二、redis持久化
Redis 虽然是一个内存级别的缓存程序,也就是redis 是使用内存进行数据的缓存的,但是其可以将内存的数据按照一定的策略保存到硬盘上,从而实现数据持久保存的目的,目前redis支持两种不同方式的数据持久化保存机制,分别是RDB和AOF。
2.1:RDB模式
RDB(Redis DataBase):基于时间的快照,其默认只保留当前最新的一次快照,特点是执行速度比较快,缺点是可能会丢失从上次快照到当前时间点之间未做快照的数据。

RDB实现的具体过程Redis从主进程先fork出一个子进程,使用写时复制机制,子进程将内存的数据保存为一个临时文件,比如dump.rdb.temp,当数据保存完成之后再将上一次保存的RDB文件替换掉,然后关闭子进程,这样可以保存每一次做RDB快照的时候保存的数据都是完整的,因为直接替换RDB文件的时候可能会出现突然断电等问题而导致RDB文件还没有保存完整就突然关机停止保存而导致数据丢失的情况,可以手动将每次生成的RDB文件进程备份,这样可以最大化保存历史数据。
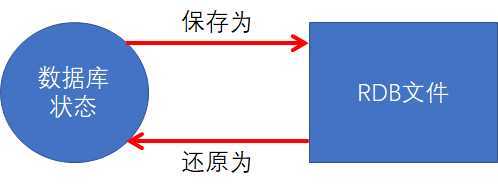
2.1.1:RDB文件的保存与加载
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
SAVE 命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求,BGSAVE 命令会派生出一个子进程,然后由子进程负责创建 RDB 文件,父进程继续处理命令请求。
RDB 文件的载入工作是在服务启动时自动执行的,所以 Redis 并没有专门用于载入 RDB 文件的命令,只要 Redis 服务器在启动时检测到 RDB 文件存在(放入配置文件指定的目录),它就会自动载入 RDB 文件。
2.1.2:RDB模式的优缺点
优点: RDB快照保存了某个时间点的数据,可以通过脚本执行bgsave(非阻塞)或者save(阻塞)命令自定义时间点备份,可以保留多个备份,当出现问题可以恢复到不同时间点的版本。 可以最大化IO 的性能,因为父进程在保存RDB 文件的时候唯一要做的是fork出一个子进程,然后的-操作都会有这个子进程操作,父进程无需任何的IO操作RDB在大量数据比如几个G的数据,恢复的速度比AOF的快。
缺点: 不能实时的保存数据,会丢失自上一次执行RDB备份到当前的内存数据,数据量非常大的时候,从父进程fork的时候需要一点时间,可能是毫秒或者秒或者分钟,取决于磁盘IO性能。
2.2:AOF模式
AOF:按照操作顺序依次将操作添加到指定的日志文件当中,特点是数据安全性相对较高,缺点是即使有些操作是重复的也会全部记录。
AOF和RDB一样使用了写时复制机制,AOF默认为每秒钟fsync一次,即将执行的命令保存到AOF文件当中,这样即使redis服务器发生故障的话顶多也就丢失1秒钟之内的数据,也可以设置不同的fsync策略,或者设置每次执行命令的时候执行fsync,fsync会在后台执行线程,所以主线程可以继续处理用户的正常请求而不受到写入AOF文件的IO影响。AOF文件是一个进行追加操作的日志文件(append only log),即操作的命令都会被追加到文件的末尾,如果因为磁盘满、突然停机等问题导致写入了不完整的命令,可以通过redis自带的命令redis-check-aof命令轻易的修复AOF文件。
redis-check-aof /app/redis/appendonly.aof
AOF模式优缺点
AOF的文件大小要大于RDB格式的文件。
根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec即每秒执行一次fsync。
