随机森林
bagging思想
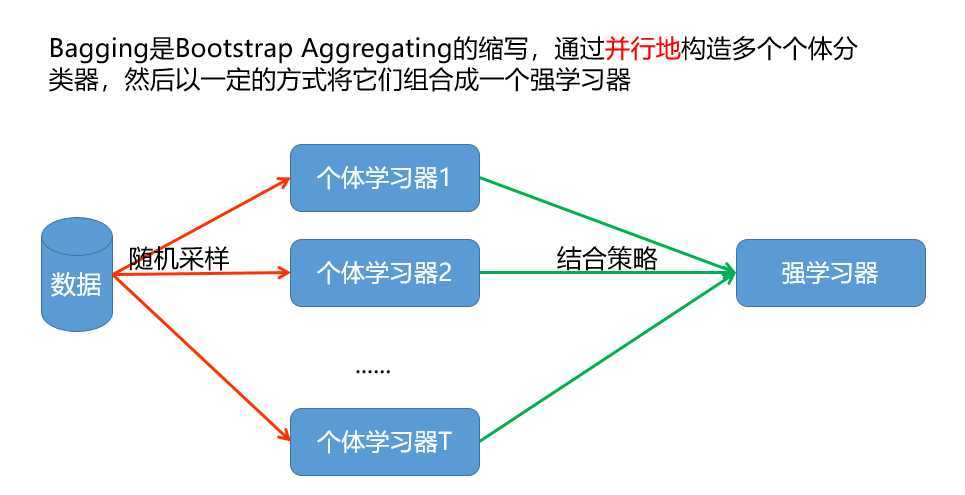
从样本集中用Bootstrap采样选出n个样本;
从所有属性中随机选择K个属性,选择出最佳分割属性作为节点创建决策树;
重复以上两步m次,即建立m棵决策树;
这m个决策树形成随机森林,通过投票表决结果决定数据属于那一类
优点
缺点
Adaboost
Adaptive Boosting是一种迭代算法。
每轮迭代中会在训练集上产生一个新的学 习器,然后使用该学习器对所有样本进行预测,以评估每个样本的重要性 (Informative)。
换句话来讲就是,算法会为每个样本赋予一个权重,每次用训练 好的学习器标注/预测各个样本,如果某个样本点被预测的越正确,则将其权重 降低;
否则提高样本的权重。权重越高的样本在下一个迭代训练中所占的比重就 越大,也就是说越难区分的样本在训练过程中会变得越重要;
整个迭代过程直到错误率足够小或者达到一定的迭代次数为止。
boosting思想,增加被错分样本的权重
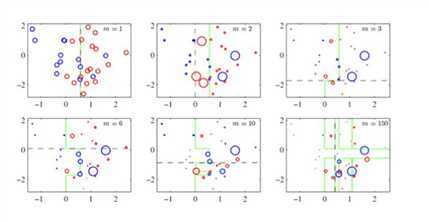
1、很好的利用了弱分类器进行级联。
2、可以将不同的分类算法作为弱分类器。
3、AdaBoost具有很高的精度。
4、相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重。
1、AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定。
2、数据不平衡导致分类精度下降。
3、训练比较耗时,每次重新选择当前分类器最好切分点。
相同点:
原文:https://www.cnblogs.com/zxqqq/p/12501192.html