注意: 本篇博客不是爬虫教学,主要是技术要点梳理
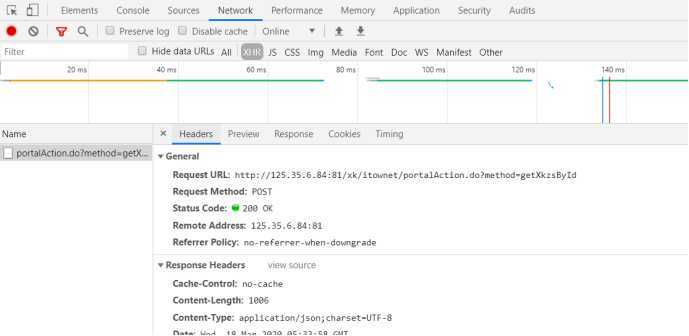
当前url即ajax接口地址,id变量寻找
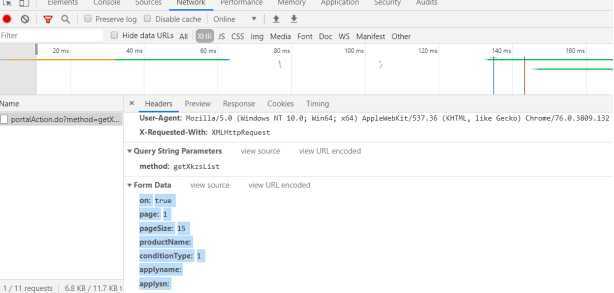
发送数据请求,返回得到数据字典
import requests
if __name__==‘__main__‘:
# 获取企业id
url = ‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘
}
# 参数封装
data={
‘on‘: ‘true‘,
‘page‘: ‘1‘,
‘pageSize‘: ‘15‘,
‘productName‘:‘‘,
‘conditionType‘: ‘1‘,
‘applyname‘:‘‘,
‘applysn‘:‘‘,
}
json_ids = requests.post(url=url,headers=headers,data=data).json()
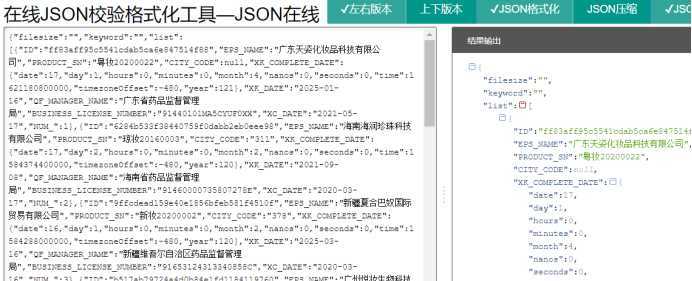
对该json串进行数据解析
id_list=[]
json_ids = requests.post(url=url,headers=headers,data=data).json()
for dic in json_ids[‘list‘]:
id_list.append(dic[‘ID‘])
验证数据,打印一下 print(len(id_list)), 得到字典长度15,与我们上方设置的pageSize相符,所以得到的数据是正确的。
获取企业id号,进行下一个ajax处理
# 企业详细数据
post_url=‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById‘
for id in id_list:
data={
‘id‘:id
}
detail_json = requests.post(url=post_url, headers=headers, data=data).json()
all_data_list.append(detail_json)

打印一下获取的信息,确认无误,进行下一步存储操作即可大功告成
简单的数据持久化存储
#持久化存储all_data_list
fp = open(‘./medData.json‘,‘w‘,encoding=‘utf-8‘)
json.dump(all_data_list,fp=fp,ensure_ascii=False)
print(‘爬取完成!‘)
看到文件里出现了一个新的json格式文件,表示存储完成
检查一下,数据完整,爬取成功!

分页信息爬取优化
# 参数封装
data={
‘on‘: ‘true‘,
‘page‘: ‘1‘,
‘pageSize‘: ‘15‘,
‘productName‘:‘‘,
‘conditionType‘: ‘1‘,
‘applyname‘:‘‘,
‘applysn‘:‘‘,
}
由于从主页复制过来的信息代码进行过分页处理,所以我们要爬取更多数据时要对其进行修改,
for page in range(1,6):
page=str(page)
# 参数封装
data={
‘on‘: ‘true‘,
‘page‘: page,
‘pageSize‘: ‘15‘,
‘productName‘:‘‘,
‘conditionType‘: ‘1‘,
‘applyname‘:‘‘,
‘applysn‘:‘‘,
}
json_ids = requests.post(url=url,headers=headers,data=data).json()
for dic in json_ids[‘list‘]:
id_list.append(dic[‘ID‘])
其中的range内部表示页码,根据不同需求进行更改,不同之处仅在数据数量。
以下全部源码展示
# coding:utf-8
# author:Joseph
import requests
import json
if __name__==‘__main__‘:
# 获取企业id
url = ‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘
}
id_list = [] # 存储企业的id
all_data_list = [] # 存储所有的企业详情数据
for page in range(1,6):
page=str(page)
# 参数封装
data={
‘on‘: ‘true‘,
‘page‘: page,
‘pageSize‘: ‘15‘,
‘productName‘:‘‘,
‘conditionType‘: ‘1‘,
‘applyname‘:‘‘,
‘applysn‘:‘‘,
}
json_ids = requests.post(url=url,headers=headers,data=data).json()
for dic in json_ids[‘list‘]:
id_list.append(dic[‘ID‘])
# print(id_list)
# 企业详细数据
post_url=‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById‘
for id in id_list:
data={
‘id‘:id
}
detail_json = requests.post(url=post_url, headers=headers, data=data).json()
all_data_list.append(detail_json)
#持久化存储all_data_list
fp = open(‘./medData.json‘,‘w‘,encoding=‘utf-8‘)
json.dump(all_data_list,fp=fp,ensure_ascii=False)
print(‘爬取完成!‘)

原文:https://www.cnblogs.com/91joe/p/12518365.html