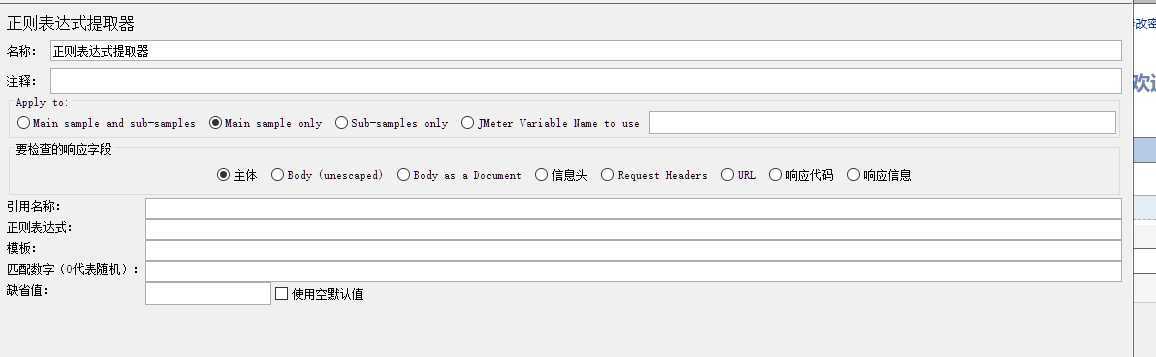
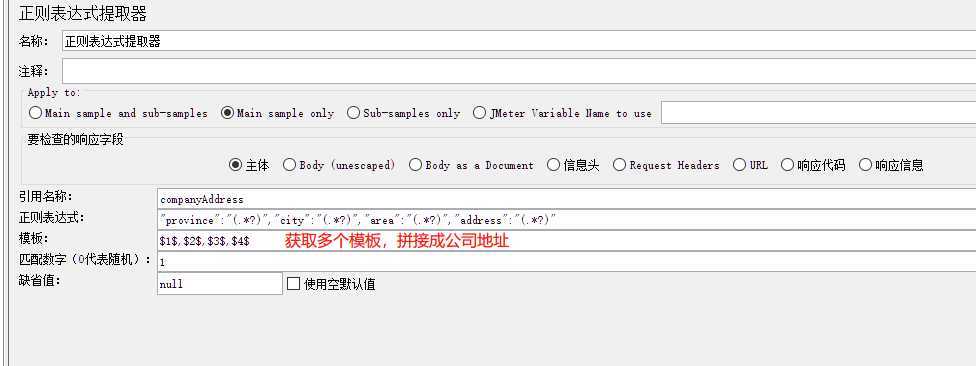
Apply to(应用范围):
Main sample and sub-samples:应用于主sample及子sample
Main sample only:默认的是这个,应用于主sample
Sub-samples only:应用于子sample
JMeter Variable :应用于变量命名的内容
要检查的响应字段:
主体:响应报文的主体,一个网页页面的内容,除了信息头以外的内容 (最常用)
Body(unescaped):主体,响应的主体内容且替换了所有的html转义符,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
Response Headers:响应信息头
Request Headers:请求信息头
URL:统一资源定位符,即Internet上用来描述信息资源的字符串
Response Code:响应状态码,比如200、404等
Response Message:响应信息
引用名称:自定义的参数名称,后续调用使用
正则表达式:()括号里表示你要匹配的数值
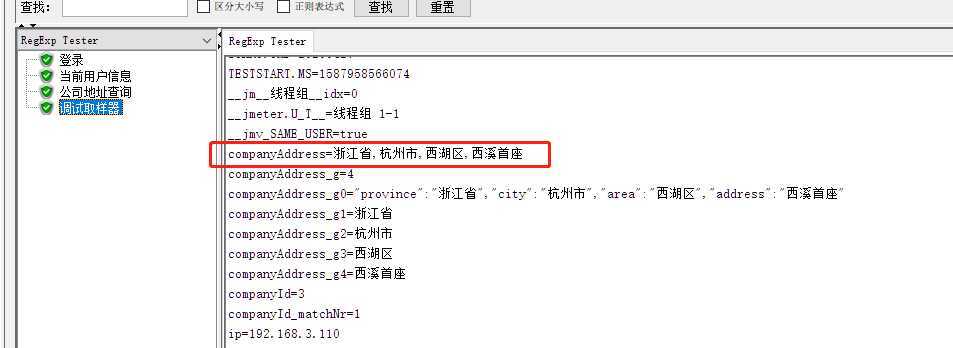
模板:$1$ 引用组1,$2$ 引用组2 $n$引用组n $0$ 引用整个表达式匹配的内容。
