文章部分图片和描述来自 : https://www.infoq.cn/article/java-memory-model-1/ 半原创。
以下的总结是个人观点不知准不准确 : 由于底层的编译器和处理器会重排序,从而使变量的可见性很模糊,而 JMM 则,提供了 happen-before 规则,也就说我只要根据规则我就可以判定该变量是不是可见的,然后要实现可见性的判断,java提供了几个词义用于保证这些可见性(或者说保证了规则的正确性) : volatile , synchronized , final ,这次的大更新在 JSR133 (当然JSR133还有很多改动和更新,具体的看文末参考资料)。
JMM 定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本。本地内存是 JMM 的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。
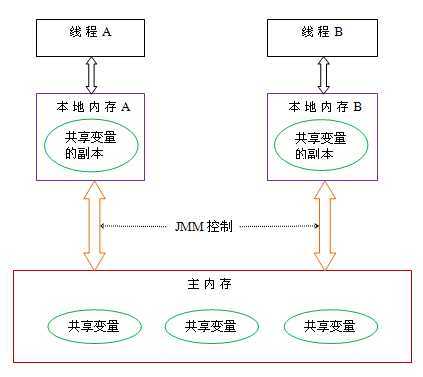
注意 : 本地内存并不真实存在,是一个抽象的概念。
我们在看上图,本地内存都是内存中的拷贝,当多线程发生读写的时候肯定就会操作错乱(例如 : 我写的还没来及回刷,你读到的是旧数据;)
以下描述来自 : https://www.infoq.cn/article/java-memory-model-1/ 非原创。
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

也就是代码的运行不一定就是按照你写代码从上到下的顺序。
上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM 的处理器重排序规则会要求 java 编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel 称之为 memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JMM 属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
所以我们可以说导致不同的处理结果有两个原因(这两个原因起码是我们知道的) :
happens-before 关系是用来描述两个操作的内存可见性的,也就是说满足什么样的条件,那么 A 就会对 B 内存可见 。如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在 happens-before 关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。 与程序员密切相关的 happens-before 规则如下:
由于 jmm 屏蔽了底层,使得程序员看到的都是一致的内存视图 :
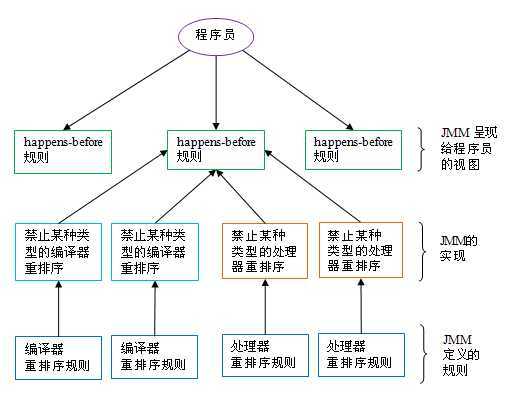
我们这里从整体知道了这个模型图,后面我们详细地介绍java是如何通过一些词义来保证可见性的,或者说是如何来保证“为什么我遵守了 happen-before 我就可以保证内存的可见性”
重排序在多线程引发的问题就像是数据库进行事务的对数据的修改一样,如何使得修改让其他线程可以,最常见就是加锁,不然其他线程操作。
我们先来看一下为什么要重排序,无疑的是重排序肯定可以提高执行程序的效率。
现代的处理器使用写缓冲区来临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读 / 写操作的执行顺序,不一定与内存实际发生的读 / 写操作顺序一致!
