文章内容主要来自cyc大佬的开源项目(项目地址),然后结合自己的面试学习情况做了点补充。从简单的内容开始,希望自己能养成写博客的好习惯吧。
| 数据类型 | byte | char | short | int | float | long | double | boolean |
|---|---|---|---|---|---|---|---|---|
| 大小(bit) | 8 | 16 | 16 | 32 | 32 | 64 | 64 | (未明确规定) |
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
int y = x; // 拆箱 调用了 X.intValue()
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // true
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
编译器会在自动装箱过程调用valueOf()方法,因此多个值相同且值在缓存池范围内的 Integer实例使用自动装箱来创建,那么就会引用相同的对象。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
在 jdk 1.8 所有的数值类缓冲池中,Integer 的缓冲池 IntegerCache 很特殊,这个缓冲池的下界是 - 128,上界默认是 127,但是这个上界是可调的,在启动 jvm 的时候,通过 -XX:AutoBoxCacheMax=
String 被声明为 final,因此它不可被继承。
在 Java 8 中,String 内部使用 char 数组存储数据(Java 9 之后使用byte 数组)。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
}
value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的key。不可变的特性可以使得hash值也不可变,因此只需要进行一次计算。
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
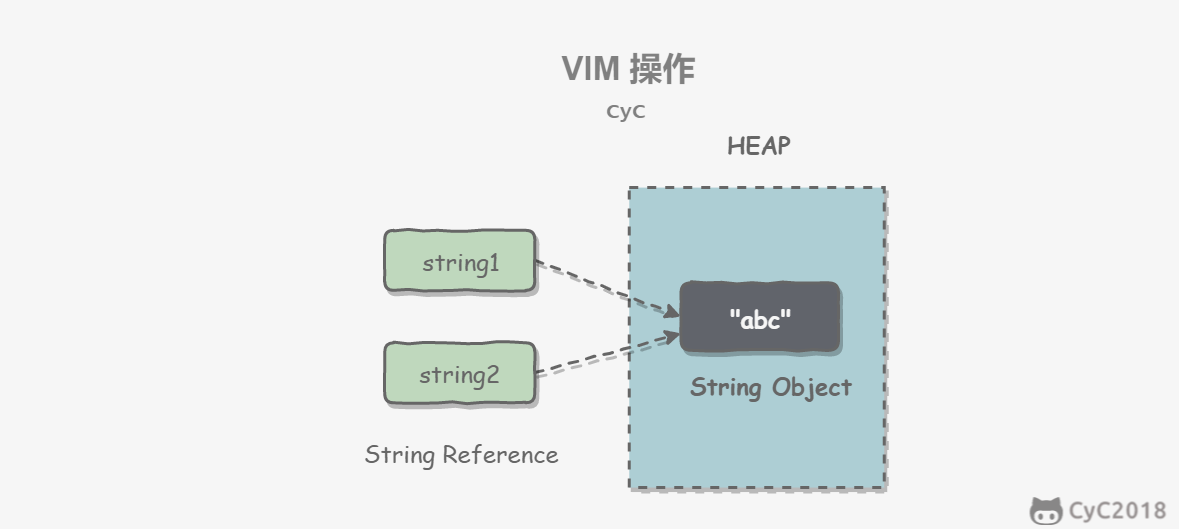
String 经常作为参数,String不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果String是可变的,那么在网络连接过程中,String 被改变,改变String对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程中将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 方法取得一个字符串引用。intern() 首先把 s1 引用的字符串放到 String Pool 中,然后返回这个字符串引用。因此 s3 和 s4 引用的是同一个字符串。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true
如果是采用"bbb"这种字面量的形式创建字符串,自动将字符串放入 String Pool 中。(字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算是在运行时进行的,新创建的字符串存放在堆中)
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。(若pool没有字符串,1.7前: intern后将字符串复制到pool;1.7:将heap中字符串的引用放入pool)
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
以下是 String 构造函数的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造函数参数时,并不会完全复制 value 数组内容,而是都会指向同一个 value 数组。
Java 的参数是以值传递的形式传入方法中,而不是引用传递。
在方法中使指针引用其它对象,那么这两个指针此时指向的是完全不同的对象,在一方改变其所指向对象的内容时对另一方没有影响。如果在方法中改变对象的字段值会改变原对象该字段值,因为改变的是同一个地址指向的内容。
Java 不能隐式执行向下转型,因为这会使得精度降低。(1.1 字面量属于 double 类型,不能直接将 1.1 直接赋值给 float 变量;字面量 1 是 int 类型,因此不能隐式地将 int 类型下转型为 short 类型。)
但是使用 += 或者 ++ 运算符可以执行隐式类型转换。
上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
short s1 = 1;
// s1 = s1 + 1;
但是使用 += 或者 ++ 运算符会执行隐式类型转换。
s1 += 1;
s1++;
上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
s1 = (short) (s1 + 1);
public > protect > default(friendly) > private(范围)
protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
如果子类的方法重写了父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以使用父类实例的地方都可以使用子类实例,也就是确保满足里氏替换原则。
字段决不能是公有的,因为这么做的话就失去了对这个字段修改行为的控制,客户端可以对其随意修改。例如下面的例子中,AccessExample 拥有 id 公有字段,如果在某个时刻,我们想要使用 int 存储 id 字段,那么就需要修改所有的客户端代码。
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
抽象类和普通类最大的区别是,抽象类不能被实例化,需要继承抽象类才能实例化其子类。
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。
接口的字段默认都是 static 和 final 的。
使用接口:
使用抽象类:
