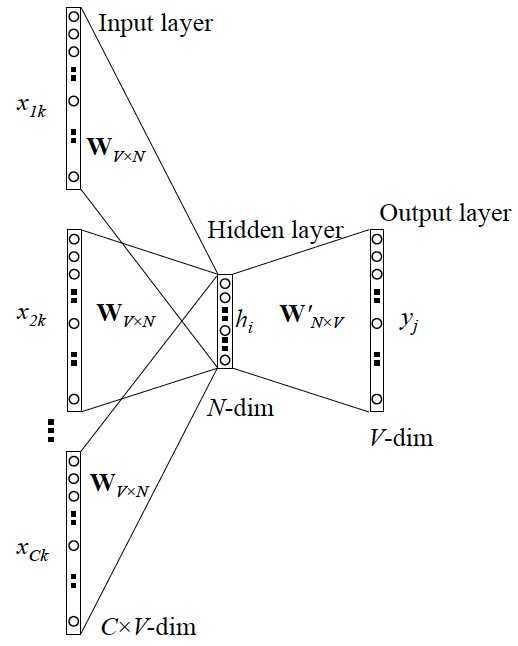
为什么要用训练技巧呢? 如我们刚提到的,Word2vec 本质上是一个语言模型,它的输出节点数是 V 个,对应了 V 个词语,本质上是一个多分类问题,但实际当中,词语的个数非常非常多,会给计算造成很大困难,所以需要用技巧来加速训练。
这里我总结了一下这两个 trick 的本质,有助于大家更好地理解,在此也不做过多展开,有兴趣的同学可以深入阅读参考资料1.~7.
hierarchical softmax
层次softmax,本质是把 N 分类问题变成 log(N)次二分类。层次Softmax是一个很巧妙的模型。它通过构造一颗二叉树,我们就将原始大小为V的字典D转换成了一颗深度为logV的二叉树。树的叶子节点与原始字典里的word一一对应,将目标概率的计算复杂度从最初的V降低到了logV 的量级。不过付出的代价是人为增强了词与词之间的耦合性。例如,一个word出现的条件概率的变化,会影响到其路径上所有非叶节点的概率变化,间接地对其他word出现的条件概率带来不同程度的影响。因此,构造一颗有意义的二叉树就显得十分重要。实践证明,在实际的应用中,基于Huffman编码的二叉树可以满足大部分应用场景的需求。
参考链接:https://blog.csdn.net/bitcarmanlee/article/details/82291968
https://zhuanlan.zhihu.com/p/26306795
https://www.cnblogs.com/guoyaohua/p/9240336.html
原文:https://www.cnblogs.com/ditingz/p/12818276.html