发现一个很有意思的网站,http://www.pythonchallenge.com/
网战每一关,都是一张图片及一段提示,根据这两个内容,获得下一题的url链接。现挑战过程记录如下:
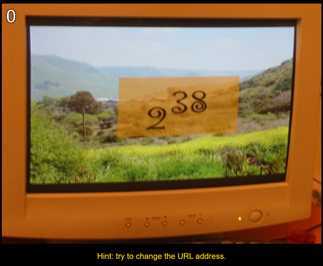
根据提示,结合图片,将URL地址http://www.pythonchallenge.com/pc/def/0.html进行更改,改成http://www.pythonchallenge.com/pc/def/238.html,得到
根据提示回到图片,发现应当输入238的值,即274877906944,网址应修改为http://www.pythonchallenge.com/pc/def/274877906944.html,回车后,自动跳转至http://www.pythonchallenge.com/pc/def/map.html,即第1题的地址。
通过观察图片,我们可以看到(好吧,其实我本来就知道这个内容),这是凯撒加密。K->M,O->Q,E->G,显然偏移为2位,对下方的紫色文字,一看就是要让我们根据这个规则进行转换,写个简单的小程序,转换之。
def f1():
d1 = {‘a‘: ‘c‘, ‘b‘: ‘d‘, ‘c‘: ‘e‘, ‘d‘: ‘f‘, ‘e‘: ‘g‘, ‘f‘: ‘h‘, ‘g‘: ‘i‘, ‘h‘: ‘j‘, ‘i‘: ‘k‘, ‘j‘: ‘l‘, ‘k‘: ‘m‘, ‘l‘: ‘n‘, ‘m‘: ‘o‘,
‘n‘: ‘p‘, ‘o‘: ‘q‘, ‘p‘: ‘r‘, ‘q‘: ‘s‘, ‘r‘: ‘t‘, ‘s‘: ‘u‘, ‘t‘: ‘v‘, ‘u‘: ‘w‘, ‘v‘: ‘x‘, ‘w‘: ‘y‘, ‘x‘: ‘z‘, ‘y‘: ‘a‘, ‘z‘: ‘b‘}
s = """g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr‘q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj."""
for c in s:
if d1.get(c, ‘0‘) != ‘0‘:
print(d1[c], end=‘‘)
else:
print(c, end=‘‘)
可以得到
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that‘s why this text is so long. using string.maketrans() is recommended. now apply on the url.
这句话,好像没啥用,把里面的"maketrans",改到地址里,得到一个
感觉被嘲讽了一下。
这里体现了我英语水平一般的情况??,实际上,它这里提供了一个方法,string.maketrans(),(python3.4以后,就没有这个方法了,改成了str.maketrans())。详细用法,在这里https://www.runoob.com/python3/python3-string-maketrans.html,上面代码里面的for语句,可以用以下一句话代替。
print(s.translate(str.maketrans(d1)))
而且,最关键的是,要进入下一题,apply on the url,就是把原来的地址,按这个规则转换一下,即map->ocr,得到第2关的地址http://www.pythonchallenge.com/pc/def/ocr.html
一本看不清的书,肯定没啥用。
下面的话,识别文字,可能在书里,也可能在页面源里,加粗的可能,就是一定啊!
