| 属性 | 描述 |
|---|---|
| NR | 已读入的总记录数 |
| ARGIND | 当前被处理参数标志 |
| FILENAME | 当前输入文件名 |
| FS | 输入域分隔符,默认为一个空格 |
| RS | 输入记录分隔符 |
| NF | 当前记录里域个数 |

array[index] = value :数组名array,下标index以及相应的值value。
<2>读取数组值
{ for (item in array) print array[item]} # 输出的顺序是随机的
{for(i=1;i<=len;i++) print array[i]} # Len 是数组的长度
<3>多维数组,array[index1,index2,……]:SUBSEP是数组下标分割符,默认为“\034”。可以事先设定SUBSEP,也可以直接在SUBSEP的位置输入你要用的分隔符,如:
awk ‘BEGIN{SUBSEP=":";array["a","b"]=1;for(i in array) print i}‘ a:b awk ‘BEGIN{array["a"":""b"]=1;for(i in array) print i}‘ a:b
但,有些特殊情况需要避免,如:

awk ‘BEGIN{ SUBSEP=":" array["a","b:c"]=1 # 下标为“a:b:c” array["a:b","c"]=2 #下标同样是“a:b:c” for (i in array) print i,array[i]}‘ a:b:c 2 #所以数组元素只有一个。
<4>删除数组或数组元素: 使用delete 函数
delete array #删除整个数组
delete array[item] # 删除某个数组元素(item)
<5> 排序:awk中的asort函数可以实现对数组的值进行排序,不过排序之后的数组下标改为从1到数组的长度。在gawk 3.1.2以后的版本还提供了一个asorti函数,这个函数不是依据关联数组的值,而是依据关联数组的下标排序,即asorti(array)以后,仍会用数字(1到数组长度)来作为下标,但是array的数组值变为排序后的原来的下标,除非你指定另一个参数如:asorti(a,b)。
echo ‘aa bb aa bb cc‘ |\ awk ‘{a[$0]++}END{l=asorti(a);for(i=1;i<=l;i++)print a[i]}‘ aa bb cc echo ‘aa bb aa bb cc‘ |\ awk ‘{a[$0]++}END{l=asorti(a,b);for(i=1;i<=l;i++)print b[i],a[b[i]]}‘ aa 2 bb 2 cc 1
| 属性 | 描述 |
|---|---|
| asort | asort对数组进行排序,返回数组长度 |
BEGIN{ today = strftime("%Y-%m-%d-%H", systime()); } FILENAME == ARGV[1]{ # 第一个文件 旧记录 old_user[$1] = $0; } FILENAME == ARGV[2]{ # 第二个文件 新纪录 new_user[$1] = $0; } END{ log_info = ""; log_file = log_dir"user_log_info.log."today""; for(old_uid in old_user){ if(new_user[old_uid] == ""){ log_info = log_info"leave user:"old_user[old_uid]"\n"; delete new_user[new_uid]; } } for(new_uid in new_user){ if(old_user[new_uid] == ""){ log_info = log_info"add user:"new_user[new_uid]"\n"; delete old_user[new_uid]; } } log_info = log_info"old count:"asort(old_user)";new count:"asort(new_user); system(" echo ‘"log_info"‘ > "log_file); }
分析日志shell脚本(test_log_info.sh)
#!/bin/bash yesterday(){ yy=`date +%Y` #Year yyyy mm=`date +%m` #Month mm dd=`date +%d` #Day dd if [ $dd = "01" ] then lm=`expr $mm - 1 ` if [ $lm -eq 0 ] then lm=12 yy=`expr $yy - 1 ` fi echo lm=$lm case $lm in 1|3|5|7|8|10|12) Yesterday=31 ;; 4|6|9|11) Yesterday=30 ;; 2) if [ ` expr $yy % 4 ` -eq 0 -a `expr $yy % 100 ` -ne 0 -o ` expr $yy % 400 ` -eq 0 ] then Yesterday=29 else Yesterday=28 fi ;; esac mm=$lm Yesterday=$Yesterday else Yesterday=`expr $dd - 1 ` fi case $Yesterday in 1|2|3|4|5|6|7|8|9) Yesterday=‘0‘$Yesterday esac case $mm in 1|2|3|4|5|6|7|8|9) mm=‘0‘$mm ;; esac Yesterday=$yy"-"$mm"-"$Yesterday"-05" } yesterday Today=`date "+%Y-%m-%d-05"` TEMP_DIR="/home/rd/zhoubc/bak/" awk -v "log_dir="$TEMP_DIR -f test_log_info.awk $BAKDIR""test2.conf.""$Yesterday $BAKDIR""test2.conf.""$Today
调用嵌套的shell文件(test_send.sh)
#!/bin/bash BAKDIR=‘/home/crontab/send_user/bak/‘ source test_log_info.sh
调用:
几个技术点:
shell脚本套用(source)——这样可以公用变量
source test_log_info.sh
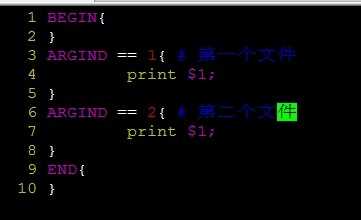
awk多文件分别处理:
FILENAME == ARGV[1]{}
FILENAME == ARGV[2]{}

原文:http://www.cnblogs.com/baochuan/p/3552370.html