Processor A : a = 1; //A1 x = b; //A2 ================== Processor B : b = 2; //B1 y = a; //B2
可以看到假如 A1 和 A2 (B1 和 B2) 之间是没有什么数据依赖的(数据依赖就例如下一条的语句需要等上一条的执行完了才能执行),当多线程的情况下,就会导致问题 。
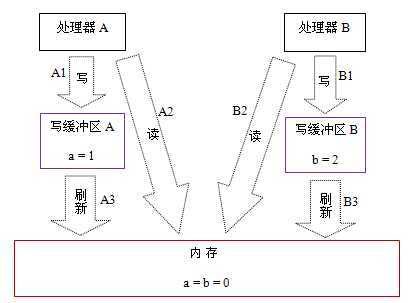
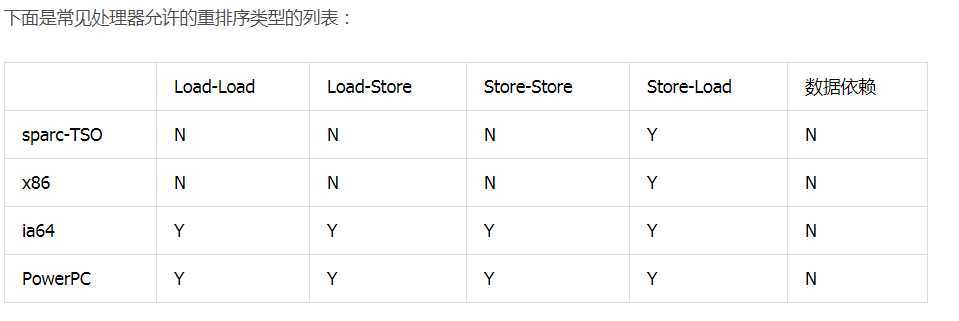
多线程读写发生的读取数据不是预期的,这里就不说明了,大家可以推导一下。 让我们来看一下处理器存在的重排操作吧。
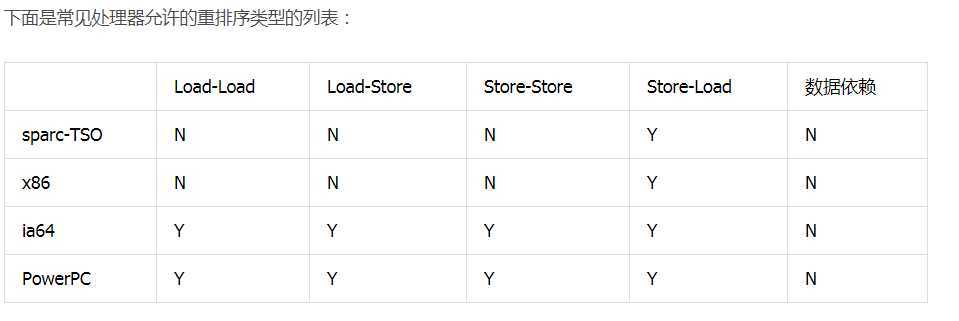
从上表我们可以看出:常见的处理器都允许 Store-Load 重排序;常见的处理器都不允许对存在数据依赖的操作做重排序。sparc-TSO 和 x86 拥有相对较强的处理器内存模型,它们仅允许对写 - 读操作做重排序(因为它们都使用了写缓冲区)。
为了保证内存可见性,java 编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM 把内存屏障指令分为下列四类:
StoreLoad Barriers 是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
几个非常有意思的问题,可以帮助我们理解jmm ,阅读 http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html 。
The Java Memory Model describes what behaviors are legal in multithreaded code, and how threads may interact through memory. It describes the relationship between variables in a program and the low-level details of storing and retrieving them to and from memory or registers in a real computer system. It does this in a way that can be implemented correctly using a wide variety of hardware and a wide variety of compiler optimizations.
Java includes several language constructs, including volatile, final, and synchronized, which are intended to help the programmer describe a program‘s concurrency requirements to the compiler. The Java Memory Model defines the behavior of volatile and synchronized, and, more importantly, ensures that a correctly synchronized Java program runs correctly on all processor architectures.
以下是笔者渣渣翻译,如有不准确还望指出。
java memory model 描述了什么样的行为在多线程编程当中是合法的,还有多线程在内存中是如何进行交互的, 它描述了程序中的变量和底层变量的关系,底层变量指的是在实际计算机系统中的存储器或寄存器之间进行存储和检索的信息。 java 包含了几个语言相关的指令,包括 volatile , final和 synchronized , 这些指令帮助编程者构建对于编译器所需要的并发要求。 java memory model 定义了 volatile 和 synchronized 的行为,更重要的是,保证运行在所有处理器架构的java程序都是正确的同步的。
大部分其他语言,像 c++ 或是 c ,并没有设计对多线程的直接支持,它们阻止发生在编译器和机器架构的重排序严重地依赖于 并发线程库的提供,编译器的使用还有代码运行的体系。
文章从整体介绍了jmm存在的动机,从而引出了 happen-before 这个规则,接着介绍了防止重排序在处理器中使用的栅栏(barrier).
jmm 系列优秀博客推荐 : (共七篇)
JSR 133 相关 :
其他
原文:https://www.cnblogs.com/Benjious/p/12598073.html