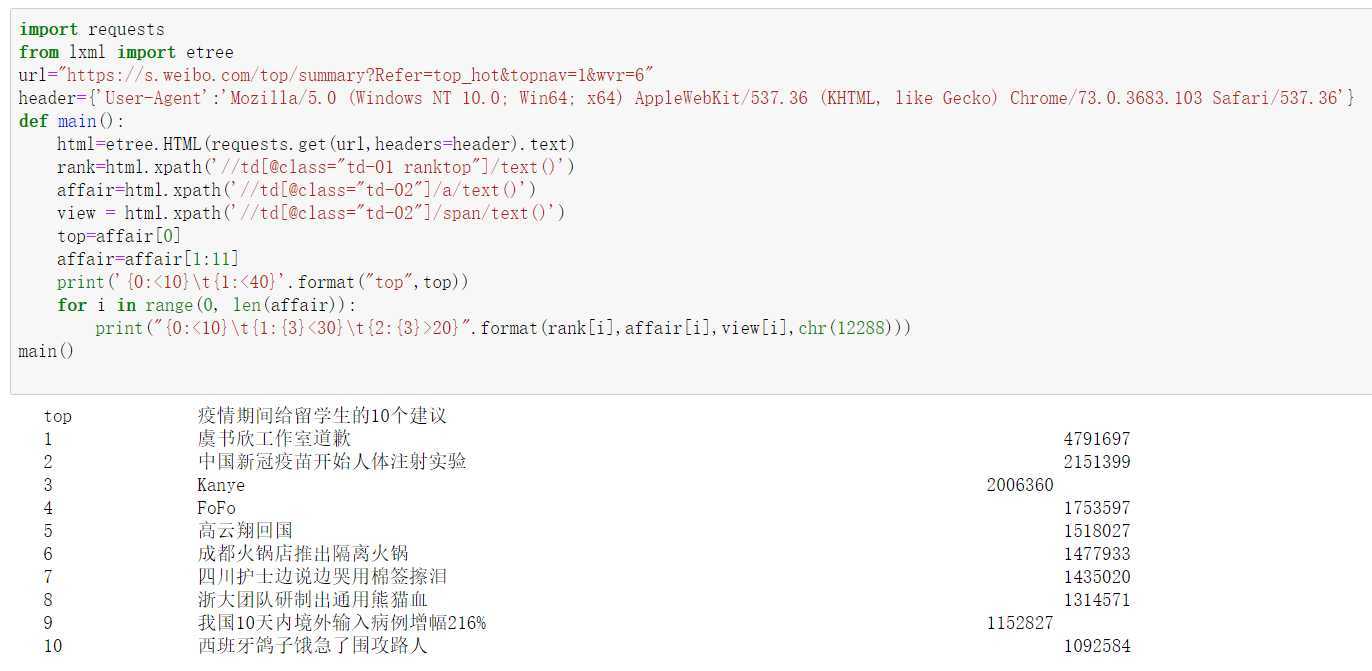
import requests
from lxml import etree
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
header={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36‘}
def main():
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath(‘//td[@class="td-01 ranktop"]/text()‘)
affair=html.xpath(‘//td[@class="td-02"]/a/text()‘)
view = html.xpath(‘//td[@class="td-02"]/span/text()‘)
top=affair[0]
affair=affair[1:11]
print(‘{0:<10}\t{1:<40}‘.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
原文:https://www.cnblogs.com/linbei1/p/12540313.html