数据分析步骤:
1.读取文件usa_election.txt
2.查看文件样式及基本信息
3.【知识点】使用map函数+字典,新建一列各个候选人所在党派party
4.使用np.unique()函数查看colums:party这一列中有哪些元素
5.使用value_counts()函数,统计party列中各个元素出现次数,value_counts()是Series中的,无参,返回一个带有每个元素出现次数的Series
6.【知识点】使用groupby()函数,查看各个党派收到的政治献金总数contb_receipt_amt
7.查看具体每天各个党派收到的政治献金总数contb_receipt_amt 。使用groupby([多个分组参数])
8. 将表中日期格式转换为‘yyyy-mm-dd‘。日期格式,通过函数加map方式进行转换
9.得到每天各政党所收政治献金数目。 考察知识点:groupby(多个字段)
10.【知识点】使用unstack()将上面所得数据中的party行索引变成列索引
11.查看老兵(捐献者职业)DISABLED VETERAN主要支持谁 :查看老兵们捐赠给谁的钱最多
12.把索引变成列,Series变量.reset_index()
13.找出各个候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额 .通过query("查询条件来查找捐献人职业")
首先为方便后续操作,将月份和参选人以及所在政党进行定义:
months = {‘JAN‘ : 1, ‘FEB‘ : 2, ‘MAR‘ : 3, ‘APR‘ : 4, ‘MAY‘ : 5, ‘JUN‘ : 6,
‘JUL‘ : 7, ‘AUG‘ : 8, ‘SEP‘ : 9, ‘OCT‘: 10, ‘NOV‘: 11, ‘DEC‘ : 12}
of_interest = [‘Obama, Barack‘, ‘Romney, Mitt‘, ‘Santorum, Rick‘,
‘Paul, Ron‘, ‘Gingrich, Newt‘]
parties = {
‘Bachmann, Michelle‘: ‘Republican‘,
‘Romney, Mitt‘: ‘Republican‘,
‘Obama, Barack‘: ‘Democrat‘,
"Roemer, Charles E. ‘Buddy‘ III": ‘Reform‘,
‘Pawlenty, Timothy‘: ‘Republican‘,
‘Johnson, Gary Earl‘: ‘Libertarian‘,
‘Paul, Ron‘: ‘Republican‘,
‘Santorum, Rick‘: ‘Republican‘,
‘Cain, Herman‘: ‘Republican‘,
‘Gingrich, Newt‘: ‘Republican‘,
‘McCotter, Thaddeus G‘: ‘Republican‘,
‘Huntsman, Jon‘: ‘Republican‘,
‘Perry, Rick‘: ‘Republican‘
}
导入相关包
import pandas as pd from pandas import Series,DataFrame import numpy as np
读取数据
df = pd.read_csv(‘./data/usa_election.txt‘) df.head(2)
读取数据显示
cmte_id | cand_id | cand_nm | contbr_nm | contbr_city | contbr_st | contbr_zip | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | receipt_desc | memo_cd | memo_text | form_tp | file_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | C00410118 | P20002978 | Bachmann, Michelle | HARVEY, WILLIAM | MOBILE | AL | 3.6601e+08 | RETIRED | RETIRED | 250.0 | 20-JUN-11 | NaN | NaN | NaN | SA17A | 736166 |
| 1 | C00410118 | P20002978 | Bachmann, Michelle | HARVEY, WILLIAM | MOBILE | AL | 3.6601e+08 | RETIRED | RETIRED | 50.0 | 23-JUN-11 | NaN | NaN | NaN | SA17A | 736166 |
新建一列各个候选人所在党派party
df[‘party‘] = df[‘cand_nm‘].map(parties)
查看colums:party这一列中有哪些元素
df[‘party‘].unique()
统计party列中各个元素出现次数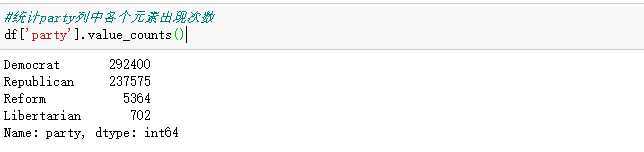
#查看各个党派收到的政治献金总数 df.groupby(by=‘party‘,axis=0)[‘contb_receipt_amt‘].sum()
#每天每个党派收到政治现金的总数 df.groupby(by=[‘contb_receipt_dt‘,‘party‘],axis=0)[‘contb_receipt_amt‘].sum()
定制转换显示的时间格式函数:
def transformData(d):
day,month,year = d.split(‘-‘)
month = months[month]
return ‘20‘+year+‘-‘+str(month)+‘-‘+day
将表中日期格式转换为‘yyyy-mm-dd‘
df[‘contb_receipt_dt‘] = df[‘contb_receipt_dt‘].map(transformData) df.head(2)
查看老兵(捐献者职业)DISABLED VETERAN主要支持谁(给谁捐钱最多)
#1.先将老兵对应的行数据取出 df[‘contbr_occupation‘] == ‘DISABLED VETERAN‘ old_bing_df = df.loc[df[‘contbr_occupation‘] == ‘DISABLED VETERAN‘] old_bing_df
#根据候选人分组 old_bing_df.groupby(by=‘cand_nm‘,axis=0)[‘contb_receipt_amt‘].sum()
#候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额 max_money = df[‘contb_receipt_amt‘].max() df.query(‘contb_receipt_amt == 1944042.43‘)
原文:https://www.cnblogs.com/dylan123/p/12716969.html