from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys("银魂")
driver.find_element_by_id("su").click()
time.sleep(3)
# print(driver.page_source)
# 判断搜索结果在不在页面中,可以用assert,也可以自己写if语句判断
if "空知英秋" in driver.page_source:
print("success")
else:
print("fail")
driver.quit()

#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
def search_something():
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys("银魂")
driver.find_element_by_id("su").click()
time.sleep(3)
source = driver.page_source
if "空知英秋" in source:
print("success")
else:
print("fial")
driver.quit()
search_something()

#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
num = 0
fail_num = 0
suc_num = 0
def search_something(keyword, words):
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys(keyword)
driver.find_element_by_id("su").click()
time.sleep(3)
global num, fail_num, suc_num
num += 1
source = driver.page_source
if words in source:
print(f"搜索{keyword}成功")
suc_num += 1
else:
print(f"搜索{keyword}失败")
fail_num += 1
driver.quit()
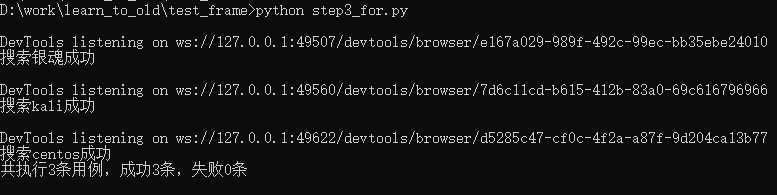
data_list = [["银魂", "空知英秋"],["kali", "Kali Linux"], ["centos", "Red Hat"]]
for i in range(len(data_list)):
search_something(data_list[i][0], data_list[i][1])
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
import unittest
from ddt import ddt,data,unpack
@ddt
class my_search(unittest.TestCase):
def setUp(self):
global num, fail_num, suc_num
num = 0
fail_num = 0
suc_num = 0
# data_list = [["银魂", "空知英秋"],["kali", "Kali Linux"], ["centos", "Red Hat"]]
# 注意,这边传的各组参数要单独拿开(如下),如果跟上面这样传list,ddt会认为是一组参数,
# 比如@data(data_list)
# 需要注意的是,每次执行一组数据,整个类是重复执行一遍的,相当于循环执行这个类
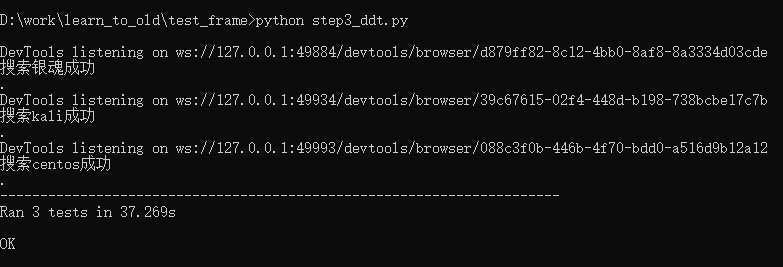
@data(["银魂", "空知英秋"],["kali", "Kali Linux"], ["centos", "Red Hat"])
@unpack
def test_search(self, keyword, words):
self.driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
self.driver.get("https://www.baidu.com")
time.sleep(3)
self.driver.find_element_by_id("kw").send_keys(keyword)
self.driver.find_element_by_id("su").click()
time.sleep(3)
global num, fail_num, suc_num
num += 1
source = self.driver.page_source
if words in source:
print(f"搜索{keyword}成功")
suc_num += 1
else:
print(f"搜索{keyword}失败")
fail_num += 1
def tearDown(self):
self.driver.quit()
print(f"本次共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
if __name__ == "__main__":
unittest.main()
(因为与大部分与for循环一样,这里只贴更改的部分)
# with open(file_path,"r") as f 打开某个文件,并读取,“r“表示读取,”w"表示写入,‘rb‘表示读二进制文件,如图片等
# 切记:先将文本设置为utf-8,在复制中文进去,然后open要用encoding
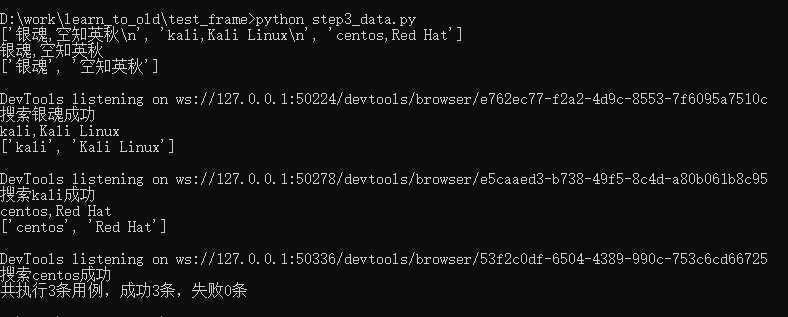
with open("step3_data.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
print(lines)
for line in lines:
print(line.strip()) # strip() 去掉字符串末尾的\n
print(line.strip().split(",")) # 切片,用“,”来将字符串切成list
keyword_list = line.strip().split(",")
search_something(keyword_list[0], keyword_list[1])
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")

#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
import sys
driver = None
num = 0
fail_num = 0
suc_num = 0
def choose_driver(driver_name):
global driver
if driver_name == "ie": # 注意if判断语句要用==
driver = webdriver.Ie(executable_path="D:\\work\\learn_to_old\\driver\\IEDriverServer.exe")
elif driver_name == "chrome":
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
elif driver_name == "firefox":
driver = webdriver.Firefox(executable_path="D:\\work\\learn_to_old\\driver\\firefox.exe")
else:
print("选择的浏览器驱动有误,请重新选择!")
