1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
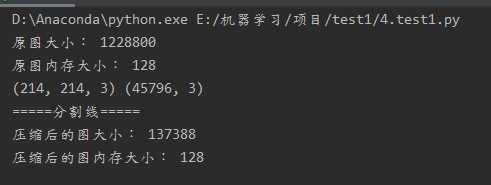
原图:
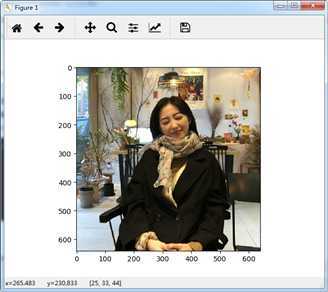
压缩后:
源代码:
import matplotlib.image as im from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np import sys image = im.imread("yukyung.jpg") print("原图大小:",image.size) print("原图内存大小:",sys.getsizeof(image)) img=image[::3,::3] #要降低像素,不然就后边加载不出来 #模型构造 x=img.reshape(-1,3) print(img.shape,x.shape) n_colors= 64 #(255*255*255) model=KMeans(n_colors) #选取kmeans模型 labels=model.fit_predict(x) #一维数组 colors=model.cluster_centers_ #二维 #压缩 new_image =colors[labels].reshape(img.shape) print("=====分割线=====") print("压缩后的图大小:",new_image.size) print("压缩后的图内存大小:",sys.getsizeof(new_image)) #对比两个图 plt.imshow(image) plt.show() plt.imshow(new_image.astype(np.uint8)) plt.show()
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
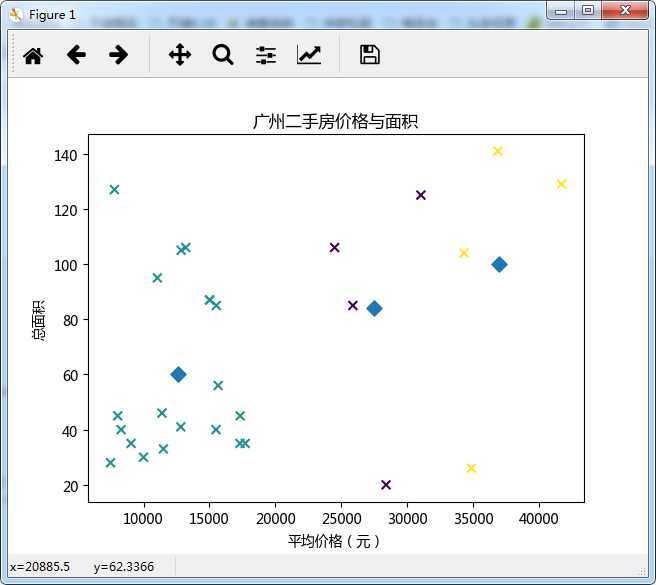
import pandas as pd from sklearn.cluster import KMeans import matplotlib.pyplot as plt data=pd.read_excel("test.xlsx") #加载文件 plt.rcParams[‘font.sans-serif‘] = [‘Microsoft YaHei‘] #可显示中文 model=KMeans(n_clusters=3) #模型的构造 model.fit(data) #模型训练 pre = model.predict(data) #模型预测 plt.scatter(data.values[:,1],data.values[:,2],c=pre,s=40,marker=‘x‘) #代入需要的值 plt.scatter(model.cluster_centers_[:,1], model.cluster_centers_[:,2],s=60,marker=‘D‘) #返回各值得中心点 plt.title("广州二手房价格与面积") plt.xlabel("平均价格(元)") plt.ylabel("总面积") plt.legend() plt.show()
原文:https://www.cnblogs.com/jinwhy/p/12722382.html