解析html文件,xml文件的工具
解析,维护,遍历标签‘树’的功能库
(1)引入:
from bs4 import BeautifulSoup soup = BeautifulSoup(‘a.html‘, ‘html.parser‘)
其中第二个入参为解析器,目前有四种
1.bs4的html解析器:‘html.parser’
2.lxml的html解析器:‘lxml’ (pip install lxml)
3.lxml的xml解析器:‘xml’ (pip install lxml)
4.html5lib的解析器:‘html5lib’ (pip install html5lib)
(2)基本元素
Tag 标签,最基本的信息组织单元,分别用<> </>标明开头和结尾,BeautifulSoup.tag
Name 标签的名字,<p>.....</p>的名字是‘p‘,格式<tag>.name
Attributes 标签的属性,字典形式组织,格式 <tag>.attrs
NavigableString 标签内非属性字符串,<>...</>中字符串,格式<tag>.string
Comment 标签内字符串的注释部分,一种特殊的Comment类型 <tag>.string
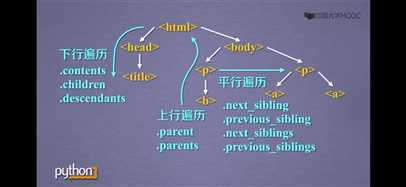
(3)html的遍历
#遍历儿子节点 for child in soup.body.children: print(child) #遍历子孙节点 for child in soup.body.descendants: print(child)
#遍历后续节点 for sibling in soup.a.next_siblings: print(sibling) #遍历前序节点 for sibling in soup.a.previous_siblings: print(sibling)
(4) soup.pretiffy()美化html
(5)find_all 代码
1 def filter_rule(): 2 # rule地址 3 url = ‘http://xxxxx/rul‘ 4 5 try: 6 response = requests.get(url) 7 response.raise_for_status() 8 except Exception as e: 9 print("获取时发生错误") 10 raise e 11 12 soup = BeautifulSoup(response.text, ‘html.parser‘) 13 for tr in soup.find_all(‘td‘, {‘class‘:‘rule_cell‘}): 14 rule = tr.contents[3].contents[0] 15 rule = rule.replace(‘\n‘,‘‘) 16 rule = rule.replace(‘\t‘, ‘‘)
print(rule)
python处理网页内容的第三方包-BeautifulSoup
原文:https://www.cnblogs.com/yiyi8/p/12605371.html