sys.exit()
def open_url(url):
global driver
driver.get(url)
def send_keywords(find_way, ele, keyword):
ele = find_ele(find_way, ele)
ele.send_keys(keyword)
def click(find_way, ele):
ele = find_ele(find_way, ele)
ele.click()
def sleep(sleep_seconds):
time.sleep(int(sleep_seconds))
# 封装元素查找方法,如果想获取list,则用find_elements_by_name之类
# 也可以用js来定位 driver.execute_script("document.getElementById(‘username‘)")
def find_ele(find_way, ele):
global driver
if find_way == "id":
ele = driver.find_element_by_id(ele)
# find_str = find_element_by_id
elif find_way == "name":
ele = driver.find_element_by_name(ele)
elif find_way == "xpath":
ele = driver.find_element_by_xpath(ele)
elif find_way == "link_text":
ele = driver.find_element_by_link_text(ele)
elif find_way == "partial_link_text":
ele = driver.find_element_by_partial_link_text(ele)
elif find_way == "tag_name":
ele = driver.find_element_by_tag_name(ele)
elif find_way == "class_name":
ele = driver.find_element_by_class_name(ele)
elif find_way == "css_selector":
ele = driver.find_element_by_css_selector(ele)
else:
print("元素查找方式有误,请修正!")
sys.exit()
return ele
def my_assert(words):
global driver, num, suc_num, fail_num
num += 1
source = driver.page_source
if words in source:
print(f"搜索{words}成功")
suc_num += 1
else:
print(f"搜索{words}失败")
fail_num += 1
def quit():
global driver
driver.quit()
# 2、使用步骤
# with open(file_path,"r") as f 打开某个文件,并读取,“r“表示读取,”w"表示写入,‘rb‘表示读二进制文件,如图片等
# 切记:先将文本设置为utf-8,在复制中文进去,然后open要用encoding
# 有两种方法可以将["open","xxx"]组装成‘open("xxx")‘
# 1、先定义模板str,使用replace()函数替换即可
# 2、直接使用格式化字符串方式替换,这里使用的是f"eeee{xxx}",其他%s或者format也可以,参考订阅号上次发布的文章
with open("step4_steps.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
# strs = "do_something()" 暂时不用此方法
for line in lines:
# print(type(line))
# 根据line.count(‘|‘)来判断,步骤可以更加简化
if "|" in line:
eval_str_list = line.strip().split("|")
# print("===========",eval_str_list)
if len(eval_str_list) == 2:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘)"
elif len(eval_str_list) == 3:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘)"
elif len(eval_str_list) == 4:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘, ‘{eval_str_list[3]}‘)"
elif len(eval_str_list) == 5:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘, ‘{eval_str_list[3]}‘, ‘{eval_str_list[4]}‘)"
elif len(eval_str_list) == 6:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘, ‘{eval_str_list[3]}‘, ‘{eval_str_list[4]}‘, ‘{eval_str_list[5]}‘)"
else:
print("过长,需要优化程序")
