一个开发和运行处理的大规模是数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
Hadoop 是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy) 计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
HDFS(分布式文件系统)
??????????? MAPREDUCE(M2:分布式运算编程框架)
??????????? YAEN(运算资源调度系统)
*目的:分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储服务,是利用更多的机器,处理更多的数据。
Hadoop 2.0包含一个支持NameNode横向扩展的HDFS,一个资源管理系统 YARN 和一个运行在 YARN 上的离线计算框架MapReduce。相比于Hadoopl.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。
HDFS集群
YARN集群
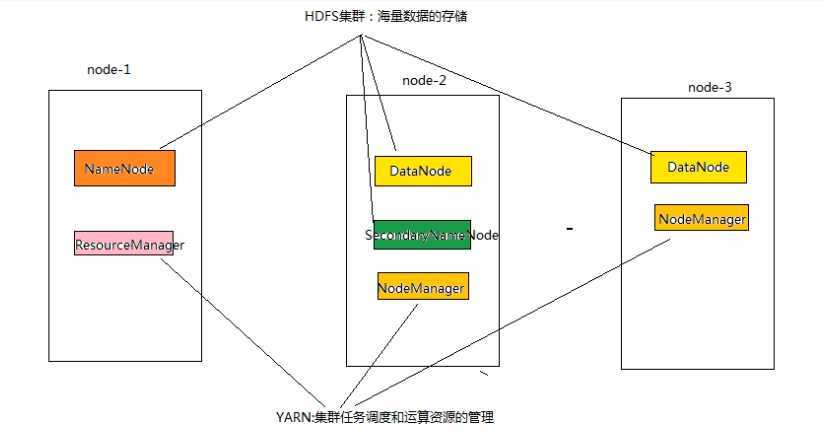
NameNode、DataNode、SecondaryNameNode
ResourceManager、NodeManager
Hadoop部署方式分三种, Standalone mode(独立模式).Pseudo-Distributedmode(伪分布式模式)、Clustermode(群集模式),其中前两种都是在单机部署。
又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
也是在1个机器上运行HDFS的NameNode和DataNode、YARN 的 ResourceManger和NodeManager,但分别启动单独的java 进程,主要用于调试。
主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
1.适合大数据处理
2.处理非结构化的数据
3.流式访问数据,一旦写入不能修改,只能追加
4.运行于廉价的商用机器集群上
5.不适合处理低延迟的数据访问
1.无法高效的储存大量小文件
2.不支持并发写入和任意的修改
HDFS采用Master/Slave主从架构来存储数据,这种架构主要由四个部分组成:
HDFS Client 客户端
NameNode??? 管理者,下达命令,负责管理整个文件的元数据
DataNode??? 把数据切割成默认大小(128M),分布式存储
Secondary NameNode??? 辅助元数据
MapReduce是一个分布式运算程序的编程框架,是用户开发"基于Hadoop的数据分析应用"的核心框架
MRAppMaster
mapTask
ReduceTask
切片定义在InputFormat类中getSplit()方法
简单地按照文件的内容长度进行切片
切片大小,默认等于block大小
切片时不用考虑数据集整体,而是逐个针对每一个文件单独切片
Shuffle的正常意思是洗牌或弄乱。
Shulffle描述着数据从map task输出到reduce task输入的这段过程。
Shuffle就是map和reduce之间的过程。
RM是一个全局的资源管理器,集群只有一个
管理YARN内运行的应用程序
为应用程序申请资源并进行进一步分配给内部任务。
负责节点的资源和使用
单个节点上的资源管理和任务
封装了某个节点上的多维度资源,如内存,CPU、磁盘、网络,返回的资源用Container表示
用户将应用程序提交到ResourceManage上。
ResourceManager为应用程序ApplicationMaster申请资源,并与某NodeManager通信,以启动ApplicationMaster。
ApplicationMaster与ResourceManager通信为内部要执行的任务申请资源,一旦得到资源后,将于NodeManager通信,以启动对应的任务。
所有任务运行完成后,ApplicationMaster向ResourceManager注销,整个应用程序运行结束。
原文:https://www.cnblogs.com/nnadd/p/12739212.html