一、一次函数调用分析
c代码:
// function_example.c #include <stdio.h> int static add(int a, int b) { return a+b; } int main() { int x = 5; int y = 10; int u = add(x, y); }
编译并objdump:
$ gcc -g -c function_example.c
$ objdump -d -M intel -S function_example.o
int static add(int a, int b) { 0: 55 push rbp 1: 48 89 e5 mov rbp,rsp 4: 89 7d fc mov DWORD PTR [rbp-0x4],edi 7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi return a+b; a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8] 10: 01 d0 add eax,edx } 12: 5d pop rbp 13: c3 ret 0000000000000014 <main>: int main() { 14: 55 push rbp 15: 48 89 e5 mov rbp,rsp 18: 48 83 ec 10 sub rsp,0x10 int x = 5; 1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5 int y = 10; 23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa int u = add(x, y); 2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8] 2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] 30: 89 d6 mov esi,edx 32: 89 c7 mov edi,eax 34: e8 c7 ff ff ff call 0 <add> 39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax 3c: b8 00 00 00 00 mov eax,0x0 } 41: c9 leave 42: c3 ret
分析:
实际上PUSH指令就表示压栈,POP就表示出栈。其实上述的调用过程和if/else的指令都进行了指令地址跳转,区别在于通过if/else跳转后,指令顺序执行到下一行,而call命令执行的跳转函数完成后还会调回call命令下一行,这是如何实现的呢?
程序栈说明:
我们自己思考这个功能该如何实现呢?
第一种方法,我们可以将add方法的指令直接拼接到main方法指令行的对应位置,这个方法的问题是,假如main方法和add相互调用(循环调用)那么不断拼接无穷无尽,显然不行。
第二种方法,我们可以单独设置一个程序执行寄存器,每次函数执行都记录该函数执行需要返回的位置,这样等该函数执行完成,直接返回到记录的返回位置即可,但是在多级函数调用情况下,只记录一个跳转机制远远不够,因此计算机科学家实际使用了一种更好的办法;
实际栈结构:
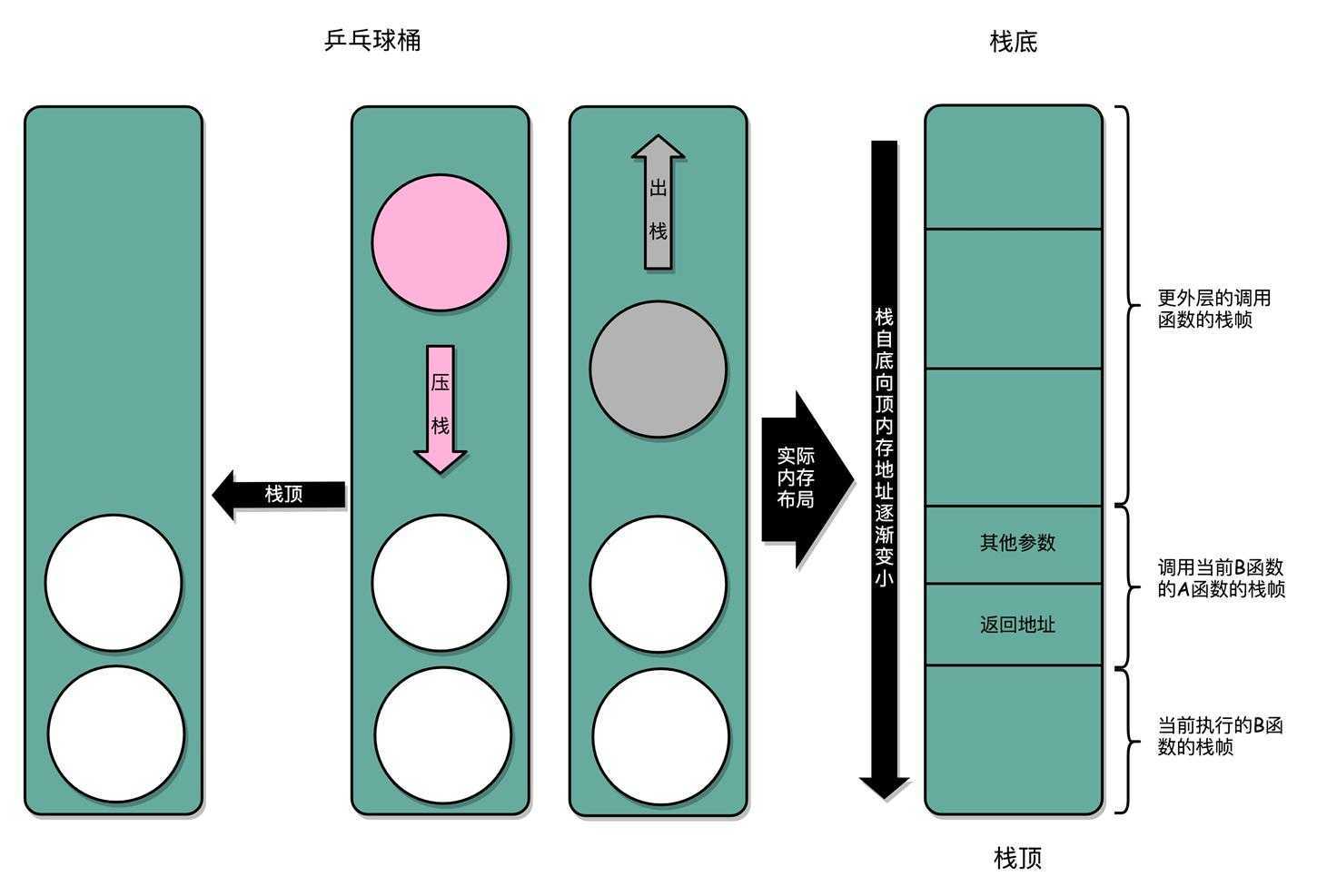
汇编代码的表现:
二、构造一次Stack Overflow
由于栈的大小有限,因此当调用层级太多时,会由于压栈造成栈空间不足以致溢出,典型场景为不加限制的递归调用:
int a() { return a(); } int main() { a(); return 0; }
三、使用函数内联进行性能优化
程序编译时将实际函数调用产生的指令直接插入到调用位置,来替换对应的函数调用指令,称为函数内联。
这样做的好处是:减少了指令数、减少了函数调用时的压栈弹栈开销;
但是当目标函数被引用很多次时会多次展开,使得程序占用空间变得很大。
原文:https://www.cnblogs.com/rxmind/p/12793554.html