print(eval_str_list,"*"*50)
print(eval_str)
eval(eval_str)
else:
# eval_str = strs.replace("do_something",line.strip())
eval_str = f"{line.strip()}()"
print(eval_str)
eval(eval_str)
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
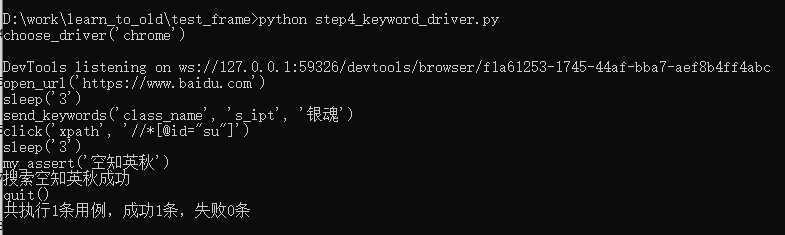
choose_driver|chrome open_url|https://www.baidu.com sleep|3 send_keywords|class_name|s_ipt|银魂 click|xpath|//*[@id="su"] sleep|3 my_assert|空知英秋 quit
def read_file_to_line(file_path):
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
return lines
test_datas = read_file_to_line("step5_data.txt") #读取测试数据
for test_data in test_datas:
test_data = eval(test_data) # 将字符串转换为json,就不需要json.dump啥的了
test_steps = read_file_to_line("step5_steps.txt") # 读取测试步骤
for test_step in test_steps:
# 找到关键字“{{”,替换数据
if "${" in test_step:
# print("#"*10,type(test_step))
# 使用正则找到变量,$前面要加\,即便是字符串前用了r
key = re.search(r"\${(.*?)}", test_step).group(1)
# print("==== key ======",key)
# {{key}} value step 替换数据
test_step = re.sub(r"\${%s}" %key, test_data[key], test_step)
# print("#"*10,test_step)
# print(type(test_step))
# 根据line.count(‘|‘)来判断,步骤可以更加简化
if "|" in test_step:
eval_str_list = test_step.strip().split("|")
# print("===========",eval_str_list)
if len(eval_str_list) == 2:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘)"
elif len(eval_str_list) == 3:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘)"
elif len(eval_str_list) == 4:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘, ‘{eval_str_list[3]}‘)"
elif len(eval_str_list) == 5:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘, ‘{eval_str_list[3]}‘, ‘{eval_str_list[4]}‘)"
elif len(eval_str_list) == 6:
eval_str = f"{eval_str_list[0]}(‘{eval_str_list[1]}‘, ‘{eval_str_list[2]}‘, ‘{eval_str_list[3]}‘, ‘{eval_str_list[4]}‘, ‘{eval_str_list[5]}‘)"
else:
print("过长,需要优化程序")
print(eval_str_list,"*"*50)
else:
# eval_str = strs.replace("do_something",test_step.strip())
eval_str = f"{test_step.strip()}()"
print(eval_str)
# 异常处理
try:
eval(eval_str)
except Exception as e:
print(f"{e}")
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
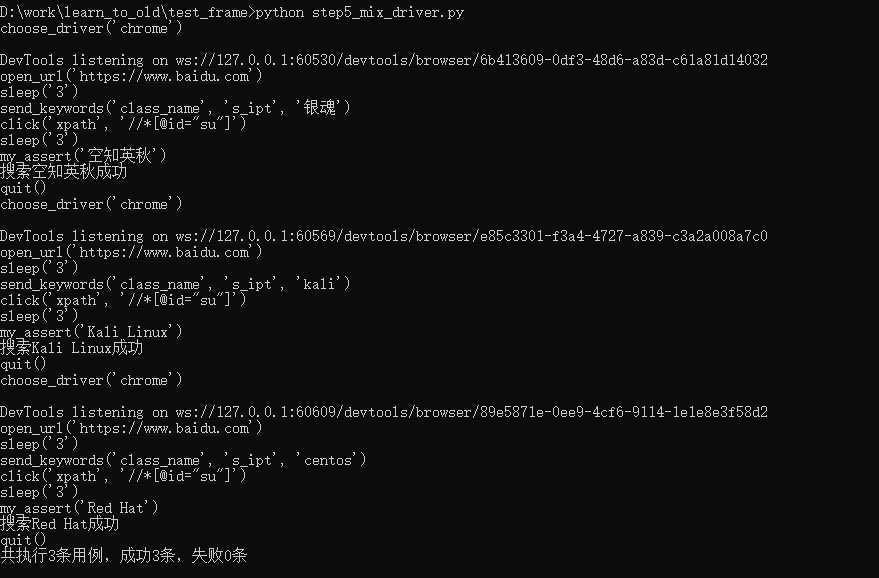
choose_driver|chrome
open_url|https://www.baidu.com
sleep|3
send_keywords|class_name|s_ipt|${keyword}
click|xpath|//*[@id="su"]
sleep|3
my_assert|${assert_words}
quit
数据:
{"keyword":"银魂", "assert_words":"空知英秋"}
{"keyword":"kali", "assert_words":"Kali Linux"}
{"keyword":"centos", "assert_words":"Red Hat"}
执行:

原文:https://www.cnblogs.com/mikasama/p/12692476.html