一般情况下,题目所给的数据总可能会缺漏了一些,这时候怎么处理这些数据将变得很棘手,因为这个数据的缺失是否会对结果造成影响我们不得而知,所以我们要掌握几种解决方法。
一:缺失值的处理
1.简单暴力,把缺失值的那一列全部删除
如果我们在这个属性上面缺失了值,我们不讨论它不就行了吗,虽然可能会忽略了这个属性对结果造成的影响,但是总比因为缺失数而预测结果错误来的好。
缺点:如果缺失值太多,最终删除到没有什么数据了。那就不好办了。

# 获取缺少值的列名称 cols_with_missing = [col for col in X_train.columns if X_train[col].isnull().any()] # 删除训练和验证数据中的列 reduced_X_train = X_train.drop(cols_with_missing, axis=1) reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
2.不进行删除,转而通过求值来填补这个数据
(1)均值法
求平均值出来,总会有点说服力吧。
缺点:改变了数据的分布,比如数据呈正态分布,这时候就造成很大的误差。
(2)随机填补
缺点:不靠谱,纯看人品。
from sklearn.impute import SimpleImputer # 填充 my_imputer = SimpleImputer() imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train)) imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
fit_transform和transform的区别可在网上查得,大概是这么个关系:
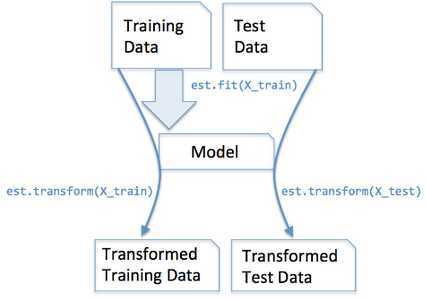
3.填充扩展
如同2(1)方法,求出平均值填补过后,再新增一列用于记录哪条数据是缺失填充的。
如:
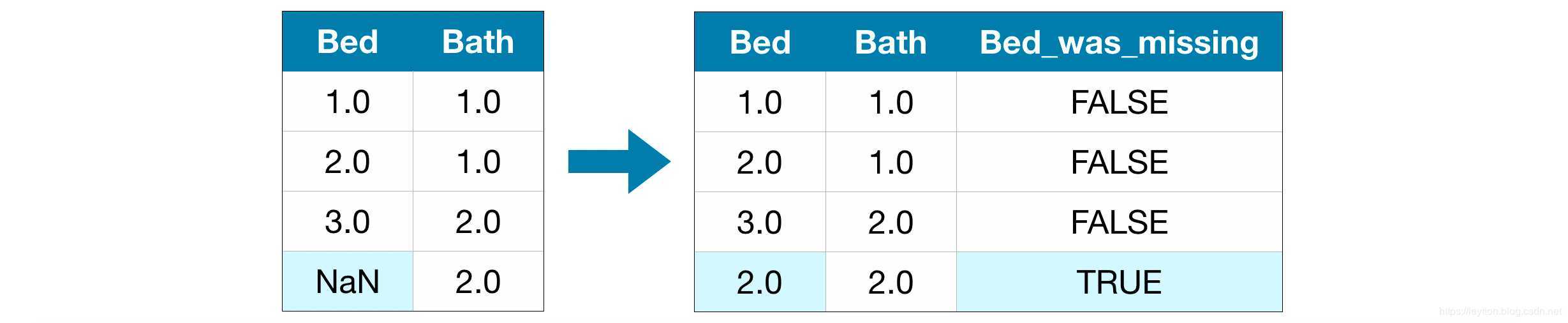
在这种情况下,模型将考虑哪些值是最初丢失的,从而做出更好的预测。
缺点:某些情况,这没有一点用,比如某种属性对结果没什么影响,就算这么做了也不会有用。
for col in cols_with_missing: X_train_plus[col + ‘_was_missing‘] = X_train_plus[col].isnull() X_valid_plus[col + ‘_was_missing‘] = X_valid_plus[col].isnull() # Imputation my_imputer = SimpleImputer() imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus)) imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
还有很多种高级方法:https://www.cnblogs.com/xiaohuahua108/p/6237906.html
to be continued……
原文:https://www.cnblogs.com/Y-Knightqin/p/12553259.html
