Python的正则表达式的大部分功能主要使用re模块,该模块使Python语言拥有全部的正则表达式功能。
首先只介绍本篇文章所用到的,也就是常见的正则匹配规则:
\w 匹配字母、数字、下划线
\W 匹配非字母、数字、下划线
\s 匹配任意空白字符,等价于[\t\n\r\f]
\S 匹配任意非空字符
\d 匹配任意数字,等价于[0-9]
\D 匹配任意非数字的字符
\A 匹配字符串开头
\Z 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串
\z 匹配字符串结尾,如果存在换行,同时还会匹配换行符
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配一行字符串的开头
$ 匹配一行字符串的结尾
. 匹配任意字符,除换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符串
* 匹配0个或多个表达式
+ 匹配1个或多个表达式
? 匹配0个或1个前面的表达式定义的片段,非贪婪模式
{n} 精确匹配n个前面的表达式
( ) 匹配括号内的表达式,也表示一个组
re.match(pattern, string, flags=0)
#pattern为要匹配的正则表达式,string为要匹配的字符串,flags为标志位,用于控制正则表达式的匹配方式。
其中第三个参数(flags)标志位可以包含一些可选标志位符来控制匹配的模式,多个标志位符可以通过“|”来指定。
re.I 使匹配对大小写不敏感
re.S 使 . 匹配包括换行在内的所有字符
re.M 多行匹配,影响 ^ 和 $
re.match()是从字符串的起始位置匹配一个模式,如果不是起始位置匹配的话,match()会返回一个none。re.match()返回的结果是一个对象,而不是匹配的字符串。group()函数sapn()函数re.match()函数是从原字符串的起始位置开始匹配,所以这就注定了该函数只能够进行一些简单的字符串验证,而不适合提取,所以应用场景有限,比如应用于登录注册所输入的字符串有效性检测。content = ‘Hello 123 4567 World_This is a Regex Demo‘
result1 = re.match(‘Hello\s\d{3}\s\d{4}\s\w{10}‘, content)
# \d表示匹配任意数字,\d{3}表示精准匹配3个前面的任意数字 \s表示匹配空白字符
# 方便一点的话可以将\s去除,用普通空格替代:
# result1 = re.match(‘Hello \d{3} \d{4} \w{10}‘, content)
print(result1)
print(result1.group())
print(result1.span())
输出:
<re.Match object; span=(0, 25), match=‘Hello 123 4567 World_This‘>
Hello 123 4567 World_This
(0, 25)
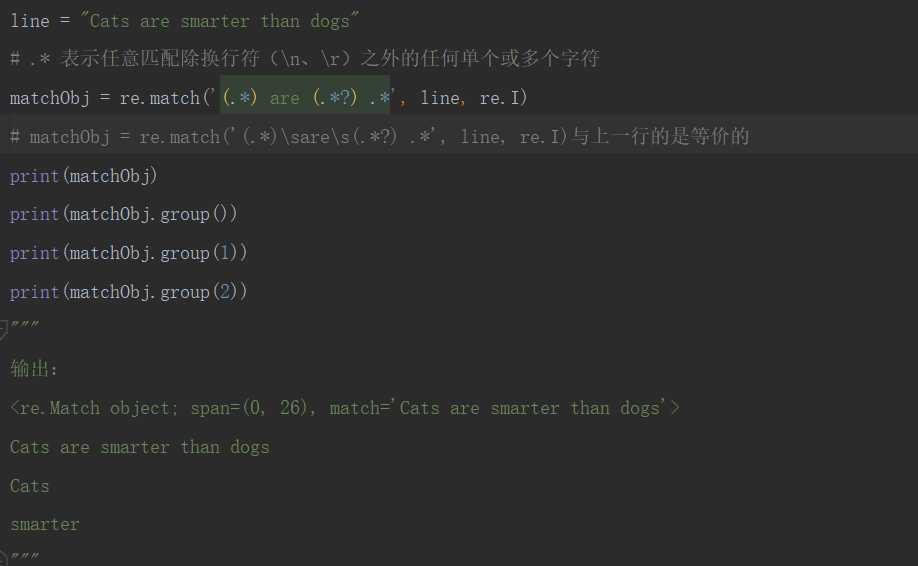
可以看出匹配中group(1)和group(2)的内容分别是第一个和第二个括号内所匹配的内容
而group(0)则是匹配出的完整的字符串
re.search(pattern, string, flags=0) #其参数的含义与re.match()参数的含义是一样的,在这里不再赘述
match的区别是:re.match()只匹配字符串的开始,如果字符串的第一个字符串就不符合正则表达式,则匹配失败,函数返回None, 而re.search()是搜索整个字符串直到找到一个匹配。search函数依旧不适用于提取某某个字符串,它与match类似,只匹配一次,即在整个字符串中寻找,如果找到则立马停止,并输出结果,与接下来介绍的re.compile()做出区分line = "Cats are smarter than dogs"
matchObj1 = re.match(r‘dogs‘, line, re.M | re.I)
if matchObj1:???