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
为了满足里式替换原则,重写有以下三个限制:
使用 @Override 注解,可让编译器帮忙检查是否满足上面的三个限制条件。
在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有查找到再到父类中查看,看是否有继承来的方法。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
hashCode() 返回散列值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价。
在覆盖equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等。(何时覆盖:希望对象内容一致时便判定对象等价)
新建两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象,但是如果没有实现 hasCode() 方法,那么这两个对象的散列值是不同的,最终会导致集合添加了两个等价的对象。
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
拷贝对象和原始对象的引用类型引用同一个对象(不复制它所引用的对象)。
拷贝对象和原始对象的引用类型引用不同对象。
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
声明类不允许被继承。
常用于工具类和程序中的常用的变量。
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。
只能访问所属类的静态字段和静态方法,方法中不能this和super关键字。
静态语句块在类初始化时运行一次。
非静态内部类依赖于外部类的实例,而静态内部类不需要。
静态内部类不能访问外部类的非静态的变量和方法。
在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
存在继承的情况下,初始化顺序为:
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
反射的优点:
反射的缺点:
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
通配符:有两种限定通配符,一种是<? extends T>它通过确保类型必须是T的子类来设定类型的上界,另一种是<? super T>它通过确保类型必须是T的父类来设定类型的下界。另外<?>表示了非限定通配符,因为<?>可以用任意类型来替代。
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
注解通过 @interface关键字进行定义。
元注解有以下几个:
说明了这个注解的的存活时间
作用是能够将注解中的元素包含到 Javadoc 中去
指定了注解运用的地方。
如果一个超类被 @Inherited 注解过的注解进行注解的话,那么如果它的子类没有被任何注解应用的话,那么这个子类就继承了超类的注解。
注解的值可以同时取多个
Lambda其实就是一个匿名函数,Lambda允许将函数作为一个方法的参数,传递进方法当中,我们就把Lambda表达式理解为一个可以传递的代码,这样写出来的代码,就可以做到简洁、灵活。
上面我们接触到了函数式接口这个名词,实际上,上面讲的Lambda表达式需要函数式接口的支持,也就是Lambda表达式的对函数式接口中的方法进行了实现。下面了解一下函数式接口。
四大函数式接口,消费型接口Consumer<T>,供给型接口Supplier<T>,函数型接口Function<T,R>,断言型接口Predicate<T>
射等数据操作。Stream的出现使得对数据源的操作更加高效。Stream是操作数据源(集合、数组等)所生成的元素序列,它不会存储数据,而是对数据进行操作,该操作并不会改变源数组,而是返回一个操作后的一个结果Stream。Stream操作的特点是延迟执行。意味要等到需要结果的时候才会执行,也称“惰性求值”。
操作基本流程:
允许接口中具有具体实现的方法,称该方法为“默认方法”,默认方法的关键字使用default关键字修饰。(类优先原则、接口冲突)
接口允许添加静态方法,这样我们使用接口中方法就可以直接使用接口名.静态方法名调用接口中的方法。
以上可以都看成语法层面,还有两方面可以阐述:JVM层面,方法区的实现由永久代?元空间(静态变量常量池移入堆);API实现层面,包括HashMap(hash函数、扩容方式、红黑树)和ConcurrentMap(CAS+Synchronized)实现。
未实现阻塞接口
实现阻塞接口
在java中Class.forName()和ClassLoader都可以对类进行加载。ClassLoader就是遵循双亲委派模型最终调用启动类加载器的类加载器,实现的功能是“通过一个类的全限定名来获取描述此类的二进制字节流”,获取到二进制流后放到JVM中。Class.forName()方法实际上也是调用的ClassLoader来实现的。
区别:默认情况下,Class.forName()方法加载类后,还会对类进行初始化,而ClassLoader只进行类的加载(在newInstance中才执行初始化操作)。
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外的接口使其与外部发生联系。用户无需关心对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
继承实现了 IS-A 关系,例如 Cat 和 Animal 就是一种 IS-A 关系,因此 Cat 可以继承自 Animal,从而获得 Animal 非 private 的属性和方法。
继承应该遵循里氏替换原则,子类对象必须能够替换掉所有父类对象。
Cat 可以当做 Animal 来使用,也就是说可以使用 Animal 引用 Cat 对象。父类引用指向子类对象称为向上转型 。
多态分为编译时多态和运行时多态:
运行时多态有三个条件:
可以,但在应用的时候,需要用自己的类加载器去加载,否则,系统的类加载器永远只是去加载 jre.jar 包中的那个java.lang.String。
原文:https://www.cnblogs.com/cjInsist/p/12563414.html