package main import "fmt" var ( a int = 16 ) func main() { fmt.Println(a) }
数据是放在内存中的,变量是给这块内存起的名字,有了变量就可以找到并使用这份数据。
我们知道,诸如数字、字符串、等数据都是以二进制形式存储在内存中的,它们并没有本质上的区别,那么,00010000 该理解为数字16呢,还是字符串?如果没有特别指明,我们并不知道。
也就是说,内存中的数据有多种解释方式,使用之前必须要确定;上面的int a;就表明,这份数据是整数,不能理解为像素、声音等。int 有一个专业的称呼,叫做数据类型(Data Type)。
顾名思义,数据类型用来说明数据的类型,确定了数据的解释方式,让计算机和程序员不会产生歧义。
有符号和无符号整型
按照有无符号可以分为两种,有符号整型(正整数(1,2,3,4.....)、负整数(-1,-2,-3,-4.....)各占一半),无符号整型(全是正整数)【正整数和负整数小学6年级学的】
无符号整数:
uint8、uint16、uint32、uint64
有符号整数:
int8、int16、int32、int64
这里的uint8、uint16、uint32、uint64和int8、int16、int32、int64 中的数字:8,16,32,64 分别代表的2的N次方
| 类型 | 取值范围 |
| uint8 | 8位 无符号 (0 到 255) |
| uint16 | 16位 无符号 (0 到 65535) |
| uint32 | 32位 无符号 (0 到 4294967295) |
| uint64 | 64位 无符号 (0 到 18446744073709551615) |
| int8 | 8位 有符号 (-128 到 127) |
| int16 | 16位 有符号 (-32768 到 32767) |
| int32 | 32位 有符号 (-2147483648 到 2147483647) |
| int64 | 64位 有符号 (-9223372036854775808 到 9223372036854775807) |
特殊整型
| 类型 | 取值范围 |
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
整型使用注意事项
数字字面量语法(Number literals syntax)
字面量:可以理解为某种类型的值固定表达方式,类似我们看到鸭子的模样就知道它是一只鸭子(表面的样子)
18 就是数字
"Hello World" 就是字符串
Go1.13版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:
package main import "fmt" var ( // 二进制以0b开头 a int = 0b00000001 // 八进制以0开头 b int = 071 // 十六进制以0x开头 c int = 0xABCDEF111 ) func main() { // 二进制以: 0b开头 fmt.Println(a, b, c) }
格式化输出
package main import ( "fmt" ) var ( // 十进制 a int = 100 // 二进制以0b开头 b int = 0b000000001 // 八进制以0开头 c int = 077 // 十六进制以0x开头0-9,a-f d int = 0x123abcef10 ) func main() { // 通过格式化的输出可以输出其对应的进制值 // 格式化输出使用fmt.Printf,这里面%d,%b,%o,%x,分别占用了一个位置(也就占位符),等着后面的a,b,c,d的变量值去替换 // %d 整数的占位符 // %b 二进制占位符 // %o 八进制占位符 // %x 16进制占位符 fmt.Printf("格式化输出结果:%d,%b,%o,%x\n", a, b, c, d) // 如果直接输出的话会被默认转成10进制的 fmt.Println("格式化输出结果:", a, b, c, d) }
Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准
float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。 float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64
package main import ( "fmt" ) var ( pi float64 = 3.141592653589793 ) func main() { fmt.Println(pi) }
格式化输出
package main import ( "fmt" ) var ( pi = 3.1415926111111 ) func main() { // 小数的占位符%f 默认它是保留6位小数点 fmt.Printf("格式化输出结果:%f\n", pi) // 可以通过%.2f 设置保留的小数.后面的数字,如%2.f就是保留2位小数 fmt.Printf("格式化输出结果:%.2f\n", pi) } // 格式化输出结果:3.141593 // 格式化输出结果:3.14
package main import ( "fmt" ) var z complex128 func main() { z = 3 + 2i x := real(z) y := imag(z) fmt.Println(x, y) }
Go语言提供了两种精度的复数类型:complex64和complex128,分别对应float32和float64两种浮点数精度。内置的complex函数用于构建复数,内建的real和imag函数分别返回复数的实部和虚部