F12,查看页面源代码,
关键字,find rare characters in the mess below,在这堆乱七八糟里面找到稀有的字符,显然需要对那“坨”东西进行统计。上代码。
def f2():
d2 = {}
with open("f2.txt") as f:
for line in f:
for c in line:
d2[c] = d2.get(c, 0) + 1
for c, k in d2.items():
print(c, ":", k)
得到结果
% : 6104
$ : 6046
@ : 6157
_ : 6112
^ : 6030
# : 6115
) : 6186
& : 6043
! : 6079
+ : 6066
] : 6152
* : 6034
} : 6105
[ : 6108
( : 6154
{ : 6046
: 1219
e : 1
q : 1
u : 1
a : 1
l : 1
i : 1
t : 1
y : 1
这就一下子看懂了,rare characters是equality,将url修改一下,就可以得到第3题的链接http://www.pythonchallenge.com/pc/def/equality.html
找到一个小字母,它每一个每个方向上的大字母都是三个。
图片显示的只是这句话的字面解释,既然有了上一题的经验,那就还是查询页面源代码。
果然是这个套路。
遍历所有的字母,进行相应判断。这里虽然看着像个矩阵,但确实不需要当成矩阵来解,不过,当成矩阵来解是比较严谨的,当然下面的解法是当成一行一行的字符串来解的,当成矩阵的有兴趣的可以自己搞一下。
def f3():
s1 = set([‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘, ‘h‘, ‘i‘, ‘j‘, ‘k‘, ‘l‘,
‘m‘, ‘n‘, ‘o‘, ‘p‘, ‘q‘, ‘r‘, ‘s‘, ‘t‘, ‘u‘, ‘v‘, ‘w‘, ‘x‘, ‘y‘, ‘z‘])
s2 = set([‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘, ‘F‘, ‘G‘, ‘H‘, ‘I‘, ‘J‘, ‘K‘, ‘L‘,
‘M‘, ‘N‘, ‘O‘, ‘P‘, ‘Q‘, ‘R‘, ‘S‘, ‘T‘, ‘U‘, ‘V‘, ‘W‘, ‘X‘, ‘Y‘, ‘Z‘])
with open("f3.txt") as f:
for line in f:
for i in range(3, len(line) - 3):
if line[i] in s1:#当前是小写
if line[i - 1] in s2 and line[i - 2] in s2 and line[i - 3] in s2:#前3个是大写
if line[i + 1] in s2 and line[i + 2] in s2 and line[i + 3] in s2:#后3个是大写
if i > 3 and line[i - 4] not in s2:#往前第4个不是大写
if i < len(line)-3 and line[i+4] not in s2:#往后第4个不是大写
print(line[i], end=‘‘)
可以得到结果是linkedlist,将URL修改成http://www.pythonchallenge.com/pc/def/linkedlist.html
根据提示进一步修改为http://www.pythonchallenge.com/pc/def/linkedlist.php,正确了。
一张莫名奇妙的图,先看一下源码,
<html>
<head>
<title>follow the chain</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<!-- urllib may help. DON‘T TRY ALL NOTHINGS, since it will never
end. 400 times is more than enough. -->
<center>
<a href="linkedlist.php?nothing=12345"><img src="chainsaw.jpg" border="0"/></a>
<br><br><font color="gold"></center>
Solutions to previous levels: <a href="http://wiki.pythonchallenge.com/"/>Python Challenge wiki</a>.
<br><br>
IRC: irc.freenode.net #pythonchallenge
</body>
</html>
可以发现有一行注释,但是看不懂什么鬼!!不过可以注意到有个标签,显然有个链接,返回页面后发现,图片是可以点的。
点进图片,得到这个内容,观察这里的url地址,有一个nothing=12345,页面中有一个next nothing is 44827,那我们就大胆的试一下
好像是正确的方向,再来一次
基本可以判断这是个正确的方向了,这里的标红提示,显然是告诉我们不要再手动了,联系上面源码中的注释,400 times is more than enough,来,上代码。这里其实实现的就是一个超级简易的爬虫。
def f4():
import requests
from bs4 import BeautifulSoup
start_url = ‘http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=‘
nextlink = ‘12345‘#这里会需要改一次
while True:
url = start_url + nextlink
html = getHTMLText(url)
soup = BeautifulSoup(html)
s = soup.text
print(s)
if s.find(‘next nothing is ‘) != 0:
nextlink = s[s.find(‘next nothing is ‘) +
len(‘next nothing is ‘):]
else:
break
运行到一定时候,会出现一条提示“Yes. Divide by two and keep going.”。于是我们需要,把16044除以2,得到8022,再来一次。
运行到一定时候,出现了一条提示“There maybe misleading numbers in the
text. One example is 82683. Look only for the next nothing and the next nothing is 63579”,表示页面中可能有别的数字并不是代表next nothing,不过我们的程序一开始就锁定了next nothing,这里不影响,继续。
很快,我们就得到了这个,修改url,http://www.pythonchallenge.com/pc/def/peak.html,解决了。
同样,先查源代码
<html>
<head>
<title>peak hell</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<center>
<img src="peakhell.jpg"/>
<br><font color="#c0c0ff">
pronounce it
<br>
<peakhell src="banner.p"/>
</body>
</html>
<!-- peak hell sounds familiar ? -->
老实讲,这个我没看懂,在网上看了一下别人做的解答,原来是peak hell,和python库pickle谐音(这种冷幽默,对英语和python库的熟悉程度要求都比较高,有点难)。之前没接触过pickle库的,可以在这里学习一下,我也是现学的。
这里是要求用pickle库对“banner.p"这个文件进行处理,提取出有意义的数据,就可以得到下一题的链接。
def f5():
import pickle
with open("banner_convert.p", ‘rb‘) as f:
data1 = pickle.load(f)
with open("output.txt", ‘w‘) as f:
for d in data1:
for a, b in d:
for i in range(b):
print(a, end=‘‘)
print()
可以得到这个
不得不说,老外真会玩!
