? 在计算机中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现几率的方法得到的,出现几率高的字母使用较短的编码,反之出现几率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
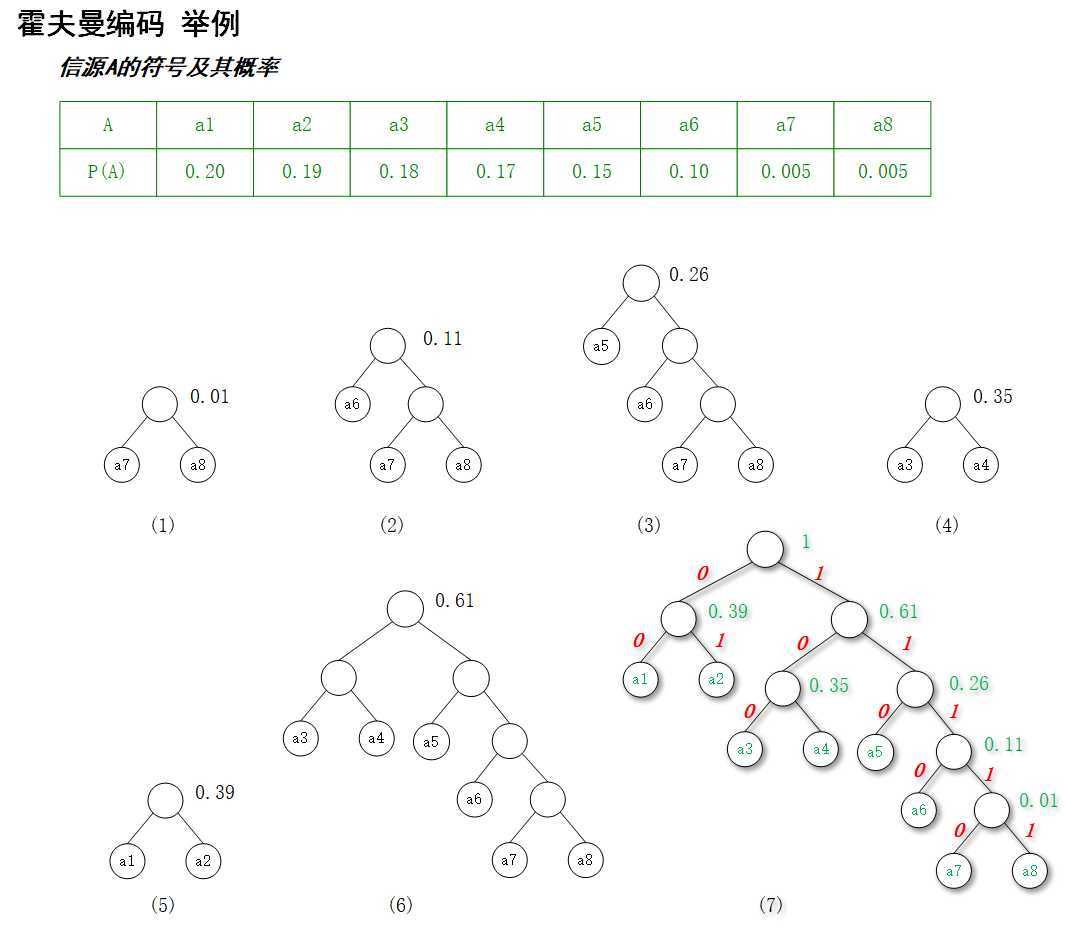
最后形成的编码:
| 符号 | a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 |
|---|---|---|---|---|---|---|---|---|
| 码字 | 00 | 01 | 100 | 101 | 110 | 1110 | 11110 | 11111 |
| 码长 | 2 | 2 | 3 | 3 | 3 | 4 | 5 | 5 |
平均码长:$$L=\sum_{i=1}^{8}P(a_i)*l_i=2.73$$
信息熵:$$H(A)=-\sum_{i=1}^{8}P(a_i)*log_2P(a_i)=2.618$$
可以看出挺接近信息熵的了。
形成的编码可能不是唯一的,左0右1还是左1右0随便。
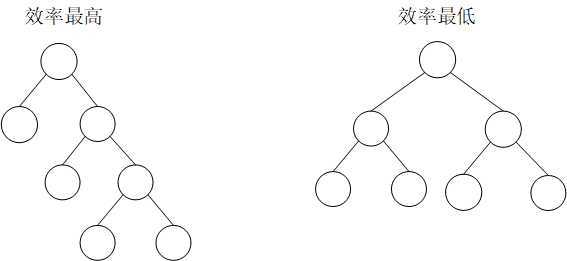
对于信源概率相差大时,效率较高,当信源概率为 \(2^{-1},2^{-2}\dots\) 时,效率最高。
对于信源概率相等时,效率最低。
编码后,形成霍夫曼编码表,解码时需参照此表,此表在存储和传输时都会占用一定的信道。
原文:https://www.cnblogs.com/seigann/p/12549174.html