import logging CRITICAL = 50 # FATAL = CRITICAL ERROR = 40 WARNING = 30 # WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 # 不设置
import logging logging.basicConfig( # 1.日志输出位置:1.终端 2.文件 filename = ‘access.log‘, # 不指定,默认打印到终端 # 2.日志格式 format=‘%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s‘, # 3.时间格式 datefmt=‘%Y-%m-%d %H:%M:%S %p‘, # 4.日志级别 # CRITICAL = 50 #FATAL = CRITICAL # ERROR = 40 # WARNING = 30 #WARN = WARNING # INFO = 20 # DEBUG = 10 # NOTSET = 0 #不设置 level=10, )
logging.debug(‘调试debug‘) # 日志级别:10 logging.info(‘消息info‘) # 日志级别:20 logging.warning(‘警告warn‘) # 日志级别:30 logging.error(‘错误error‘) # 日志级别:40 logging.critical(‘严重critical‘) # 日志级别:20
4.1 定义三种日志输出格式,日志中可能用到的格式化串如下:
日志配置字典LOGGING_DIC
%(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
4.2 强调:其中的%(name)s为getlogger时指定的名字
standard_format = ‘%(asctime)s - %(threadName)s:%(thread)d - 日志名字:%(name)s - %(filename)s:%(lineno)d -‘ ‘%(levelname)s - %(message)s‘ simple_format = ‘[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s‘ test_format = ‘%(asctime)s] %(message)s‘
4.3 日志配置字典LOGGING_DIC = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘formatters‘: { ‘standard‘: { ‘format‘: standard_format }, ‘simple‘: { ‘format‘: simple_format }, ‘test‘: { ‘format‘: test_format }, }, ‘filters‘: {}, # handlers是日志的接收者,不同的handler会将日志输出到不同的位置 ‘handlers‘: { #打印到终端的日志 ‘console‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.StreamHandler‘, # 打印到屏幕 ‘formatter‘: ‘simple‘ }, ‘default‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.handlers.RotatingFileHandler‘, # 保存到文件 # ‘maxBytes‘: 1024*1024*5, # 日志大小 5M ‘maxBytes‘: 1000, ‘backupCount‘: 5, ‘filename‘: ‘a1.log‘, # os.path.join(os.path.dirname(os.path.dirname(__file__)),‘log‘,‘a2.log‘) ‘encoding‘: ‘utf-8‘, ‘formatter‘: ‘standard‘, }, #打印到文件的日志,收集info及以上的日志 ‘other‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.FileHandler‘, # 保存到文件 ‘filename‘: ‘a2.log‘, # os.path.join(os.path.dirname(os.path.dirname(__file__)),‘log‘,‘a2.log‘) ‘encoding‘: ‘utf-8‘, ‘formatter‘: ‘test‘, }, }, # loggers是日志的产生者,产生的日志会传递给handler然后控制输出 ‘loggers‘: { #logging.getLogger(__name__)拿到的logger配置 ‘kkk‘: { ‘handlers‘: [‘console‘,‘other‘], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 ‘level‘: ‘DEBUG‘, # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制) ‘propagate‘: False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递 }, ‘终端提示‘: { ‘handlers‘: [‘console‘,], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 ‘level‘: ‘DEBUG‘, # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制) ‘propagate‘: False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递 }, ‘‘: { ‘handlers‘: [‘default‘, ], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 ‘level‘: ‘DEBUG‘, # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制) ‘propagate‘: False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递 }, }, }
# import logging.config # # logging.config.dictConfig(settings.LOGGING_DIC) # print(logging.getLogger) # 接下来要做的是:拿到日志的产生者即loggers来产生日志 # 第一个日志的产生者:kkk # 第二个日志的产生者:bbb # 但是需要先导入日志配置字典LOGGING_DIC import settings from logging import config,getLogger config.dictConfig(settings.LOGGING_DIC) # logger1=getLogger(‘kkk‘) # logger1.info(‘这是一条info日志‘) # logger2=getLogger(‘终端提示‘) # logger2.info(‘logger2产生的info日志‘) # logger3=getLogger(‘用户交易‘) # logger3.info(‘logger3产生的info日志‘) logger4=getLogger(‘用户常规‘) logger4.info(‘logger4产生的info日志‘)
# 补充两个重要额知识
# 1、日志名的命名
# 日志名是区别日志业务归属的一种非常重要的标识
# 2、日志轮转
# 日志记录着程序员运行过程中的关键信息
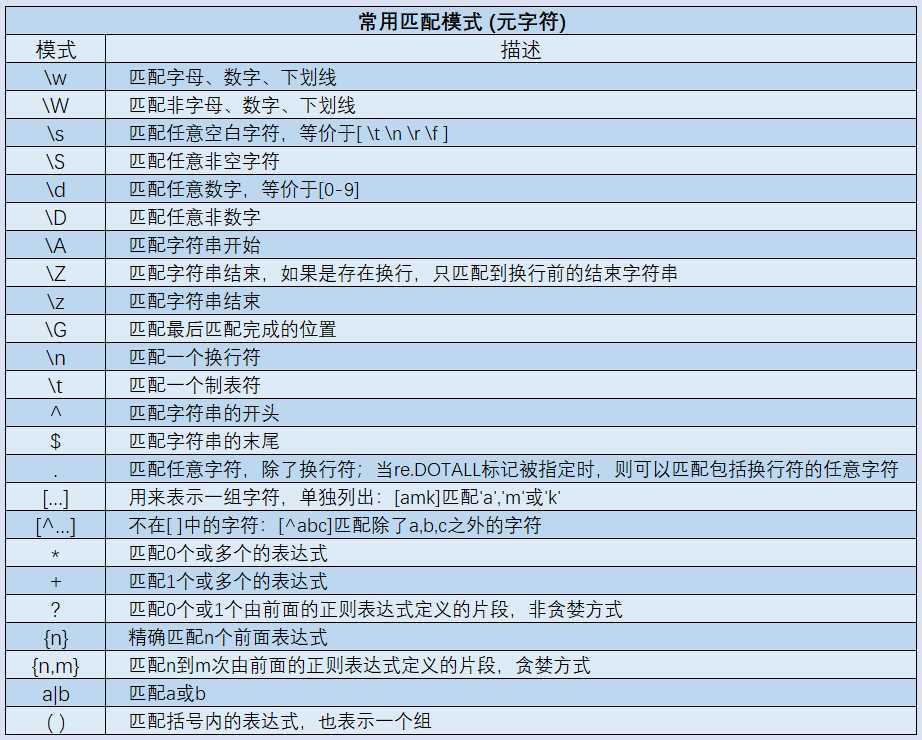
import re # 匹配字母、数字、下划线 print(re.findall(‘\w‘,‘aAbc123_*()-=‘)) # [‘a‘, ‘A‘, ‘b‘, ‘c‘, ‘1‘, ‘2‘, ‘3‘, ‘_‘] # 匹配非字母、数字、下划线 print(re.findall(‘\W‘,‘aAbc123_*()-= ‘)) # [‘*‘, ‘(‘, ‘)‘, ‘-‘, ‘=‘, ‘ ‘] # 匹配任意空白字符,等价于[ \t \n \r \f ] print(re.findall(‘\s‘,‘aA\rbc\t\n12\f3_*()-= ‘)) # [‘\r‘, ‘\t‘, ‘\n‘, ‘\x0c‘, ‘ ‘] # 匹配任意非空字符 print(re.findall(‘\S‘,‘aA\rbc\t\n12\f3_*()-= ‘)) # [‘a‘, ‘A‘, ‘b‘, ‘c‘, ‘1‘, ‘2‘, ‘3‘, ‘_‘, ‘*‘, ‘(‘, ‘)‘, ‘-‘, ‘=‘] # 匹配任意数字,等价于[0-9] print(re.findall(‘\d‘,‘aA\rbc\t\n12\f3_*()-= ‘)) # [‘1‘, ‘2‘, ‘3‘] # 匹配任意非数字 print(re.findall(‘\D‘,‘aA\rbc\t\n12\f3_*()-= ‘)) # [‘a‘, ‘A‘, ‘\r‘, ‘b‘, ‘c‘, ‘\t‘, ‘\n‘, ‘\x0c‘, ‘_‘, ‘*‘, ‘(‘, ‘)‘, ‘-‘, ‘=‘, ‘ ‘] # 匹配字符串开始 print(re.findall(‘\Aalex‘,‘ alexis alex sb‘)) # alex # [] #匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 print(re.findall(‘sb\Z‘,‘ alexis alexsb sb‘)) # sb\Z # [‘sb‘] print(re.findall(‘sb\Z‘,"""alex alexis alex sb """)) # [] # 匹配字符串的开头 print(re.findall(‘^alex‘,‘alexis alex sb‘)) # [‘alex‘] # 匹配字符串的末尾 print(re.findall(‘sb$‘,‘alexis alex sb‘)) # [‘sb‘] print(re.findall(‘sb$‘,"""alex alexis alex sb """)) # [‘sb‘] print(re.findall(‘^alex$‘,‘alexis alex sb‘)) # [] print(re.findall(‘^alex$‘,‘al ex‘)) # [] print(re.findall(‘^alex$‘,‘alex‘)) # [‘alex‘]