复数也可以用==和!=进行相等比较。只有两个复数的实部和虚部都相等的时候它们才是相等的。 math/cmplx包提供了复数处理的许多函数,例如求复数的平方根函数和求幂函数
备注:一般情况真用不到,用到在看也不晚
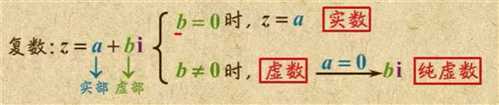
虚数的意义阮一峰有一篇文章挺好可以看下里面讲了一些应用场景应用场景
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
1 Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样
2 内部实现使用的编码为utf-8
3 字符串通过""(双引号定义),这里需要注意其他语言有双引号和单引号都标识字符串,在go里双引号和单引号数据类型不一样
4 可以通过字面量直接定义
package main import ( "fmt" ) func main() { name := "Hello World --> 你好世界" fmt.Println(name) }
字符串转义
在字符串里面,有一些特殊的字符串组合有特殊意义(转义符)需要注意下
| 转义符 | 含义 |
| \r | 回车符(返回行首) |
| \n | 换行符(直接跳到下一行的同列位置) |
| \t | 制表符 |
| \‘ | 单引号(单引号有特殊含义需要通过\,来取消它的特殊含义) |
| \" | 双引号(同上) |
| \\ | 反斜杠(同上) |
package main import ( "fmt" ) func main() { // 通过\把\转义 web := "http:\\\\www.sogou.com" fmt.Println(web) // 通过\n来重新开启一行 code := "Hello World\n你好世界" fmt.Println(code) }
多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符(`)包裹起来,并且反引号间所有的转义字符均无效,文本将会原样输出。
package main import ( "fmt" ) func main() { // 通过\把\转义 str := ` 这里并没有被转义\t测试 这里也并没有被转义\\\\n\\\hello ` fmt.Println(str) }
字符串常用操作
| 方法 | 方法描述 |
| len(str) | 字符串占用存储空间大小utf-8 字母特殊服务号占用1Byte 中文占用3~4个Byte【字符串常用操作-例子1】 |
| +或fmt.Sprintf | 字符串拼接【字符串常用操作-字符串拼接】 |
| strings.Split | 字符串切割【字符串常用操作-字符串切割】 |
| strings.contains | 判断字符串是否包含某些字符串【字符串常用操作-字符串包含判断】 |
| strings.HasPrefix,strings.HasSuffix | 判断字符串是否以某个字符开头或结尾【字符串常用操作-字符串开头或结尾判断】 |
| strings.Index(),strings.LastIndex() | 判断字符第一次出现的位置和最后一次出现的位置【字符串常用操作-获取字符出现的位置】 |
| func strings.Join(elems []string, sep string) string | 切片拼接为字符串 |
【字符串常用操作-例子1】
位: 数据存储的最小单位 bit ,我们看到的a,b,c 对我们来说他是一个符号(具有某些意义的图形)
因为计算机是美国发明的,并且计算机只有两种状态通电和断电,可以用0和1表示,用0101的组合表示不同的字符,8个0和1的组合就能表示所有英文字母和特殊符号,所以8就是这么来的
8bit(位) = 1B(字节) 1024B = 1KB 1024KB = 1MB 1024MB = 1GB
【字符串常用操作-字符串拼接】
package main import ( "fmt" ) func main() { // 字符串拼接 str1, str2 := "hello ", "世界" // 字符串拼接方法1 通过: + 号 combineStr1 := str1 + str2 fmt.Println(combineStr1) // 字符串拼接方法2 通过: combineStr2 := fmt.Sprintf("%s%s", str1, str2) fmt.Println(combineStr2) }
【字符串常用操作-字符串分隔】
package main import ( "fmt" "strings" ) func main() { // 字符串分隔 str := "hello 世 界" // Split接收两个内容第一个是你要切割的字符串,第二个填写切割字符串的规则比如我这个是根据空格符号分隔 strList := strings.Split(str, " ") fmt.Println(strList,len(strList)) }
【字符串常用操作-字符串包含判断】
package main import ( "fmt" "strings" ) func main() { // 字符串分隔 str := "hello 世界" fmt.Println(strings.Contains(str, "世界")) } // 输出结果:true 真的说明是包含的
【字符串常用操作-字符串开头或结尾判断】
package main import ( "fmt" "strings" ) func main() { str := "hello 世界" // 判断是否以: hell开头 fmt.Println(strings.HasPrefix(str, "h")) // 判断是否以: 世界结尾 fmt.Println(strings.HasSuffix(str, "世界")) }
