(1)树节点定义:先定义一条数据记录为一个二元组[key,data],key为记录的键值,key唯一;data为数据记录除key外的数据。
(2)B树:每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。
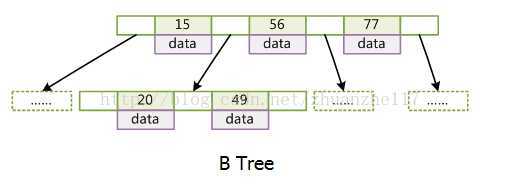
(3)B+树: 只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。
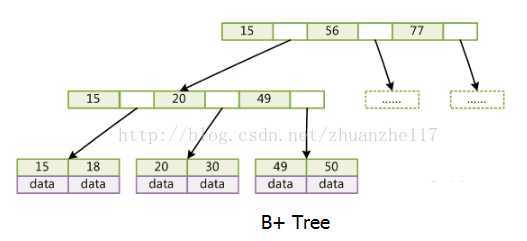
在B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。最主要的是这棵树矮胖,呵呵。一般来说,索引很大,往往以索引文件的形式存储的磁盘上,索引查找时产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的时间复杂度。树高度越小,I/O次数越少。 那为什么是B+树而不是B树呢,因为它内节点不存储data,这样一个节点就可以存储更多的key。
原文:https://www.cnblogs.com/hdc520/p/12701020.html