redis可以在AOF文件变得过大的时候自带在后台对文件进行重写,重写后的新APF文件保存了恢复的时候需要的最新数据和最小的命令集合,这个操作是绝对安全的,因为redis 在创建新AOF文件的过程中会继续将命令追加到之前的AOF文件,这样即使服务器宕机也不会影响到当前redis 使用的AOF文件,而一旦新的AOF文件创建完成,redis就会从旧AOF文件切换到新的AOF文件,并将命令追加到新的AOF文件。
AOF文件按照命令的执行顺序保存了对redis 的所以操作,使用的是redis协议,因此可以对AOF文件进行读取和分析,也可以导出,假如不小心执行了一个FLUSHALL命令,但是只要AOF文件还没有被重写可以立即停止服务器,然后删除AOF文件末尾的FLUSHALL命令并重启redis,即将可以将数恢复到FLUSHALL命令之前的数据状态。

2.3:redis常用命令
2.3.1:CONFIG
config 命令用于查看当前redis配置、以及不重启更改redis配置等
127.0.0.1:6379> CONFIG get maxmemory #更改最大内存 1) "maxmemory" 2) "0" 127.0.0.1:6379> CONFIG set maxmemory 8589934592 OK 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> CONFIG get maxmemory 1) "maxmemory" 2) "8589934592" 127.0.0.1:6379> CONFIG SET requirepass 123456 #设置连接密码 OK 127.0.0.1:6379> CONFIG get requirepass (error) NOAUTH Authentication required. 127.0.0.1:6379> auth 123456 OK 127.0.0.1:6379> config get requirepass 1) "requirepass" 2) "123456" 127.0.0.1:6379> config get * #获取当前配置 1) "dbfilename" 2) "dump.rdb" 3) "requirepass" 4) "123456" 5) "masterauth" 6) "" 7) "cluster-announce-ip" 8) "" 9) "unixsocket" 10) "" 127.0.0.1:6379> info #显示当前节点redis运行状态信息 # Server redis_version:4.0.14 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:385503b4d6b148b0 redis_mode:standalone os:Linux 3.10.0-862.el7.x86_64 x86_64 arch_bits:64 127.0.0.1:6379> keys * #查看当前库下的所有key 1) "key-2996" 2) "key-5127" 3) "key-115" 4) "key-2154" 127.0.0.1:6379> bgsave #手动在后台执行RDB持久化操作 Background saving started 127.0.0.1:6379> DBSIZE #返回当前库下的所有key 数量 (integer) 7616 FLUSHDB #强制清空当前库中的所有key FLUSHALL #强制清空当前redis服务器所有数据库中的所有key,即删除所有数据 127.0.0.1:6379> select 1 #切换数据库,等于MySQL的use DBNAME指令。 OK
三、redis 高可用与集群
3.1:配置reids 主从
主备模式,可以实现Redis数据的跨主机备份。
