ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
来自百度百科:https://baike.baidu.com/item/zookeeper/4836397?fr=aladdin
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的执行ID,类似root权限。
5、集群中大多数的机器得到响应并接受选出的Leader。
ZooKeeper很简单。ZooKeeper允许分布式进程通过共享的分层名称空间相互协调,该命名空间的组织方式类似于标准文件系统。名称空间由数据寄存器(在ZooKeeper看来是znode)组成,它们类似于文件和目录。与设计用于存储的典型文件系统不同,ZooKeeper数据保留在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数。
ZooKeeper实施对高性能,高可用性,严格有序访问加以重视。ZooKeeper的性能方面意味着它可以在大型的分布式系统中使用。可靠性方面使它不会成为单点故障。严格排序意味着可以在客户端上实现复杂的同步原语。
ZooKeeper已复制。像它协调的分布式进程一样,ZooKeeper本身也可以在称为集合的一组主机上进行复制。
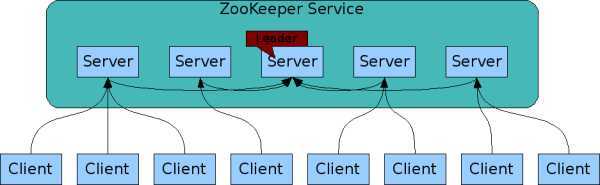
ZooKeeper服务
组成ZooKeeper服务的服务器都必须彼此了解。它们维护内存中的状态图像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper服务将可用。
客户端连接到单个ZooKeeper服务器。客户端维护一个TCP连接,通过它发送请求,获取响应,获取监视事件并发送心跳。如果与服务器的TCP连接断开,则客户端将连接到其他服务器。
ZooKeeper已订购。ZooKeeper用一个反映所有ZooKeeper事务顺序的数字标记每个更新。后续操作可以使用该命令来实现更高级别的抽象,例如同步原语。
ZooKeeper很快。在“读取为主”的工作负载中,它特别快。ZooKeeper应用程序可在数千台计算机上运行,??并且在读取比写入更常见的情况下,其性能最佳,比率约为10:1。
ZooKeeper提供的名称空间与标准文件系统的名称空间非常相似。名称是由斜杠(/)分隔的一系列路径元素。ZooKeeper名称空间中的每个节点都由路径标识。
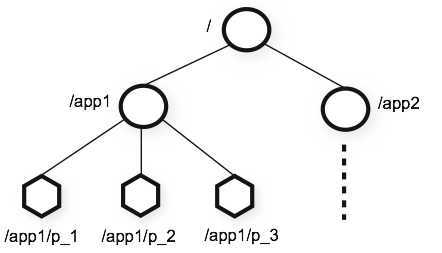
ZooKeeper的层次命名空间
与标准文件系统不同,ZooKeeper命名空间中的每个节点都可以具有与其关联的数据以及子节点。就像拥有一个文件系统一样,该文件系统也允许文件成为目录。(ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点上的数据通常很小,在字节到千字节范围内。)我们使用术语znode来明确表示在谈论ZooKeeper数据节点。
Znodes维护一个统计信息结构,其中包括用于数据更改,ACL更改和时间戳的版本号,以允许进行缓存验证和协调更新。znode的数据每次更改时,版本号都会增加。例如,每当客户端检索数据时,它也接收数据的版本。
原子地读取和写入存储在名称空间中每个znode上的数据。读取将获取与znode关联的所有数据字节,而写入将替换所有数据。每个节点都有一个访问控制列表(ACL),用于限制谁可以执行操作。
ZooKeeper还具有短暂节点的概念。只要创建znode的会话处于活动状态,这些znode就存在。会话结束时,将删除znode。当您想实现[tbd]时,临时节点非常有用。
ZooKeeper非常快速且非常简单。但是,由于其目标是作为构建更复杂的服务(例如同步)的基础,因此它提供了一组保证。这些是:
ZooKeeper的设计目标之一是提供一个非常简单的编程界面。因此,它仅支持以下操作:
create:在树中的某个位置创建一个节点
delete:删除节点
存在:测试节点是否存在于某个位置
获取数据:从节点读取数据
设置数据:将数据写入节点
获取子节点:获取节点子节点的列表
sync:等待数据传播
原文:https://www.cnblogs.com/farmersun/p/12758548.html