bloomfilter:是一个通过多哈希函数映射到一张表的数据结构,能够快速的判断一个元素在一个集合内是否存在,具有很好的空间和时间效率。(典型例子,爬虫 url 去重)
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
原理:
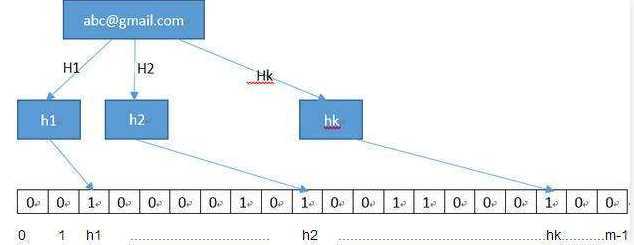
BloomFilter 会开辟一个 m 位的 bitArray (位数组),开始所有数据全部置 0 。
当一个元素过来时,通过多个哈希函数(h1,h2,h3....)计算不同的在哈希值,并通过哈希值找到对应的 bitArray 下标处,将里面的值 0 置为 1 。
在验证的时候只需要验证这些对应下标比特位是否都是 1 即可,如果其中有一个为 0(那说明没有被计算过),那么元素一定不在集合里,如果全为 1,则可能在集合里。(因为可能会有其它的元素也映射到相应的比特位上)
#python3.6 安装 #需要先安装bitarray pip3 install bitarray-0.8.1-cp36-cp36m-win_amd64.whl(pybloom_live依赖这个包,需要先安装) #下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ pip3 install pybloom_live
方式一
#ScalableBloomFilter 可以自动扩容 from pybloom_live import ScalableBloomFilter bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH) url = "www.cnblogs.com" url2 = "www.liuqingzheng.top" bloom.add(url) print(url in bloom) print(url2 in bloom)
方式二
#BloomFilter 是定长的 from pybloom_live import BloomFilter bf = BloomFilter(capacity=1000) url=‘www.baidu.com‘ bf.add(url) print(url in bf) print("www.liuqingzheng.top" in bf)
实现Bloom Filter时,首先要保证不能破坏Scrapy-Redis分布式爬取的运行架构。我们需要修改Scrapy-Redis的源码,将它的去重类替换掉
将它的 dupefilter 逻辑替换为 BloomFilter 的逻辑,在这里主要是修改 RFPDupeFilter 类的 request_seen() 方法
首先还是利用 request_fingerprint() 方法获取了 Request 的指纹,然后调用 BloomFilter 的 exists() 方法判定了该指纹是否存在,如果存在,则证明该 Request 是重复的,返回 True,否则调用 BloomFilter 的 insert() 方法将该指纹添加并返回 False,这样就成功利用 BloomFilter 替换了 Scrapy-Redis 的集合去重。
参考博客:https://cuiqingcai.com/8472.html
原文:https://www.cnblogs.com/kai-/p/12731212.html