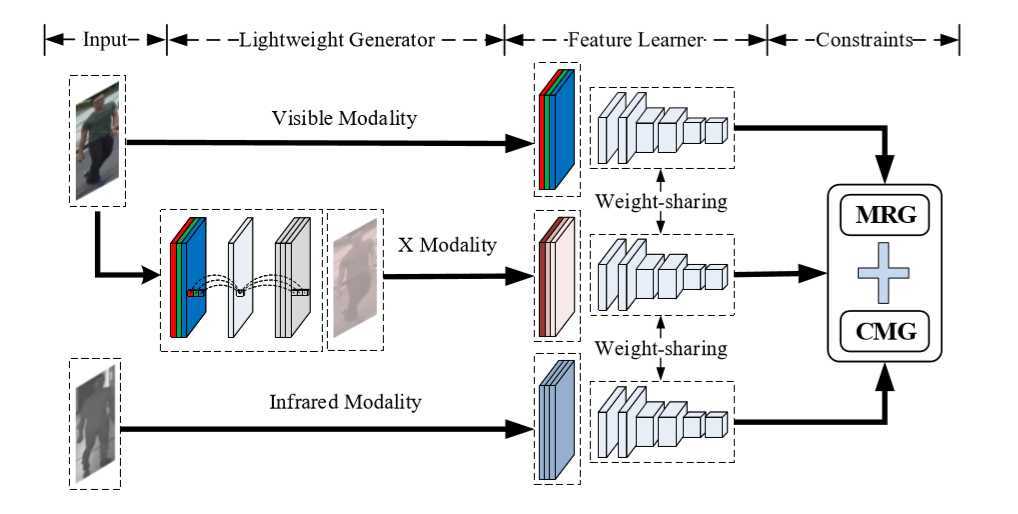
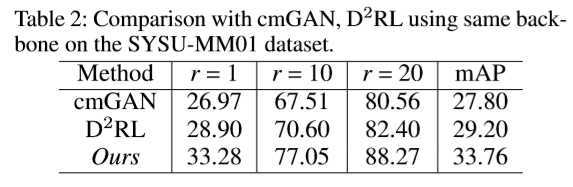
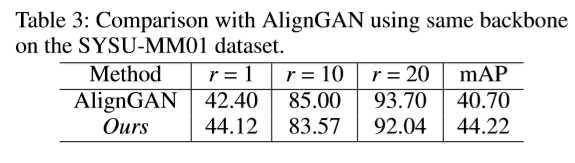
??相对于其他方法(cmGAN,AlignGAN)用GAN方法学习判别性特征,GAN更为复杂、难训练,而本文提出的 X 模态是一种用轻量级网络,以自监督方式,额外代价可忽略不计的生成器生成的中间辅助模态,更为容易训练。
??由两个 1x1 的卷积和一个 ReLU 激活层构成,可见光图像作为输入, 先用一个 1x1 卷积处理为单通道图像,再用另外一个 1x1 卷积进行升维,恢复成三通道图像。ReLU 激活层用于提高网络的非线性表达能力。
优点
??在测试阶段,选择红外图像(IR)作为查询,可见光图像(RGB)作为候选集,检索出与查询图像距离(欧氏距离)和最小的RGB图像和X模态图像,返回其索引,公式如下:
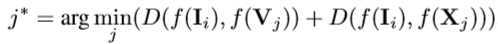
??本文方法:先用一张RGB图像生成X模态的图像,然后将RGB、IR、X三个模态的图像分别输入同一个backbone(ResNet-50)中,使用模态间(CMG)和模态内(MRG)两个约束进行训练。接下来介绍 CMG 和MRG 两个约束:
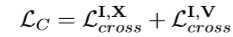
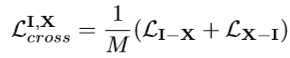
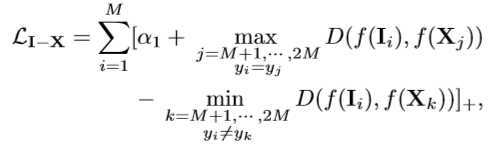
??跨模态约束(CMG)包含两个部分,分别是 IR 模态和 X 模态之间的 cross 损失和 IR 模态和 RGB 模态之间的 cross 损失。这里的 cross 损失与Triplet 损失相似,其目的是将两个模态间同一个ID行人的图像距离拉近,不同ID的距离拉远。从而达到 IR-X、 IR-RGB 跨模态间的正样本距离拉近。
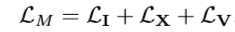
???对于 IR 模态:
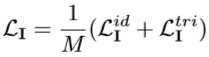
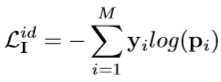
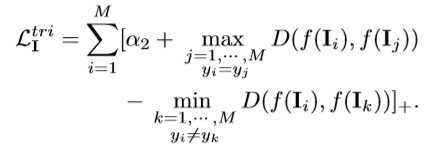
??模态内约束(MRG)由三个模态的损失构成,这里只说明 IR 模态下的损失,其余两个模态同理可得。IR 模态内的损失由两部分构成,一个是 id 损失,一个是 triplet 损失,相对于 CMG 比较简单。
