mysql> select * from T where ID=10;
我们看到的只是输入一条语句,返回一个结果,却不知道这条语句在 MySQL 内部的执行过程。
MySQL 的基本架构示意图,从中你可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。
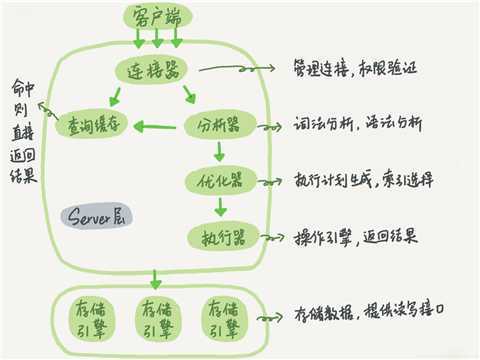
(图源https://blog.csdn.net/Megustas_JJC/article/details/84380108)
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
也就是说,你执行 create table 建表的时候,如果不指定引擎类型,默认使用的就是 InnoDB。不过,你也可以通过指定存储引擎的类型来选择别的引擎,比如在 create table 语句中使用 engine=memory, 来指定使用内存引擎创建表。
由于表经常更新,查询缓存的失效频繁,查询缓存往往利大于弊。,MySQL 8.0 版本开始直接将查询缓存的整块功能删掉了。
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。比如你执行下面这样的语句,这个语句是执行两个表的 join:
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
如果你还有一些疑问,比如优化器是怎么选择索引的,有没有可能选择错等等,没关系,我会在后面的文章中单独展开说明优化器的内容。
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示:
mysql> select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user ‘b‘@‘localhost‘ for table ‘T‘
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如我们这个例子中的表 T 中,ID 字段没有索引,那么执行器的执行流程是这样的:
至此,这个语句就执行完成了。
对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
上面是一条查询sql,再看一条SQL语句的执行过程,更新操作:
update tb_student A set A.age=‘19‘ where A.name=‘张三‘;
其实条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,mysql 自带的日志模块式binlog(归档日志),所有的存储引擎都可以使用,我们常用的InnoDB引擎还自带了一个日志模块redo log,我们就以InnoDB模式下来探讨这个语句的执行流程。流程如下:
这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?这就是之前mysql的模式了,MyISAM引擎是没有redo log的,那么我们知道它是不支持事务的,所以并不是说只用一个日志模块不可以,只是InnoDB引擎就是通过redo log来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么redo log 要引入prepare预提交状态?这里我们用反证法来说明下为什么要这么做?
如果采用redo log 两阶段提交的方式就不一样了,写完binglog后,然后再提交redo log就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设redo log 处于预提交状态,binglog也已经写完了,这个时候发生了异常重启会怎么样呢? 这个就要依赖于mysql的处理机制了,mysql的处理过程如下:
这样就解决了数据一致性的问题。
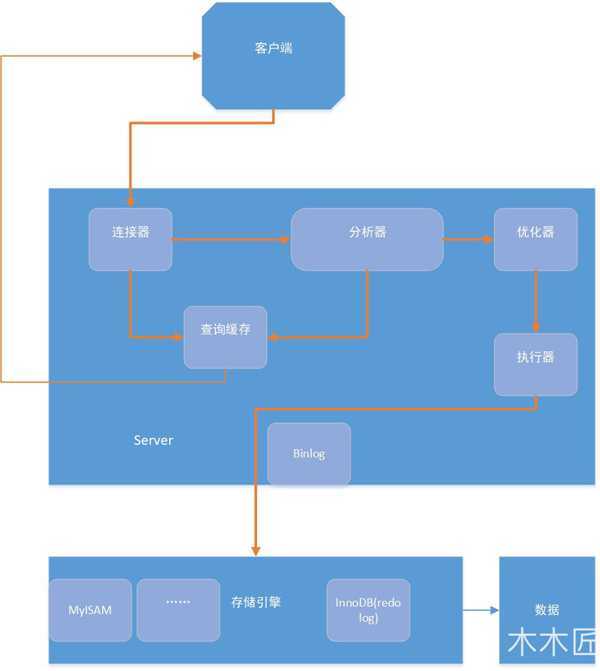
(图源https://database.51cto.com/art/201903/594091.htm)
参考链接:
1. https://database.51cto.com/art/201903/594091.htm
2. https://blog.csdn.net/Megustas_JJC/article/details/84380108
原文:https://www.cnblogs.com/lfri/p/12598339.html