匹配数字(0代表随机):-1 匹配所有,0 随机,1 代表匹配第一个,以此类推,n 取匹配的第n个 (不填写时随机取值)
缺省值:无匹配项时给参数默认赋的值
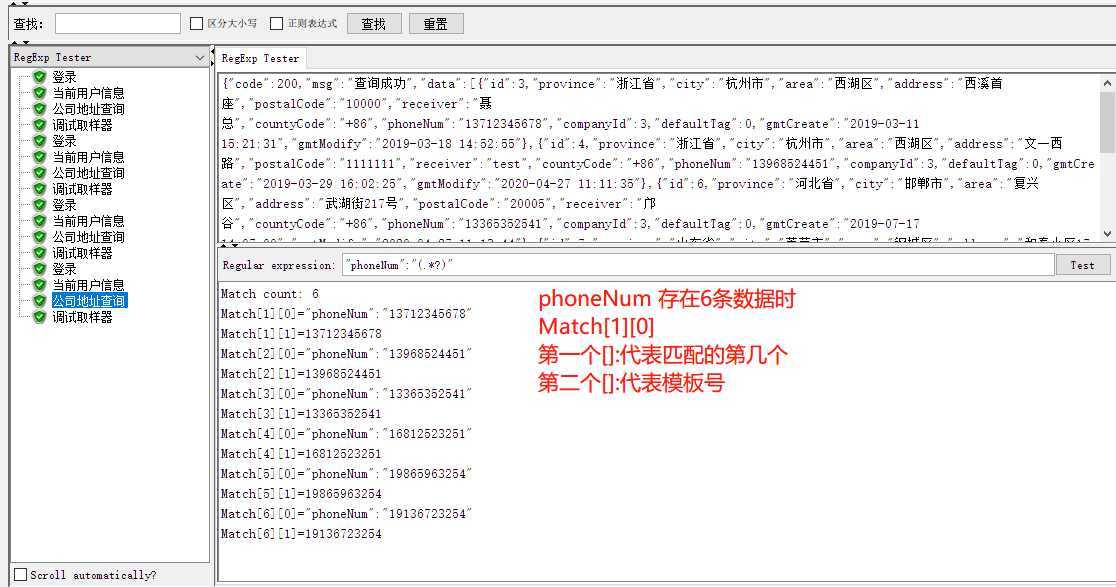
当我们模板传$1$ 匹配数字传4 时 可以匹配到到 phoneNum=16812523251
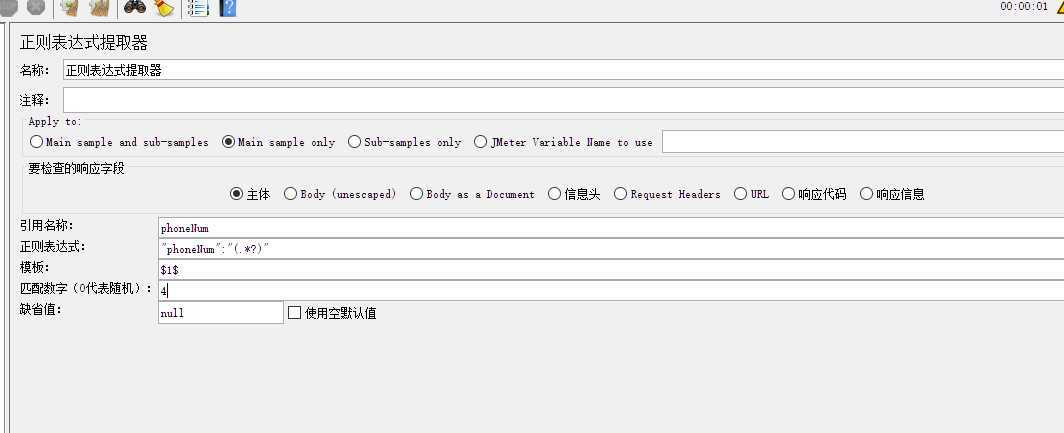
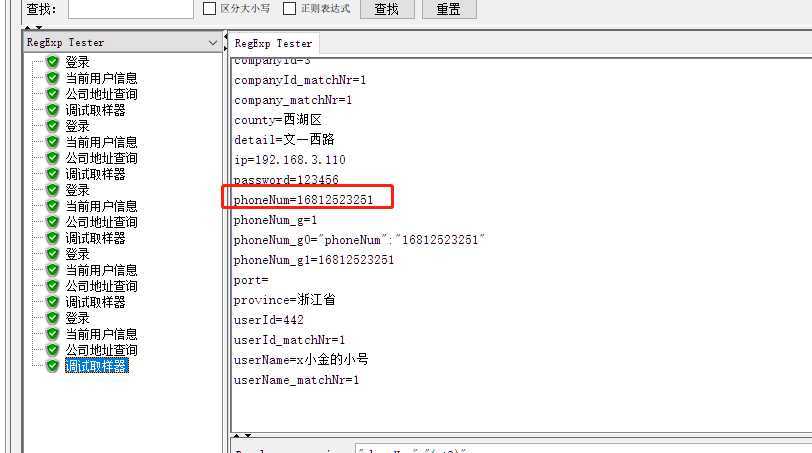
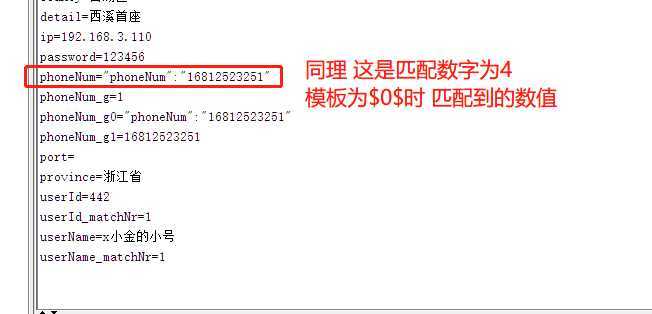
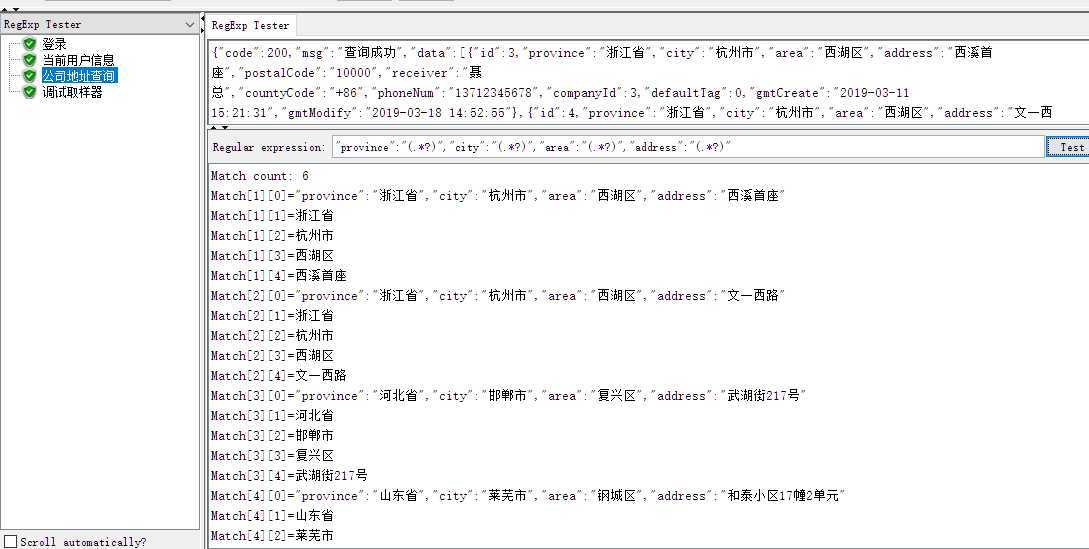
多参数提取 公司地址获取
|
特别字符 |
描述 |
|
$ |
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n‘ 或 ‘\r‘。要匹配 $ 字符本身,请使用 \$。 |
|
( ) |
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
|
* |
匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
|
+ |
匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
|
. |
匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
|
[ |
标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
|
? |
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
|
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n‘ 匹配字符 ‘n‘。‘\n‘ 匹配换行符。序列 ‘\\‘ 匹配 "\",而 ‘\(‘ 则匹配 "("。 |
|
^ |
匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
|
{ |
标记限定符表达式的开始。要匹配 {,请使用 \{。 |
|
| |
指明两项之间的一个选择。要匹配 |,请使用 \|。 |
限定符都是贪婪的,因为它们会尽可能多的匹配文字
*:匹配0次到多次
+:匹配一次到多次
?:匹配0次到一次
{n}:匹配n次(n非负数)
{n,} 至少匹配 n次
{m,n}:至少匹配n次且至多匹配M次
通过在限定符之后放置 ?,该表达式从"贪婪"表达式转换为"非贪婪"表达式或者最小匹配。
原文:https://www.cnblogs.com/Arlene729/p/12785647.html