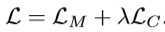
??上式为整个网络训练损失函数,其中,\(\lambda\) 是 CMG 的权重系数,用于衡量跨模态约束的对整体性能提升的贡献。
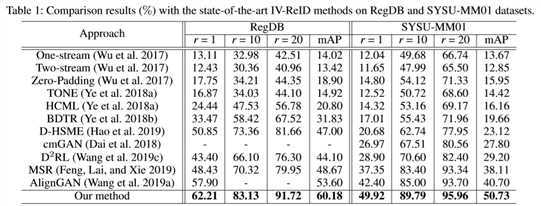
??总体来说,在两个数据集上都取得较为明显的提升。
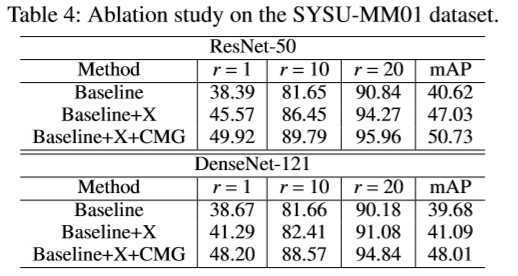
??其中 Baseline 表示只使用两个模态内的损失 \(\mathcal{L}_V\) 和 \(\mathcal{L}_I\) 进行训练; Baseline + X 表示引入 X 模态后,使用模态内的损失 \(\mathcal{L}_V\)、 \(\mathcal{L}_I\) 和 \(\mathcal{L}_X\) ; Baseline + X + CMG 表示在使用模态内损失的基础上加入模态间损失 CMG。 由表可见,引入 X 模态有助于降低两个模态的差异性,使用 CMG 损失能进一步提升跨模态 ReID 任务的性能。
A closer look at X
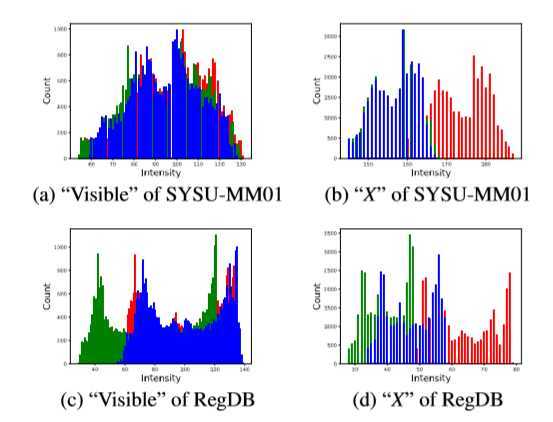

??由上图知,可见光图像的三个颜色通道的统计是相似的,然而在 X 模态中,R 通道的强度比 G、B两个通道更强,可视化的视觉效果就是,X模态的图像偏红,介于 RGB 和 IR 两个模态之间,验证了通过引入中间模态有助于减小跨模态之间的鸿沟。
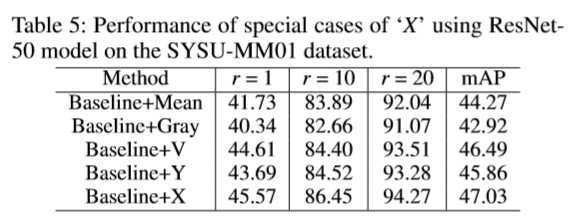
??Table 5 展示了用其他方案生成的模态替代 X 模态的实验结果。其中 Mean 表示将 RGB 图像进行逐通道计算均值,Gray 表示将 RGB 图像转化为灰度图,V 表示选取 RGB 图像的 HSV 颜色空间中的 V 信息; Y 表示选取 RGB 图像的 YCbCr 颜色空间中的 Y信息。由实验可知,采用轻量级网络生成的 X 模态效果最佳。
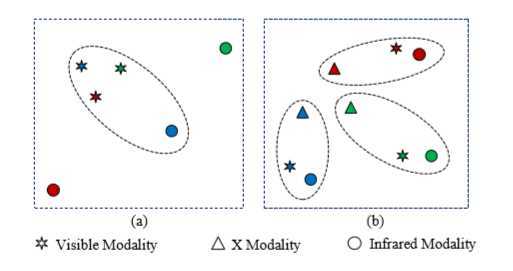
本文亮点在于引入一个中间模态 X,旨在减少两个模态间的差异性,更好的学习到两个模态间的联系。
X 模态是由一个轻量级网络,以自监督方式生成的,额外计算量可忽略不计。
Infrared-Visible Cross-Modal Person Re-Identi?cation with an X Modality (AAAI 2020)
原文:https://www.cnblogs.com/codeSnail/p/12642592.html