这里有几个注意的地方,没搞好就搞不出来。
pickle库使用时,就当注意环境,不同操作系统生成的文件是不一样的,有\n和\r\n之分,从网站上下载下来的是带\r\n的,而在使用pickle的过程中,出现了UnpicklingError,所以考虑改成\n,改完后就可以了。使用下面的代码进行转换。
def convert():
original = "banner.p"
destination = "banner_convert.p"
content = ‘‘
outsize = 0
with open(original, ‘rb‘) as infile:
content = infile.read()
with open(destination, ‘wb‘) as output:
for line in content.splitlines():
output.write(line + str.encode(‘\n‘))
用pickle读取文件后,得到了
一看不知道是啥,我们就可以用type(data1),发现是个序列。展开一层,得到
还是看不懂,没事,放到文档里
可以观察到,每行所有数字加起来都是95,我们就可以大胆猜测,这是要我们画画!这就解决了。顺利进入第6题http://www.pythonchallenge.com/pc/def/channel.html
先说结论,这是一道脑洞题!
这个题面,毛都没有,源代码
<html> <!-- <-- zip -->
<head>
<title>now there are pairs</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<center>
<img src="channel.jpg">
<br/>
<!-- The following has nothing to do with the riddle itself. I just
thought it would be the right point to offer you to donate to the
Python Challenge project. Any amount will be greatly appreciated.
-thesamet
-->
<form action="https://www.paypal.com/cgi-bin/webscr" method="post">
<input type="hidden" name="cmd" value="_xclick">
<input type="hidden" name="business" value="thesamet@gmail.com">
<input type="hidden" name="item_name" value="Python Challenge donations">
<input type="hidden" name="no_note" value="1">
<input type="hidden" name="currency_code" value="USD">
<input type="hidden" name="tax" value="0">
<input type="hidden" name="bn" value="PP-DonationsBF">
<input type="image" src="https://www.paypal.com/en_US/i/btn/x-click-but04.gif" border="0" name="submit" alt="Make payments with PayPal - it‘s fast, free and secure!">
<img alt="" border="0" src="https://www.paypal.com/en_US/i/scr/pixel.gif" width="1" height="1">
</form>
</body>
</html>
中间那段要钱的你是认真的吗?
看下来,唯一有意义的应该就是第一个注释里的zip了,改一下url,http://www.pythonchallenge.com/pc/def/zip.html
说实话,我感觉我的智商受到了污辱。。。这题不会了。参考了这篇,原来是要把channel.html改成channel.zip,下载这个zip。下载下来后,发现是一堆txt,有个readme.txt。和之前一样,就是一直找next nothing的数字。可是最后得到一个,collect the comments。一脸懵,又看了一眼答案。原来是要用zipfile库来处理。
关于zipfile库的使用,可以在这里学习一下。
collect the comments,既然是comments我们就考虑是很多个文件的comment,这里可能对很多人来讲是个知识盲区,通常我们可以知道每个压缩包可以有注释,但我们通常不知道,压缩包里的每个文件,都可以有注释(谁没事给文件加注释啊,丢)。
使用ZipFile.getinfo(name)方法可以返回一个ZipInfo对象,表示zip文档中相应文件的信息,属性ZipInfo.comment可以把注释读出来。
上代码
def f6():
import zipfile
nextfile = "90052.txt"
comments = []
z = zipfile.ZipFile(‘channel.zip‘, ‘r‘)
while True:
s = z.read(nextfile)
text = str(s, encoding=‘utf-8‘)#第一个要注意的地方
print(text)
comments.append(z.getinfo(nextfile).comment)
if text.find(‘Next nothing is ‘) >= 0:
nextfile = text[text.find(
‘Next nothing is ‘) + len(‘Next nothing is ‘):]+‘.txt‘
else:
break
for c in comments:
print(str(c, encoding=‘utf-8‘), end=‘‘)#每二个要注意的地方
几个地方注意:
可以得到
用hockey修改url,得到http://www.pythonchallenge.com/pc/def/hockey.html,但是
是的,我想骂人。原来是组成hockey的oxygen(氧气),再次修改,得到http://www.pythonchallenge.com/pc/def/oxygen.html,成功
这是道好题!
