段落引用这个教程网上很多。我们这次使用docker安装,比较简便。
# prometheus服务端
docker pull prom/prometheus
# prometheus面板ui
docker pull grafana/grafana
# 告警(按需处理)
docker pull prom/alertmanager
1. chmod -r 755 node_exporter
2. nohup ./node_exporter &
完成后访问 http://ip:9100/metrics 若可以看到metrics信息则代表启动成功.
global:
scrape_interval: 60s
evaluation_interval: 60s
# 若不需要告警,则不需要配置此处,也不需要rules.yml配置文件
rule_files:
- "/etc/prometheus/rules.yml"
scrape_configs:
# 可参考使用,本例子中未使用这个
- job_name: ‘federate-jvm‘
scrape_interval: 20s
scrape_timeout: 10s
honor_labels: true
metrics_path: ‘/federate‘
params:
‘match[]‘:
- ‘{kubernetes_namespace=~"^375-.*"}‘
static_configs:
- targets:
- 10.100.72.187:9090
-
# 可配置上文启动的node_exporter
- job_name: demo
static_configs:
- targets: [‘111.11.11.111:9100‘,‘111.11.11.112:9100‘]
# 若不需要告警,则不需要配置此处
alerting:
alertmanagers:
- static_configs:
- targets: ["111.11.11.111:9093"]
groups:
- name: machine_mem_alerting
rules:
- alert: 主机内存利用率
# 这里是具体的promQl,这里是 (1- 可用内存量/总内存量) * 100 得到占用百分比,若大于80则触发规则
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) *100 >80
# 每分钟查询一次
for: 1m
# 告警级别
labels:
severity: red
# 一些参数
annotations:
# 这里的值都是取自prometheus,具体值具体查询
summary: " {{ $labels.instance }} 当前值为{{ .Value }} "
description: "{{ $labels.instance }} 内存利用率查过80%"
# 将刚才编写好的配置文件挂载到prometheus中,这样可以随时修改配置restart即可
docker run -d --name=prometheus -p 9090:9090 -v /home/prometheus/:/etc/prometheus/ prom/prometheus
启动成功后,可访问http://ip:9090/graph 可以进到prometheus页面,粘贴我们刚才配置的promQl
(1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) *100
点击Execute 便可以查询到当前node的内存占用率
mkdir /home/prometheus/grafana
chmod 777 -R /home/prometheus/grafana
docker run -d -p 3000:3000 --name=grafana -v /home/prometheus/grafana:/var/lib/grafana grafana/grafana
启动成功后,可访问http://ip:3000/ 若访问到登录页面,则启动正常。
import按钮并输入8919 加载即可。然后就可以看到我们配置的面板啦!
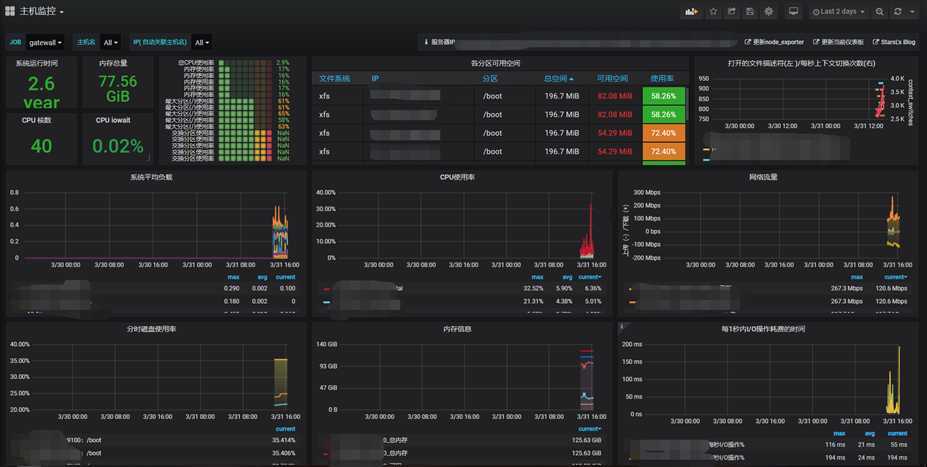
下一篇我们来介绍prometheus的告警
原文:https://www.cnblogs.com/heyouxin/p/12606104.html