(基本/扩展)正则表达式;
. 任意的一个字符;汉字等
x*前面字符重复任意次;wang* (wan,wang,wangg,wanggg。。。),(wang)*(wang,wang...)
.*任意长度的任意字符串;
x+前面字符重复一次以上;x{1,}; x xx xxx
x{n,}至少n次x
x{n}精确n次
x{m,n}m次到n次
x{,n}至多n次
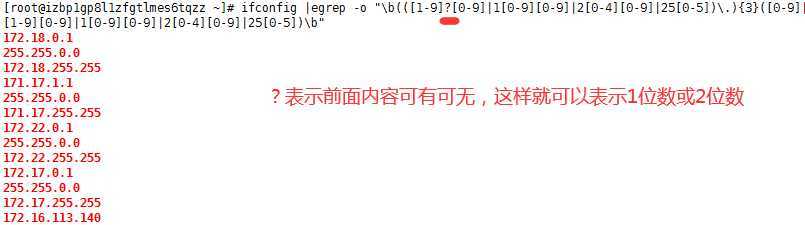
x?前面字符0次或1次,可有可无;
^行首;
$行尾;
\<词首 或 \b
\>词尾 或 \b
[wang] 任意一个字符w a n g
[^.]除了.的其它的任意一个字符
[:alpha:]
a|bxy a或bxy
(a|b)xy axy 或 bxy
(expr1) (expr2) \1 \2
vim ex模式下输入 :%s/xyz/&er/g (xyz替换成xyzer,g表示一行里替换多个xyz,不加g 则只替换一个xyz) (&,表示前面搜索出来的字符)
vim 命令模式,插入模式(a,i,o),ex模式(底行模式,vim a.sh就可以操作);
grep -o;只要数字;
扩展正则表达式grap -E 或egrep
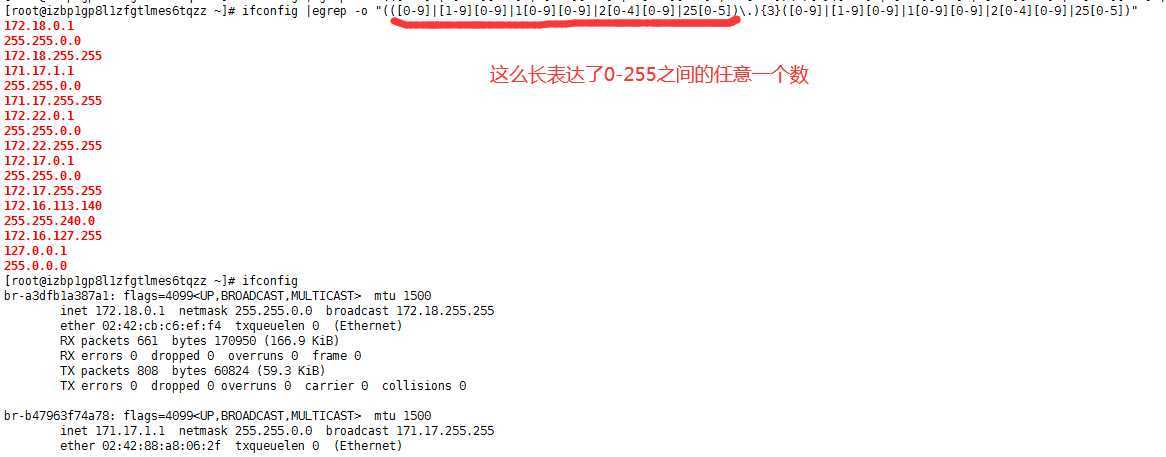
0-9 10-99 100-199 200-249 250-255
[0-9] [1-9][0-9] 1[0-9][0-9] 2[0-4][0-9] 25[0-5]
ifconfig |egrep -o "(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])"

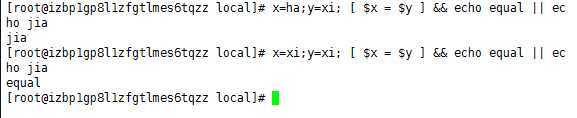
上图是字符串比较;
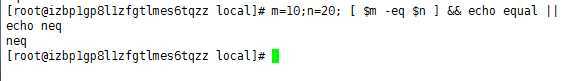
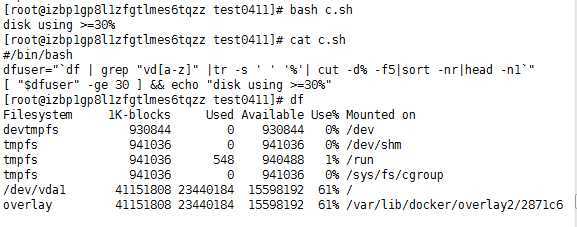
判断.sh

原文:https://www.cnblogs.com/canglongdao/p/12686350.html