1.前提条件
1.1创建3台虚拟机,且配置好网络,建立好互信。
1.2 Java1.8环境已经配置好
1.3 Hadoop2.7.7集群已经完成搭建
1.4 Scala软件包和Spark软件包的下载
https://www.scala-lang.org/download/
http://spark.apache.org/downloads.html
2.安装Scala
2.1解压安装包:tar -zxvf scala-2.13.0.tgz
2.2 配置环境变量
vi /etc/profile export SCALA_HOME=/opt/software/scala-2.13.1 export PATH=$PATH:$SCALA_HOME/bin 退出使立即生效:[root@hdp-07]source /etc/profile
3.验证安装

4.安装spark
4.1下载后解压,到/opt/software目录下。
4.2 配置环境变量
vi /etc/profile export SPARK_HOME=/opt/software/spark export PATH=$PATH:$SPARK_HOME/bin
4.3 spark-env.sh配置
[root@master]# cd /opt/software/spark/conf [root@master]# vi spark-env.sh #添加如下内容: export JAVA_HOME=/opt/software/jdk8 export SCALA_HOME=/opt/software/scala-2.13.1 export HADOOP_HOME=/opt/software/hadoop-2.7.7 export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.7/etc/hadoop export SPARK_MASTER_HOST=hdp-07 export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_CORES=2 export SPARK_HOME=/opt/software/spark export SPARK_DIST_CLASSPATH=$(/opt/software/hadoop-2.7.7/bin/hadoop classpath)
4.4 slaves配置
hdp-08
hdp-09
4.5 复制到其他节点
在master节点上安装配置完成Spark后,将整个spark目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
4.6 测试Spark
- 在master节点启动Hadoop集群
- 在master节点启动spark
[root@master spark-2.4.3-bin-hadoop2.7]# sbin/start-all.sh
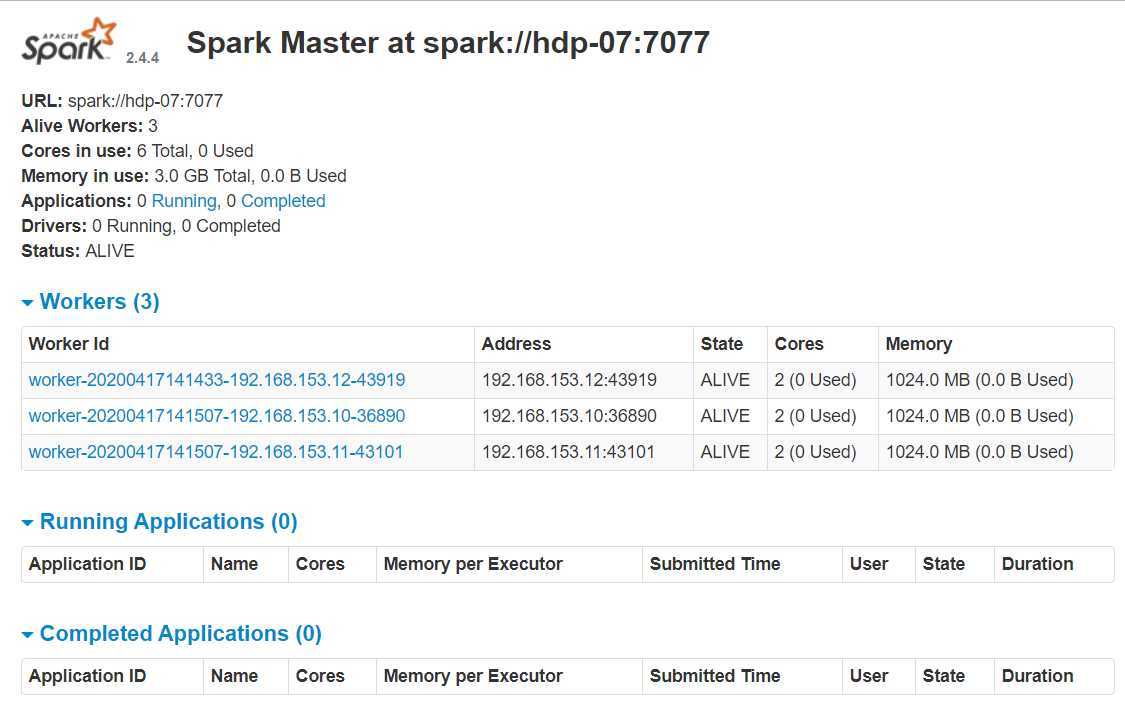
打开浏览器输入192.168.xx.xx:8080,看到如下活动的Workers,证明安装配置并启动成功:
原文:https://www.cnblogs.com/zhan98/p/12721298.html