import requests from bs4 import BeautifulSoup import pandas as pd from pandas import DataFrame url="http://top.sogou.com/hot/shishi_1.html?fr=tph_righ"#搜狗今日热搜 headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘}# r=requests.get(url)#请求网站 r.encoding=r.apparent_encoding#统一编码 data=r.text soup=BeautifulSoup(data,‘html.parser‘)#使用“美味的汤”工具 print(soup.prettify())#显示网页结构 title=[] heat=[] ranking=[] for i in soup.find_all(class_="s2"): title.append(i.get_text().strip())#把热搜标题添加到空list for k in soup.find_all(class_="s3"): heat.append(k.get_text().strip()) data=[title,heat] print(data) s=pd.DataFrame(data,index=["标题","热度"]) print(s.T)
1.先导入相应爬虫工具
2.访问搜狗今日热搜页面 http://top.sogou.com/hot/shishi_1.html
3.查看页面结构
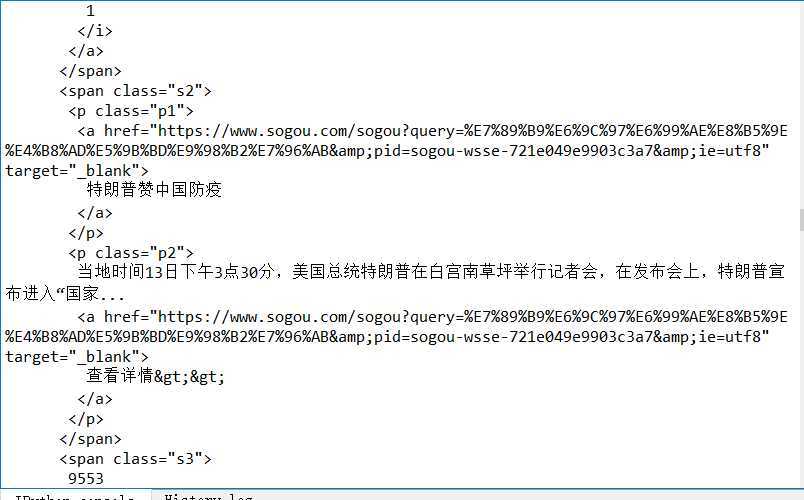
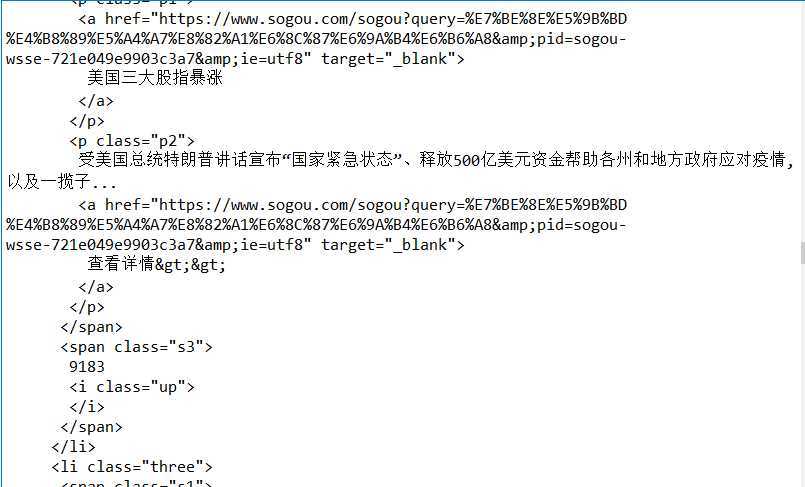
3.找到我们想爬取的内容,发现我们想要获取的热点内容在 class=‘s2’标签里,热点指数在标签 class=‘s3’
4.把所有需要的东西添加到一个空列表中
5.使用DataFrame把数据可视化

原文:https://www.cnblogs.com/yaozhipeng/p/12497240.html