事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。
简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制。
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
CAP理论说的是:在一个分布式系统中,最多只能满足C、A、P中的两个需求。
CAP的含义:
CAP理论告诉我们,在分布式系统中,C、A、P三个条件中我们最多只能选择两个。那么问题来了,究竟选择哪两个条件较为合适呢?
对于一个业务系统来说,可用性和分区容错性是必须要满足的两个条件,并且这两者是相辅相成的。业务系统之所以使用分布式系统,主要原因有两个:
提升整体性能
当业务量猛增,单个服务器已经无法满足我们的业务需求的时候,就需要使用分布式系统,使用多个节点提供相同的功能,从而整体上提升系统的性能,这就是使用分布式系统的第一个原因。
实现分区容错性
单一节点 或 多个节点处于相同的网络环境下,那么会存在一定的风险,万一该机房断电、该地区发生自然灾害,那么业务系统就全面瘫痪了。为了防止这一问题,采用分布式系统,将多个子系统分布在不同的地域、不同的机房中,从而保证系统高可用性。
在分布式系统中,网络无法100%可靠,分区其实是一个必然现象,如果我们选择了CA而放弃了P,那么当发生分区现象时,为了保证一致性,这个时候必须拒绝请求,但是A又不允许,所以分布式系统理论上不可能选择CA架构,只能选择CP或者AP架构。
CAP理论告诉我们一个悲惨但不得不接受的事实——我们只能在C、A、P中选择两个条件。而对于业务系统而言,我们往往选择牺牲一致性来换取系统的可用性和分区容错性。不过这里要指出的是,所谓的“牺牲一致性”并不是完全放弃数据一致性,而是牺牲强一致性换取弱一致性。下面来介绍下BASE理论。
ACID能够保证事务的强一致性,即数据是实时一致的。这在本地事务中是没有问题的,在分布式事务中,强一致性会极大影响分布式系统的性能,因此分布式系统中遵循BASE理论即可。但分布式系统的不同业务场景对一致性的要求也不同。如交易场景下,就要求强一致性,此时就需要遵循ACID理论,而在注册成功后发送短信验证码等场景下,并不需要实时一致,因此遵循BASE理论即可。因此要根据具体业务场景,在ACID和BASE之间寻求平衡。
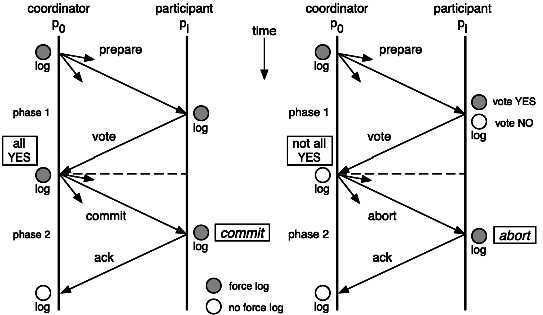
分布式系统的一个难点是如何保证架构下多个节点在进行事务性操作的时候保持一致性。为实现这个目的,二阶段提交算法的成立基于以下假设:
该分布式系统中,存在一个节点作为协调者(Coordinator),其他节点作为参与者(Cohorts)。且节点之间可以进行网络通信。所有节点都采用预写式日志,且日志被写入后即被保持在可靠的存储设备上,即使节点损坏不会导致日志数据的消失。所有节点不会永久性损坏,即使损坏后仍然可以恢复。
尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)
实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景。
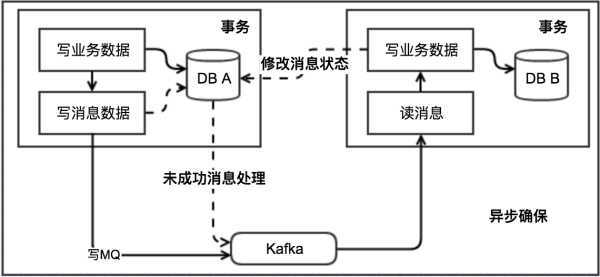
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay。
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
一种非常经典的实现,避免了分布式事务,实现了最终一致性。
消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
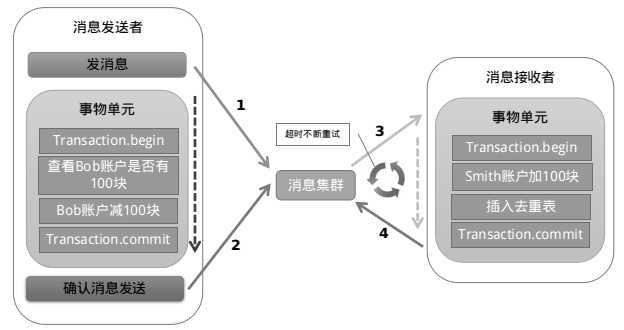
以阿里的 RocketMQ 中间件为例,其思路大致为:
实现了最终一致性,不需要依赖本地数据库事务
实现难度大
原文:https://www.cnblogs.com/weiweng/p/12497329.html