关于levelOrder的遍历,如果说不需要分层的话,我已经做好了,代码如下:
public void levelOrder()
{
levelOrder(root);
}
public void levelOrder(Node node)
{
Queue<Node> q=new LinkedList<>();
q.add(node);
while(!q.isEmpty())
{
Node n=q.remove();
System.out.println(n.value);
if(n.left!=null)
q.add(n.left);
if(n.right!=null)
q.add(n.right);
}
}
知识点:
1.如果说添加和删除相应的节点,那么是add和remove,也就是说我之前在讲enqueue和dequeue嘛,实际上这里的话,就是add和remove来作为queue的进队列和出队列。
2.q不为空的话,那么就一直弹出,这相应的代码。while(!q.isEmpty())

二叉搜索树层次序遍历,能够分层的这个函数参考了它的之后,做出来了:
class Solution
{
public List<List<Integer>> levelOrder(TreeNode root)
{
if(root==null)
return new ArrayList<List<Integer>>();
Queue<Pair<TreeNode,Integer>> q=new LinkedList<>();//node和integer组成pair
int level=0; //这个loopQueue可以作为bst的私有类,也可以作为这个同一个包下面的东西。
q.add(new Pair<TreeNode,Integer>(root,level)); //这里怎么去new的要看看的,new 然后要实例化这个东西的
List<List<Integer>> list=new ArrayList<List<Integer>>();//里面的话,必须对应一致?外面必须相等?
while(!q.isEmpty())
{//真正去体会,拿linkedlist来实例化到底是什么意思,需要去体会的
Pair<TreeNode,Integer> pair=q.remove();
TreeNode node=pair.getKey(); //到底是这么用pair的吗?
level=pair.getValue();
if(list.size()==level)
list.add(new ArrayList<Integer>());
list.get(level).add(node.val); //其实就相当于是二维数组的添加的意思
if(node.left!=null)
q.add(new Pair<TreeNode, Integer>(node.left,level+1)); //感觉的话,好像直接写,不去泛型的指定也可以?
if(node.right!=null)
q.add(new Pair<TreeNode, Integer>(node.right,level+1));
}
return list;
//这什么鬼pair啥意思啊
}
}
1. 这里说的是:构造新对象,new Pair去构造新对象,那么因为可以根据后面的推断其中的类型,所以说可以不写泛型的具体是什么
也就是说1和2都是可以的
Queue<Pair<TreeNode,Integer>> q=new LinkedList<>();
我觉得和上面这句话是同一个意思,因为在后面可以根据前面的类型来推断泛型的类型,所以说可以不写具体的泛型是什么
我自己认为:能写就写,就是尽可能地具化它的泛型类型。
2.Pair对应的是一个类,也就是对应的是类。那么的话就是你要添加的话,就去new相应的对象即可。
目前认为Pair这个类,其实就相当于是一个key,一个value的对应。其实就相当于是map的使用了吧。
也就是学会:Pair也可以作为map来进行使用的,具体的map我还没怎么去学。
3.queue这个东西,可以去添加一个map进去,那就相当于添加了Pair的对象进去。
4.对于二维的数组,就是直接去使用。那么二维的数组,其实和二维的list是同一种使用方法呀。
List<List<Integer>> list=new ArrayList<List<Integer>>();
而这里的意思是说,对于内层必须保持一致性,然而外层的话,你要把它的具体实现给写了。
也就是对应的这句list和arraylist的关系。
5.list.get(level).add(node.val); 得到一维的之后,往第二维添加内容 这句话能够学到这个。
6.
需要学习的地方:
1.map和pair的关系,如何去使用pair这个东西,一些好用的函数。
2.二维的list的一些对应的使用方法。
3.stack的具体实现,这里用linkedList来实现,有没有其他的实现的方法呢?