题目就一张打了马赛克的图,页面源代码啥也没有,所以肯定是要处理这个马赛克。第一感觉应该是灰度值对应了某一个字母。
我用的是matplotlib,把图片读进来。
根据坐标可以把马赛克提取出来。
将提取出来的值打印出来观察一下。
看不懂,这里卡了很久,尝了对这些值进行去重,发现有29个,显然不只是26个字母,应该还有标点符号,几乎可以推断最黑的那块是空格,可其他的却推不出来。后来才想起来,这里是[0,1]区间的RGB,可以转成[0,256]区间的试试。
去掉小数部分并提取出来。
转成对应的ascii字符。
去重去空格。
好像就是答案了,不过这里要注意到10,16,14,都不是26个字母的ascii码范围。观察未去重前的输出,可以发现这几处的”1“都是14个连续字符,而其他字母都是7个连续字符(除了第1个s外),所以显然应为110,116,114,所以next level的序列是[105,110,116,101,103,114,105,116,121],转换后,为integrity,修改url,得到http://www.pythonchallenge.com/pc/def/integrity.html,成功。
上代码
def f7():
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
mosaic = mpimg.imread(‘./oxygen.png‘)
# plt.imshow(mosaic)
plt.imshow(mosaic[43:52, 0:608])
mo = mosaic[43, 0:608]
for i in range(len(mo)):
f = int(mo[i][0] * 256)
if i == 0:
print(chr(f), end=‘‘)
elif mo[i][0] != mo[i - 1][0]:
print(chr(f), end=‘‘)
print()
mo2 = [105, 110, 116, 101, 103, 114, 105, 116, 121]
for i in mo2:
print(chr(i), end=‘‘)
plt.show()
知识题。
这次一看源代码就知识图中的蜜蜂有个链接,可以输入帐号密码,而下方注释,显然就是帐号和密码!
第一眼,感觉是16进制转成十进制,再转成ascii码,试了一下,得到这个。
虽然看着很扯蛋,但我还是试了一下,果然不行(是的,我真的试了!)
上网找了下答案,原来”BZh91AY&SYA“打头,这是一种特定的编码bzip2(python 里面是bz2库)的固定格式。这就很容易了。
def f8():
import bz2
un = b"""BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084"""
pw = b"""BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08"""
print(bz2.decompress(un).decode("utf-8"))
print(bz2.decompress(pw).decode("utf-8"))
这里是拓展阅读和官方解答,要注意官方解答可以因为版本和系统不同,有些代码不一定能跑起来。
得到答案
这题是图像操作。
一张图,有很多黑点,第一直觉是,处理图上的点。打开页面源,就两个序列,first+second。将图片读入后可以发现first,second两个序列里的数值都不超过图像的大小,所以将里面的数值当作坐标来处理。两个序列长度不一样,所以不可能是一个x轴一个y轴。试了一下first序列内两个一组作为坐标作图,发现有门。
把second也加上。
像牛也像羊。挨个试一下sheep,不对。goat,不对。bull对了!http://www.pythonchallenge.com/pc/return/bull.html
上代码
def f9():
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
first = [146, 399, 163, 403, 170, 393, 169, 391, 166, 386, 170, 381, 170, 371, 170, 355, 169, 346, 167, 335, 170, 329, 170, 320, 170,
310, 171, 301, 173, 290, 178, 289, 182, 287, 188, 286, 190, 286, 192, 291, 194, 296, 195, 305, 194, 307, 191, 312, 190, 316,
190, 321, 192, 331, 193, 338, 196, 341, 197, 346, 199, 352, 198, 360, 197, 366, 197, 373, 196, 380, 197, 383, 196, 387, 192,
389, 191, 392, 190, 396, 189, 400, 194, 401, 201, 402, 208, 403, 213, 402, 216, 401, 219, 397, 219, 393, 216, 390, 215, 385,
215, 379, 213, 373, 213, 365, 212, 360, 210, 353, 210, 347, 212, 338, 213, 329, 214, 319, 215, 311, 215, 306, 216, 296, 218,
290, 221, 283, 225, 282, 233, 284, 238, 287, 243, 290, 250, 291, 255, 294, 261, 293, 265, 291, 271, 291, 273, 289, 278, 287,
279, 285, 281, 280, 284, 278, 284, 276, 287, 277, 289, 283, 291, 286, 294, 291, 296, 295, 299, 300, 301, 304, 304, 320, 305,