程序端连接到高可用负载的VIP,然后连接到负载服务器设置的Redis后端real server,此模式不需要在程序里面配置Redis服务器的真实IP地址,当后期Redis服务器IP地址发生变更只需要更改redis 相应的后端real server即可,可避免更改程序中的IP地址设置。
3.1.1:Slave主要配置
Redis Slave 也要开启持久化并设置和master同样的连接密码,因为后期slave会有提升为master的可能,Slave端切换master同步后,其他slave会丢失之前的所有数据。
一旦某个Slave成为一个master的slave,Redis Slave服务会清空当前redis服务器上的所有数据并将master的数据导入到自己的内存,但是断开同步关系后不会删除当前已经同步过的数据。
3.1.1.1:修改配置文件
当前状态为master,需要转换为slave角色并指向master服务器的IP+PORT+Password
slaveof 192.168.235.145 6379 masterauth 123456 ##master如果密码需要设置
3.1.1.2:master和slave 状态
master节点:

master日志:

当前slave状态:
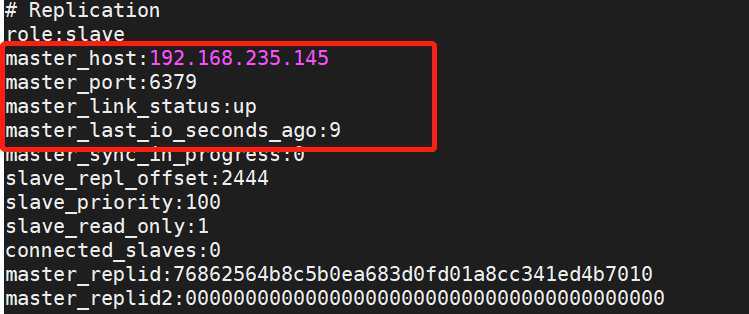
slave节点日志
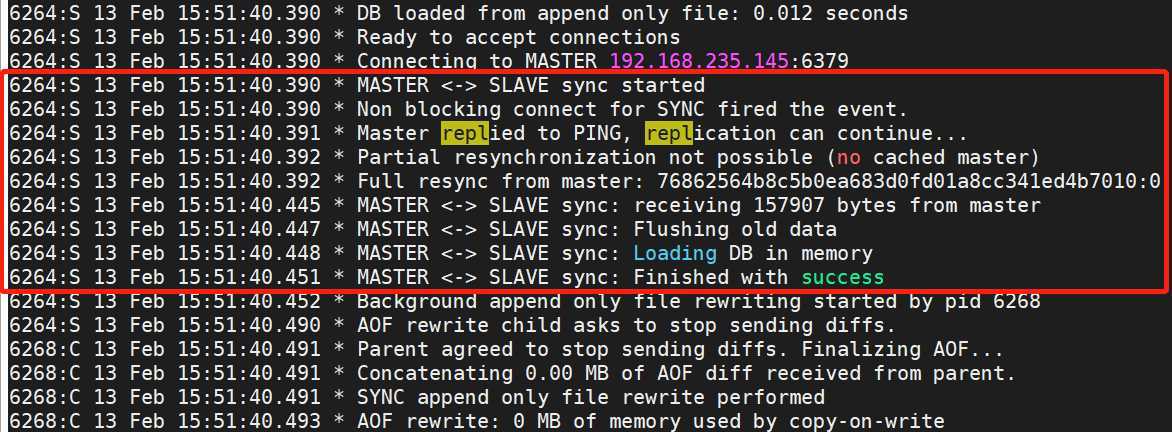
测试:
在master上添加一个key ,观察slave节点是否同步到。
master节点:
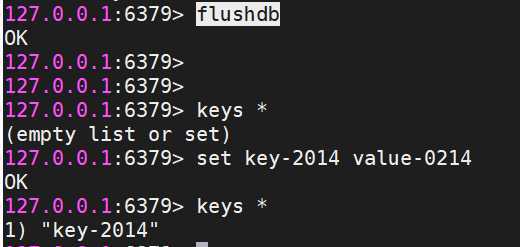
slave节点

3.1.1.3:主从复制过程
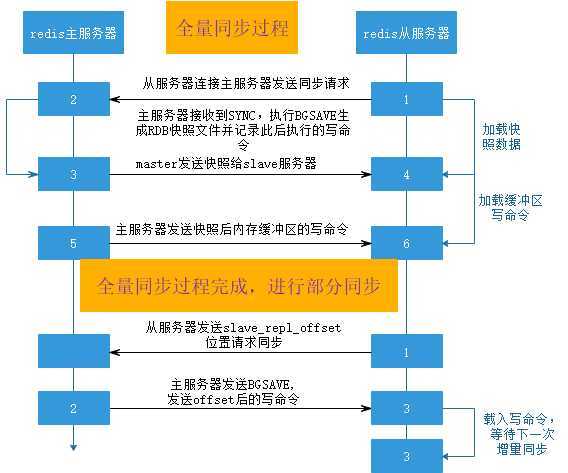
Redis支持主从复制分为全量同步和增量同步,首次同步是全量同步,主从同步可以让从服务器从主服务器备份数据,而且从服务器还可与有从服务器,即另外一台redis服务器可以从一台从服务器进行数据同步,redis 的主从同步是非阻塞的,master收到从服务器的sync(2.8版本之前是PSYNC)命令会fork一个子进程在后台执行bgsave命
令,并将新写入的数据写入到一个缓冲区里面,bgsave执行完成之后并生成的将RDB文件发送给客户端,客户端将收到后的RDB文件载入自己的内存,然后redis master再将缓冲区的内容在全部发送给redis slave,之后的同步slave服务器会发送一个offset的位置(等同于MySQL的binlog的位置)给主服务器,主服务器检查后位置没有错误将此位置之后的数据包括写在缓冲区的积压数据发送给redis从服务器,从服务器将主服务器发送的挤压数据写入内存,这样一次完整的数据同步,再之后再同步的时候从服务器只要发送当前的offset位 置给主服务器,然后主服务器根据相应的位置将之后的数据发送给从服务器保存到其内存即可。
3.2:redis 集群
上一个步骤的主从架构无法实现master和slave角色的自动切换,即当master出现redis服务异常、主机断电、磁盘损坏等问题导致master无法使用,而redis高可用无法实现自故障转移(将slave提升为master),需要手动改环境配置才能切换到slave redis服务器,另外也无法横向扩展Redis服务的并行写入性能,当单台Redis服务器性能无法满足业务写入需求的时候就必须需要一种方式解决以上的两个核心问题,即:1.master和slave角色的无缝切换,让业务无感知从而不影响业务使用 2.可以横向动态扩展Redis服务器,从而实现多台服务器并行写入以实现更高并发的目的。
3.2.1:Sentinel(哨兵):