学习到的东西:
1.对于层次序遍历,使用的肯定是queue,先进先出(其实用stack也可以,只是换了个次序吧。以后自己,先进先出就用queue,先进后出就用stack)
2.对于每层,就是树状结构需要分开来的话,那么用queue。另外,需要把它的层次顺序给标明,对应地放在不同的list里面去。
3.以下这句话的含义是:如果说弹出来的level等于你当前的size,也就是说0层,你这里面是0,那么应该去new一个。
1层,你这里面是一个list 那么应该去new一个,也就是增加一个
这里教会你的是:如何随着元素的增多,去增加它的内容。
==level的话,那么就添加。
说的是二维数组 初始化,如何逐渐增加对应层级的内容。
size==level,那么就添加一个新的list进去。
if(list.size()==level)
list.add(new ArrayList<Integer>());
0层,没有list在里面,添加一个list。一层,有一个list,那么就添加一个list。如果再来一层的话,那么就不会添加了,因为已经是2了
这句代码实现的是:如何随着level的加深来增加数组的长度。
对于一些层级的东西,可以用queue和pair搭配来做。每个层级每个层级的。
学习1:
pair和map的区别。
看了一些回答,就是说pair比map更加轻量级一点的感觉。
其实也是映射之间的关系吧。都是映射来的。
自己用的时候构造pair确实方便,自己也知道怎么用pair了。
学习2:二维的list
对于多维数组:
1) int intA[][]={{1,2},{2,3},{3,4,5}};
2) int [][] intB=new int[3][5];
3) int []intC []=new int[3][];
intC[0]=new int[2];
intC[1]=new int[3];
intC[2]=new int[5];
这里是学会了二维的数组,有直接初始化的方式。
也有先分配空间再说的方法。
然后的话,也可以先声明行
int 类型的数组,数组里面又是数组,然后的话去开辟新的空间,新的3个空间
思考一下。
int a=new int[3];
表示开辟一个3的空间,a去指向它。
int []intc[]=new int[3][]意思是说,开辟3行
那么int【3】是什么含义呢?3说的是空间,
具体的还真的就不太理解了
对于这个二维数组的使用自己ok,自己知道怎么样去声明二维数组
以及二维数组,它每行的长度是可以不定的。
此外,如果是list的话,那么就是用中括号[],如果是数组的话,那么就是{}
如果使用arrayList,其实就是在使用list
List<List<String>>=new ArrayList<List<String>> ();
这样进行初始化,然后的话其中list的函数它都能够调用。
然后的话去add就行了
就是list的使用方法,就是二维list的使用方法。
然后的话list.get().add()
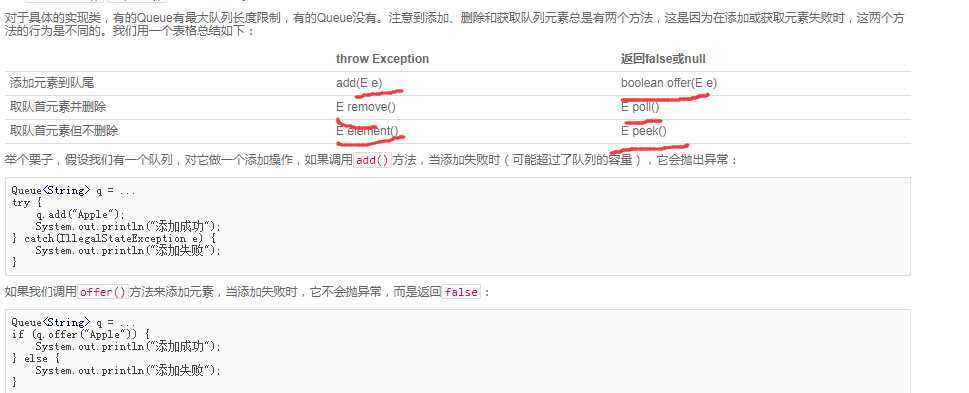
学习到的,这个Queue确实就是用linkedlist来实现最方便,最为简单。
add、remove、element可以作为取元素的方法
offer poll peek是会抛出异常的方法。
这六种方法其实都是可以的方法。
为什么说linkedlist可以作为queue的实现,因为确实就是链状的结构,就是进去的元素的感觉
然后的话如果想 先进先出,那么就是进去,然后的话remove。所以说linkedlist这种可以作为queue的实现。
你需要相应的集合,在eclipse里面的工程肯定是要import java.util.*
而如果说在这个leetcode里面是不去考虑import这些东西的。
引入loopqueue的原因:
摆脱假溢出的问题。因为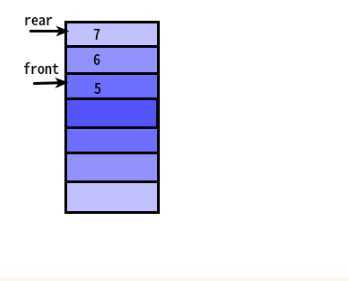
这是假的溢出。
这是因为:loopqueue这个东西,如果说你之前的进栈、出栈操作的话,如果说只是简单的front+1之类的,那么是会造成假溢出。
那么如果说我使用的方法,是去进队的时候--》正常进队 出队的时候---》那么进行元素的移动,因为出队的肯定是第一个元素,移动后面的元素的话
那么是不会有假溢出问题的。
java中同时使用implements 和extends关键字,必须先写extends后写implements
因为的话extends相当于亲爹,implements相当于干爹。那么extends肯定是更亲。所以先写这个
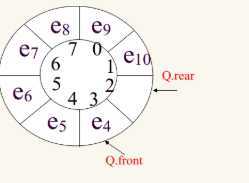
判断是不是满:
(rear+1)%length==front 则为满
rear==front 则为空
引入一个空的空间的原因:
如果不引入这个空间的话,那么满的时候不是rear==front吗,那么满和空的逻辑是相等的,对于判断是空还是满是不利的。
那么如果空,front==rear ==0对吗?其实是不对的,有可能是enqueue了一些(rear加了一些),然后dequeue(front就添加了一些)
那么的话front==rear就是空
key:出栈,就是对front动,入栈,就是对rear动。
进栈的逻辑:rear=(rear+1)%arr.length
front=(front+1)%arr.length
key:进栈这里,除以余数不是除以size ,并不是说当前的大小,而是总的容量。
length——数组的属性;
length()——String的方法;
size()——集合的方法;
也就是说:如果说你不知道这个集合的大小,去猜测用size()这个是应该的。
这里这个queue,arr=(E [])new Object[capacity+1],底层的容器,就是这个普通的数组。
然后再学一个方法,就是说:size和length的添加,size作为说当前的容量,length作为整体的容量。
这种方法是值得借鉴。
关于BST的removemin,removemax之类的,自己还缺点。现在先去看点基本的linkedlist吧。
原文:https://www.cnblogs.com/startFrom0/p/12604482.html