
作者视频讲解:https://www.youtube.com/watch?v=WWWQXTb_69c&feature=youtu.be&t=20s
分布式训练的瓶颈为同步梯度和参数的高网络通信成本。在论文中,我们提出了三元梯度来加速分布式学习。只需要一个三元数组{-1,0,1}就可以减少通信时间。在梯度有界的前提下,我们数学证明了TerGrad的收敛性。在边界指导下,我们提出了分层的三元化和梯度裁剪来提高收敛性。实验证明可以提升准确性。
训练大规模模型的数据经常采用分布式系统。SGD通常作为优化算法,由于其高计算效率。
同步SGD:
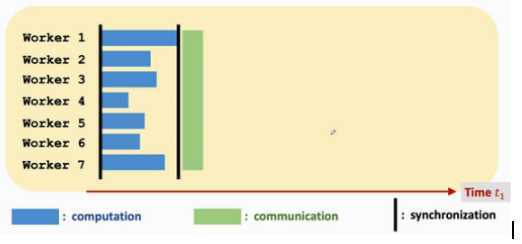
缺点:延长通信时间
异步SGD:
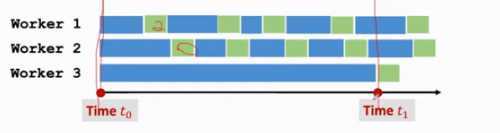
缺点:降低模型精度
目前加速分布式训练最常使用的是稀疏性和量化技术。
源码链接://download.csdn.net/download/weixin_45428522/12264387
PPT链接://download.csdn.net/download/weixin_45428522/12264378
【论文学习8】TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning
原文:https://www.cnblogs.com/20189223cjt/p/12551296.html