Sentinel 进程是用于监控redis集群中Master主服务器工作的状态,在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用,其已经被集成在redis2.6+的版本中,Redis的哨兵模式到了2.8版本之后就稳定了下来。一般在生产环境也建议使用Redis的2.8版本的以后版本。哨兵(Sentinel) 是一个分布式系统,可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossip protocols)来接收关于Master主服务器是否下线的信息,并使用投票协议(Agreement Protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。每个哨兵(Sentinel)进程会向其它哨兵(Sentinel)、Master、Slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定配置时间(可配置的)内未得到回应,则暂时认为对方已掉线,也就是所谓的”主观认为宕机” ,主观是每个成员都具有的独自的而且可能相同也可能不同的意识,英文名称:Subjective Down,简称SDOWN。有主观宕机,肯定就有客观宕机。当“哨兵群”中的多数Sentinel进程在对Master主服务器做出SDOWN 的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,这种方式就是“客观宕机”,客观是不依赖于某种意识而已经实际存在的一切事物,英文名称是:ObjectivelyDown, 简称 ODOWN。通过一定的vote算法,从剩下的slave从服务器节点中,选一台提升为Master服务器节点,然后自动修改相关配置,并开启故障转移(failover)。
Sentinel 机制可以解决master和slave角色的切换问题。
3.2.1.1:手动配置master
需要手动先指定某一台Redis服务器为master,然后将其他slave服务器使用命令配置为master服务器的slave,哨兵的前提是已经手动实现了一个redis master-slave的运行环境。
实现一个一主两从基于哨兵的高可用redis架构。
在主从基础之上添加一台虚拟机
master节点:
应用程序如何连接redis
Redis 官方客户端:https://redis.io/clients
Redis为了保障高可用,服务一般都是Sentinel部署方式,当Redis服务中的主服务挂掉之后,会仲裁出另外一台Slaves服务充当Master。这个时候,我们的应用即使使用了Jedis 连接池,Master服务挂了,我们的应用将还是无法连接新的Master服务,为了解决这个问题, Jedis也提供了相应的Sentinel实现,能够在Redis Sentinel主从切换时候,通知我们的应用,把我们的应用连接到新的Master服务。
Redis Sentinel的使用也是十分简单的,只是在JedisPool中添加了Sentinel和MasterName参数,JRedis Sentinel底层基于Redis订阅实现Redis主从服务的切换通知,当Redis发生主从切换时,Sentinel会发送通知主动通知Redis进行连接的切换,JedisSentinelPool在每次从连接池中获取链接对象的时候,都要对连接对象进行检测,如果此链接和Sentinel的Master服务连接参数不一致,则会关闭此连接,重新获取新的Jedis连接对象。
3.2.1.2:编辑配置文件sentinel.conf
Server1 配置,其他两个server配置一样
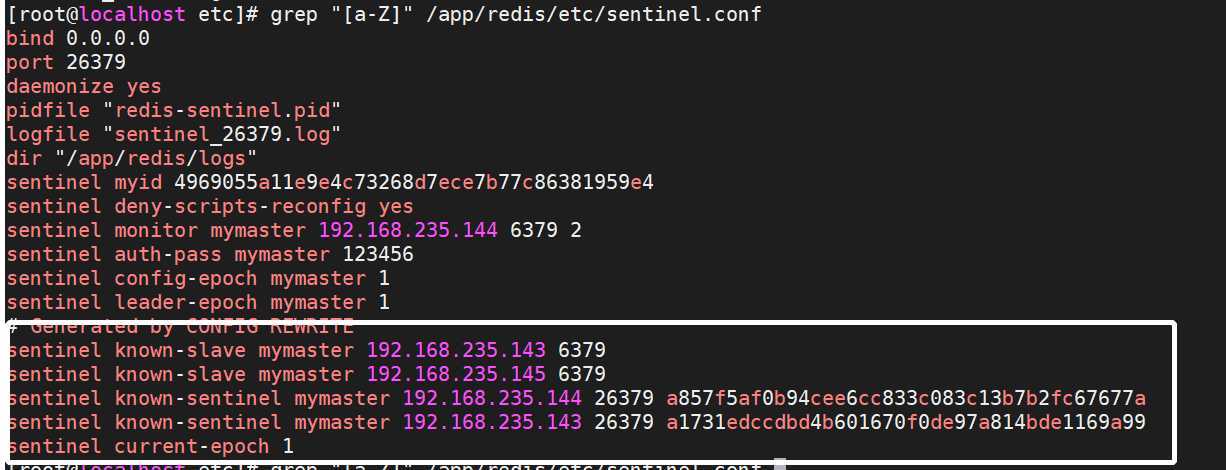