print(matchObj1.group())
else:???
print("No match!!")
matchObj2 = re.search(r‘dogs‘, line, re.M | re.I)
print(matchObj2.group())
# 输出:
No match!!
dogs
re.compile(pattern[, flags])
这将生成一个正则表达式(Pattern)对象
re.findall(string[, pos[, endpos]])s = ‘A B C D‘
# 提取[‘A B‘, ‘C D‘]
result1 = re.compile(‘(\w+\s+\w?)‘).findall(s)
# 提取[‘A ‘, ‘C ‘]
result2 = re.compile(‘(\w+\s+)\w?‘).findall(s)
# 提取[(‘A‘, ‘B‘), (‘C‘, ‘D‘)]
result3 = re.compile(‘(\w+)\s(\w+)‘).findall(s)
可以参见一篇文章:Python3正则表达式(三)贪婪模式与非贪婪模式
可以参见下面的例子:
html = ‘‘‘???
<html>???????
<div>???????????
<book>
<p>c语言</p>
</book>???????
</div>???????????
<div>???????????
<book>???????????????
<p>Python程序设计</p>???????????
</book>???????
</div>???
</html>‘‘‘
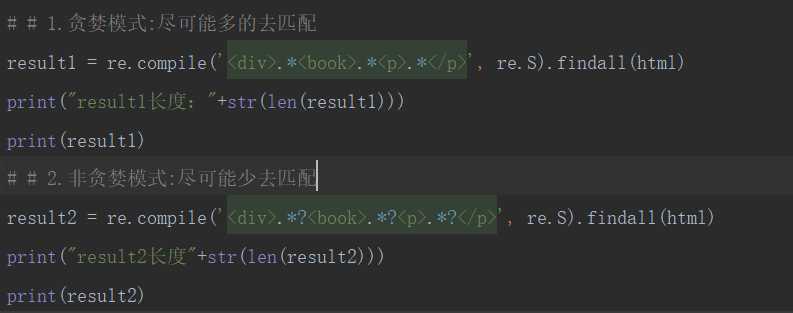
输出:

注意:有的时候会写成result2 = re.compile(r‘(\w+\s+)\w?‘).findall(s)
关于字母r的作用可以理解成是raw字符串的意思,其设计本身就是为了方便正则表达式的使用的,可以参见文章:
python正则表达式中原生字符r的作用
大致的意思就是说在match或者compile中如果不使用r需要使用四个‘\‘才能表示‘\‘,而使用r只需要使用两个反斜杠‘\‘
mm = "c:\\a\\b\\c"
print(mm)?? # 输出c:\a\b\c
result = re.match(r"c:\\a", mm).group()
print(result)? # 输出c:\a
原文:https://www.cnblogs.com/haoocker/p/12574306.html