【字符串常用操作-获取字符出现的位置】
package main import ( "fmt" "strings" ) func main() { str := "hello world!" // 以0开头的第一个o出现的位置 fmt.Println(strings.Index(str,"o")) // 以0开头最后一次o出现的位置 fmt.Println(strings.LastIndex(str, "o")) } // 输出结果:4 // 输出结果:7
组成字符串的每个元素叫做字符,如上面说过的h,l,世,界
在go中字符以:单引号(‘)
var s1 byte = ‘a‘ var s2 rune = ‘a‘
byte类型其实就unit8的别名,rune类型其实就是int32的别名
目的提高代码的可读性,一看byte和rune类型就知道处理字符类型
import ( "fmt" "go/types" ) var s1 byte = ‘a‘ var s2 rune = ‘a‘ func main() { // 通过%T可以获取变量的类型 fmt.Printf("s1:%T, s2:%T", s1, s2) } // 输出:s1:uint8, s2:int32
好奇遍历字符串
package main import "fmt" func main() { s1 := "hello 世界" fmt.Printf("字符串长度:%d\n", len(s1)) fmt.Println("字符串循环内容如下:") for i := 0; i < len(s1); i++ { fmt.Println(s1[i]) } } # 输出结果 """ 字符串长度12 字符串循环内容如下: 104 101 108 108 111 32 228 184 150 231 149 140 """
刚开始的时候很多人会蒙什么情况,算上空格才8个字符怎么输出了真么多,而且还是输出的10进制的数字
那该怎么办呢?两种方式
package main import "fmt" func main() { s := "hello 世界"
// range 方式 - 建议 for _, v1 := range s { // %v 值的默认格式表示 // %c 该值对应的unicode码值 fmt.Printf("value:%v,unicode:%c\n", v1, v1) } // 转换为rune方式 s2 := []rune(s) for b := 0; b < len(s2); b++ { fmt.Printf("value:%v,unicode:%c\n", s2[b], s2[b]) } }
修改字符串
字符串创建后就是只读的(暂时不要去深究它),如果想修改它的内容需要转换成byte或者rune类型,完成后再转换为string。无论哪种转换,都会重新分配内存。
package main import ( "fmt" ) func main() { x := "hello s" // 第一种方式先转换为byte类型 x1 := []byte(x) x1[6] = ‘1‘ // 这里注意是单引号(‘)因为我们要替换一个字符 fmt.Println(string(x1)) // 第二种方式转换为rune类型 y := "hello世界" y1 := []rune(y) y1[6] = ‘博‘ // 这里注意是单引号(‘)因为我们要替换一个字符 fmt.Println(string(y1)) }
package main import "fmt" func main() { var x float64 = 0.1 var y int = 1 var h int = 104 // 一个变量定义后,不可以重新对该变量赋值为其他类型:y = float64(y) 会报错 // 只能在表达式中进行,强制类型转换,用于执行某一段代码 c := x + float64(y) fmt.Println(c) fmt.Printf("%v,%T\n", y, y) // println也是一个表达式 fmt.Println(string(h)) }
package main import "fmt" func main() { a := 10 b := "abc" c := ‘a‘ d := 3.14 r := true //%T获取值得类型 fmt.Printf("%T, %T, %T, %T, %T\n", a, b, c, d, r) //%d 整型格式 //%s 字符串格式 //%c 使用Unicode码代表的字符展示 //%f 浮点型个数 fmt.Printf("a = %d, b = %s, c = %c, d = %f, r = %t\n", a, b, c, d, r) //%v 使用默认格式输出,自动匹配格式输出 fmt.Printf("a = %v, b = %v, c = %v, d = %v, r = %v\n", a, b, c, d, r) } // 输出为: // int, string, int32, float64, bool // a = 10, b = abc, c = a, d = 3.140000, r = true // a = 10, b = abc, c = 97, d = 3.14, r = true
格式化输出%号
package main import "fmt" func main() { a := 10 // 输出%10 fmt.Printf("%%%d", a) }
进制总结
%b 二进制表示 %d 十进制表示 %o 八进制表示 %x 十六进制表示,字母形式为小写 a-f %X 十六进制表示,字母形式为大写 A-F
原文:https://www.cnblogs.com/luotianshuai/p/12541179.html