a、解决冷启动问题。
b、搜索引擎的根基:做搜索引擎少不了爬虫。
c、建立知识图谱,帮助建立机器学习知识图谱。
d、可利用爬取的数据制作比价软件
f、秒杀,抢票等个人用途
通用爬虫:就是将互联网上的数据整体爬取下来保存到本地的一个爬虫程序,是搜索引擎的重要组成部分。
搜索引擎:就是运用特定的算法和策略,从互联网上获取页面信息,并将信息保存到本地为用户提供检索服务的系统。
搜索引擎工作步骤
第一步:抓取网页(抓取url来自哪里?)
? a、新网站会主动提交。
? b、在其他网站设置的外链也会加入到待爬取的url队列里面。
? c、和dns服务商合作,如果有新网站成立,搜索引擎就会获取网址。
第二步:保存数据
第三步:预处理
第四步:提供检索服务,网站排名
搜索引擎的局限性
聚焦爬虫:在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
(1)robots协议
? 定义:网络爬虫排除标准
? 作用:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
? 将来写爬虫程序我们要规避robots协议即可。
(2)网站地图sitemap
? sitemap 就是网站地图, 它通过可视化的形式, 展示网站的主要结构。
? 网上有很多sitemap生成网站:https://help.bj.cn/
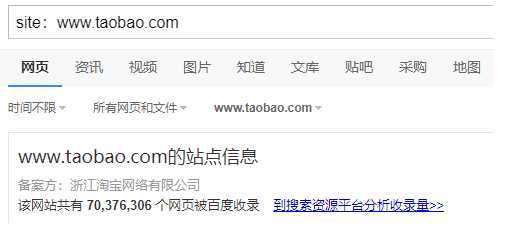
(3)估算网站的大小
? 可以使用搜索引擎来做,比如在百度中搜索 site:www.taobao.com
http协议:HyperText Transfer Protocol,超文本传输协议,是一种收发html的规范。
HTTPS (Hypertext Transfer Protocol over Secure Socket Layer)简单讲是http的安全版,在http下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
加密技术
http协议的特点:
? (1)应用层协议。
? (2)无连接:http协议每次发送请求都是独立的。http 1.1以后有一个头:connection:keep_alive.
? (3)无状态:http协议不记录状态,进而产生了两种记录http状态的技术:cookie和session。
url:统一资源定位符
from urllib.parse import urlparse
print(urlparse(‘https://www.baidu.com/s?wd=python&rsv_spt=1#3‘))
‘‘‘
ParseResult(scheme=‘https‘, netloc=‘www.baidu.com‘, path=‘/s‘, params=‘‘, query=‘wd=python&rsv_spt=1‘, fragment=‘3‘)‘‘‘
http工作过程
客户端发送请求
url只是表示资源位置,而http请求则可以进行数据提交,获取与删除等。。
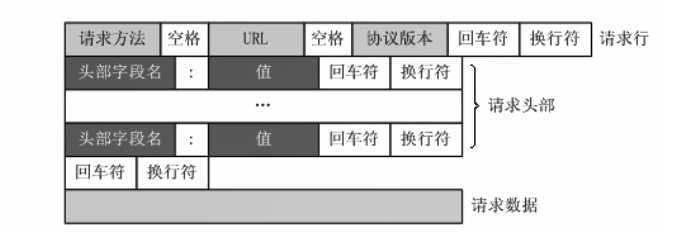
请求头格式
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36
Sec-Fetch-Dest: document
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: BIDUPSID=FC48EB3E32989D00B48FE188F0D18E29; PSTM=1575894403; BAIDUID=FC48EB3E32989D00F7BFCA9AF76D009A:FG=1; BD_UPN=12314753; sug=3; ORIGIN=2; bdime=0;
请求方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
服务器响应
响应头
HTTP/1.1 200 OK
Bdpagetype: 2
Bdqid: 0xca03f14700105a2b
Cache-Control: private
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Fri, 20 Mar 2020 14:22:33 GMT
Expires: Fri, 20 Mar 2020 14:22:33 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=643; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=30975_1420_31125_21120_30904_31103_30823_31085_26350; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Traceid: 1584714153020437044214556743707837618731
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
响应体
状态码
输入url到数据呈现的过程
原文:https://www.cnblogs.com/hjnzs/p/12548788.html