327, 306, 332, 307, 341, 306, 349, 303, 354, 301, 364, 301, 371, 297, 375, 292, 384, 291, 386, 302, 393, 324, 391, 333, 387,
328, 375, 329, 367, 329, 353, 330, 341, 331, 328, 336, 319, 338, 310, 341, 304, 341, 285, 341, 278, 343, 269, 344, 262, 346,
259, 346, 251, 349, 259, 349, 264, 349, 273, 349, 280, 349, 288, 349, 295, 349, 298, 354, 293, 356, 286, 354, 279, 352, 268,
352, 257, 351, 249, 350, 234, 351, 211, 352, 197, 354, 185, 353, 171, 351, 154, 348, 147, 342, 137, 339, 132, 330, 122, 327,
120, 314, 116, 304, 117, 293, 118, 284, 118, 281, 122, 275, 128, 265, 129, 257, 131, 244, 133, 239, 134, 228, 136, 221, 137,
214, 138, 209, 135, 201, 132, 192, 130, 184, 131, 175, 129, 170, 131, 159, 134, 157, 134, 160, 130, 170, 125, 176, 114, 176,
102, 173, 103, 172, 108, 171, 111, 163, 115, 156, 116, 149, 117, 142, 116, 136, 115, 129, 115, 124, 115, 120, 115, 115, 117,
113, 120, 109, 122, 102, 122, 100, 121, 95, 121, 89, 115, 87, 110, 82, 109, 84, 118, 89, 123, 93, 129, 100, 130, 108, 132, 110,
133, 110, 136, 107, 138, 105, 140, 95, 138, 86, 141, 79, 149, 77, 155, 81, 162, 90, 165, 97, 167, 99, 171, 109, 171, 107, 161,
111, 156, 113, 170, 115, 185, 118, 208, 117, 223, 121, 239, 128, 251, 133, 259, 136, 266, 139, 276, 143, 290, 148, 310, 151,
332, 155, 348, 156, 353, 153, 366, 149, 379, 147, 394, 146, 399]
second = [156, 141, 165, 135, 169, 131, 176, 130, 187, 134, 191, 140, 191, 146, 186, 150, 179, 155, 175, 157, 168, 157, 163, 157, 159,
157, 158, 164, 159, 175, 159, 181, 157, 191, 154, 197, 153, 205, 153, 210, 152, 212, 147, 215, 146, 218, 143, 220, 132, 220,
125, 217, 119, 209, 116, 196, 115, 185, 114, 172, 114, 167, 112, 161, 109, 165, 107, 170, 99, 171, 97, 167, 89, 164, 81, 162,
77, 155, 81, 148, 87, 140, 96, 138, 105, 141, 110, 136, 111, 126, 113, 129, 118, 117, 128, 114, 137, 115, 146, 114, 155, 115,
158, 121, 157, 128, 156, 134, 157, 136, 156, 136]
first.extend(second)
good = mpimg.imread(‘./good.jpg‘)#读jpg,需要预装pillow库
plt.imshow(good)
for i in range(0, len(first)-1, 2):
plt.plot(first[i], first[i + 1], ‘r*‘)
plt.show()
matplotlib的用法可以参考这里。
找规律。
找不出来??。
一开始以为是斐波那契数列,毕竟和是a=[1,2,3,5,8],2的个数是[0,0,1,1,2],两个序列一减,就是len(a[i]),看着很完美,然而不是出题人的想法。
网上找了一下答案。
感觉很无耻,我就不想多说了,直接上代码。
def f10():
k = 4
a = ‘111221_‘
while k < 30:
pre = ‘‘
count = 0
b = ‘‘
for now in a:
if now != pre:
if pre != ‘‘:
b = b+str(count)+pre
count = 1
pre = now
else:
count = count + 1
a = b+‘_‘
k = k + 1
print(len(a)-1)
答案是5808,url为http://www.pythonchallenge.com/pc/return/5808.html
原文:https://www.cnblogs.com/bigwalker/p/12800771.html