如何挑选深度学习 GPU?
深度学习是一个对计算有着大量需求的领域,从一定程度上来说,GPU的选择将从根本上决定深度学习的体验。因此,选择购买合适的GPU是一项非常重要的决策。那么2020年,如何选择合适的GPU呢?这篇文章整合了网络上现有的GPU选择标准和评测信息,希望能作为你的购买决策的参考。
1 是什么使一个GPU比另一个GPU更快?
有一些可靠的性能指标可以作为人们的经验判断。以下是针对不同深度学习架构的一些优先准则:
Convolutional
networks and Transformers: Tensor Cores > FLOPs >
Memory Bandwidth > 16-bit capability
Recurrent
networks: Memory Bandwidth > 16-bit capability >
Tensor Cores > FLOPs
2 如何选择NVIDIA/AMD/Google
NVIDIA的标准库使在CUDA中建立第一个深度学习库变得非常容易。早期的优势加上NVIDIA强大的社区支持意味着如果使用NVIDIA GPU,则在出现问题时可以轻松得到支持。但是NVIDIA现在政策使得只有Tesla GPU能在数据中心使用CUDA,而GTX或RTX则不允许,而Tesla与GTX和RTX相比并没有真正的优势,价格却高达10倍。
AMD功能强大,但缺少足够的支持。AMD GPU具有16位计算能力,但是跟NVIDIA GPU的Tensor内核相比仍然有差距。
Google
TPU具备很高的成本效益。由于TPU具有复杂的并行基础结构,因此如果使用多个云TPU(相当于4个GPU),TPU将比GPU具有更大的速度优势。因此,就目前来看,TPU更适合用于训练卷积神经网络。
3 多GPU并行加速
卷积网络和循环网络非常容易并行,尤其是在仅使用一台计算机或4个GPU的情况下。TensorFlow和PyTorch也都非常适合并行递归。但是,包括transformer在内的全连接网络通常在数据并行性方面性能较差,因此需要更高级的算法来加速。如果在多个GPU上运行,应该先尝试在1个GPU上运行,比较两者速度。由于单个GPU几乎可以完成所有任务,因此,在购买多个GPU时,更好的并行性(如PCIe通道数)的质量并不是那么重要。
4 性能评测
1)来自Tim Dettmers的成本效益评测
[1]
https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/
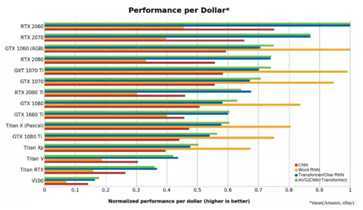
卷积网络(CNN),递归网络(RNN)和transformer的归一化性能/成本数(越高越好)。RTX 2060的成本效率是Tesla V100的5倍以上。对于长度小于100的短序列,Word RNN表示biLSTM。使用PyTorch 1.0.1和CUDA 10进行基准测试。
从这些数据可以看出,RTX 2060比RTX 2070,RTX 2080或RTX 2080 Ti具有更高的成本效益。原因是使用Tensor Cores进行16位计算的能力比仅仅拥有更多Tensor Cores内核要有价值得多。
2)来自Lambda的评测
[2,3]

GPU平均加速/系统总成本
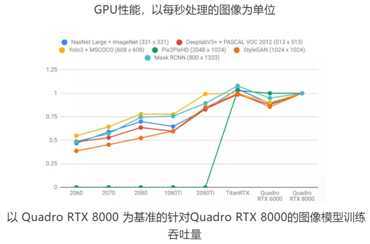
GPU性能,以每秒处理的图像为单位
以 Quadro RTX
8000 为基准的针对Quadro RTX 8000的图像模型训练吞吐量
3)
来自知乎@Aero的「在线」GPU评测
[4]
https://www.zhihu.com/question/299434830/answer/1010987691
大家用的最多的可能是Google Colab,毕竟免费,甚至能选TPU
不过现在出会员了:

免费版主要是K80,有点弱,可以跑比较简单的模型,有概率分到T4,有欧皇能分到P100。
付费就能确保是T4或者P100,一个月10美元,说是仅限美国。
Colab毕竟是Google的,那么你首先要能连得上google,并且得网络稳定,要是掉线很可能要重新训练,综合来看国内使用体验不太好。
下一个是百度AI Studio:
免费送V100时长非常良心,以前很多人自己装tensorflow用,但是现在已经不允许了,实测tensorflow pytorch都不给装,必须得用paddlepaddle。那么习惯paddlepaddle的用户完全可以选这个,其他人不适合。
不过似乎GPU不太够,白天一直提醒高峰期,真到了22点后才有。
国外的还有vast.ai:
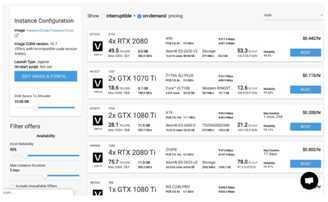
5 建议
1)来自Tim Dettmers的建议
2)来自Lambda的建议
截至2020年2月,以下GPU可以训练所有SOTA语言和图像模型:
具体建议:
原文:https://www.cnblogs.com/wujianming-110117/p/12594314.html