# 重复匹配:| . | * | ? | .* | .*? | + | {n,m} | # 1、.:匹配任意字符,除了换行符;当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 print(re.findall(‘a.b‘,‘a1b a2b a b abbbb a\nb a\tb a*b‘)) # a.b # [‘a1b‘,‘a2b‘,‘a b‘,‘abb‘,‘a\tb‘,‘a*b‘] print(re.findall(‘a.b‘,‘a1b a2b a b abbbb a\nb a\tb a*b‘,re.DOTALL)) # [‘a1b‘, ‘a2b‘, ‘a b‘, ‘abb‘, ‘a\nb‘, ‘a\tb‘, ‘a*b‘] # 2、*:匹配0个或多个的表达式,左侧字符重复0次或无穷次,性格贪婪 print(re.findall(‘ab*‘,‘a ab abb abbbbbbbb bbbbbbbb‘)) # ab* #[‘a‘,‘ab‘,‘abb‘,‘abbbbbbbb‘] # 3、+:匹配1个或多个的表达式,左侧字符重复1次或无穷次,性格贪婪 print(re.findall(‘ab+‘,‘a ab abb abbbbbbbb bbbbbbbb‘)) # ab+ # [‘ab‘, ‘abb‘, ‘abbbbbbbb‘] # 4、?:左侧字符重复0次或1次,性格贪婪 print(re.findall(‘ab?‘,‘a ab abb abbbbbbbb bbbbbbbb‘)) # ab? # [‘a‘,‘ab‘,‘ab‘,‘ab‘] # 5、{n,m}:匹配n到m次,左侧字符重复n次到m次,由前面的正则表达式定义的片段,贪婪方式 # {0,} => * # {1,} => + # {0,1} => ? # {n}单独一个n代表只出现n次,多一次不行少一次也不行 print(re.findall(‘ab{2,5}‘,‘a ab abb abbb abbbb abbbbbbbb bbbbbbbb‘)) # ab{2,5} # [‘abb‘,‘abbb‘,‘abbbb‘,‘abbbbb] print(re.findall(‘\d+\.?\d*‘,"asdfasdf123as1111111.123dfa12adsf1asdf3")) # \d+\.?\d* \d+\.?\d+ # [‘123‘, ‘1111111.123‘, ‘12‘, ‘1‘, ‘3‘] # []匹配指定字符一个 print(re.findall(‘a\db‘,‘a1111111b a3b a4b a9b aXb a b a\nb‘,re.DOTALL)) # [‘a3b‘, ‘a4b‘, ‘a9b‘] print(re.findall(‘a[501234]b‘,‘a1111111b a3b a4b a9b aXb a b a\nb‘,re.DOTALL)) # [‘a3b‘, ‘a4b‘] print(re.findall(‘a[0-5]b‘,‘a1111111b a3b a1b a0b a4b a9b aXb a b a\nb‘,re.DOTALL)) # [‘a3b‘, ‘a1b‘, ‘a0b‘, ‘a4b‘] print(re.findall(‘a[0-9a-zA-Z]b‘,‘a1111111b axb a3b a1b a0b a4b a9b aXb a b a\nb‘,re.DOTALL)) # [‘axb‘, ‘a3b‘, ‘a1b‘, ‘a0b‘, ‘a4b‘, ‘a9b‘, ‘aXb‘] print(re.findall(‘a[^0-9a-zA-Z]b‘,‘a1111111b axb a3b a1b a0b a4b a9b aXb a b a\nb‘,re.DOTALL)) # [‘a b‘, ‘a\nb‘] print(re.findall(‘a-b‘,‘a-b aXb a b a\nb‘,re.DOTALL)) # [‘a-b‘] print(re.findall(‘a[-0-9\n]b‘,‘a-b a0b a1b a8b aXb a b a\nb‘,re.DOTALL)) # [‘a-b‘, ‘a0b‘, ‘a1b‘, ‘a8b‘, ‘a\nb‘]
python基础学习-常用模块的使用(扩展补充,高级使用)(三)
原文:https://www.cnblogs.com/dingbei/p/12622835.html