bind 0.0.0.0 port 26379 daemonize yes pidfile "redis-sentinel.pid" logfile "sentinel_26379.log" dir "/app/redis/logs" sentinel monitor mymaster 192.168.235.145 6379 2 #法定人数限制(quorum),即有几个slave认为master down了就进行故障转移 sentinel auth-pass mymaster 123456 sentinel down-after-milliseconds mymaster 30000 #(SDOWN)主观下线的时间 sentinel parallel-syncs mymaster 1 #发生故障转移时候同时向新master同步数据的slave数量,数字越小总 同步时间越长 sentinel failover-timeout mymaster 180000 #所有slaves指向新的master所需的超时时间 sentinel deny-scripts-reconfig yes #禁止修改脚本
3.2.1.3:启动哨兵
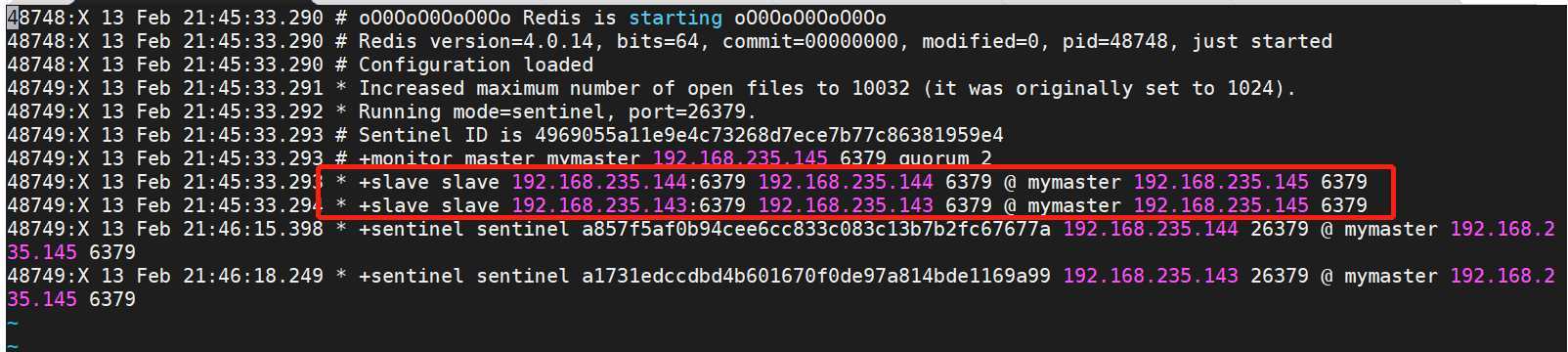
三台哨兵都要启动
redis-sentinel /app/redis/etc/sentinel.conf redis-sentinel /app/redis/etc/sentinel.conf redis-sentinel /app/redis/etc/sentinel.conf
端口验证:

哨兵日志:
当前redis master状态
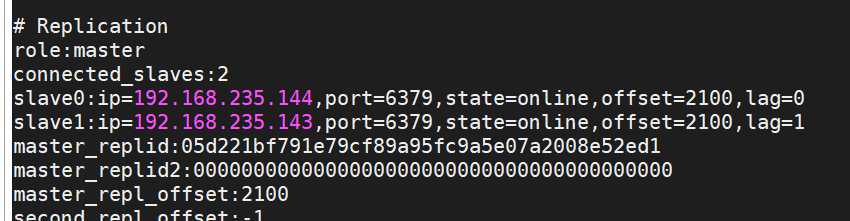
127.0.0.1:6379> info Replication # Replication role:master connected_slaves:2 slave0:ip=192.168.235.144,port=6379,state=online,offset=202315,lag=1 slave1:ip=192.168.235.143,port=6379,state=online,offset=202605,lag=0 master_replid:05d221bf791e79cf89a95fc9a5e07a2008e52ed1 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:202750 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:536870912 repl_backlog_first_byte_offset:1 repl_backlog_histlen:202750
当前sentinel状态
在sentinel状态中尤其是最后一行,涉及到masterIP是多少,有几个slave,有几个sentinels,必须是符合全部服务器数量的。
[root@localhost etc]# redis-cli -h 192.168.134.143 -p 26379 192.168.134.143:26379> info Sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.235.145:6379,slaves=2,sentinels=3
3.2.1.4:停止Redis Master测试故障转移
故障转移时sentinel的信息

故障转移后redis.conf中的replicaof行的master IP会被修改,sentinel.conf中的sentinel monitor IP会被修改。
原文:https://www.cnblogs.com/lummg-DAY/p/12304500.html