基于百度搜索资料、博客文章的研究、以及疑问的总结。
字体加密在源代码中的乱码的,但在浏览器显示是正常的。
本博文仅供学习研究。
字体加密的大概流程:
1、在后端返回数据到前端时,将一个unicode编码与被加密字符映射并生成字体文件;
2、此时后端返回的数据是与被加密字符映射的unicode,此unicode与加密字符并无关系,根据编码表转换是转换成其他字符;
3、前端接收到数据,根据字体文件的映射解析数据,显示到界面。
此流程为本人猜想,并未实践过。
以 58 为例,
待解密字符:驋驋龤;
解密思路:按照浏览器解析行为
1、找到字体文件
2、根据待解密字符的unicode编码找到此unicode编码的真正映射字符
1、找到待解密字符的字体文件,可以通过css样式找到;
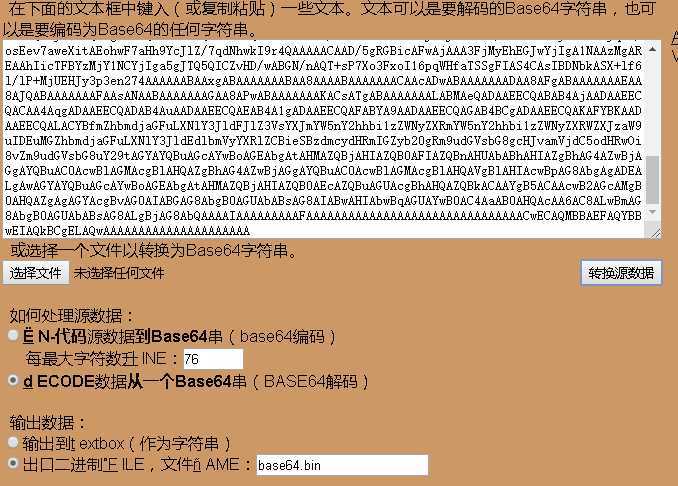
58字体文件为base64:

2、将base64 转码并存储为 .ttf 文件:
在此(https://www.motobit.com/util/base64-decoder-encoder.asp)网站可解码base64并存储为二进制数据的 .bin 文件,将下载的二进制数据的 .bin 文件后缀更改为 .ttf,
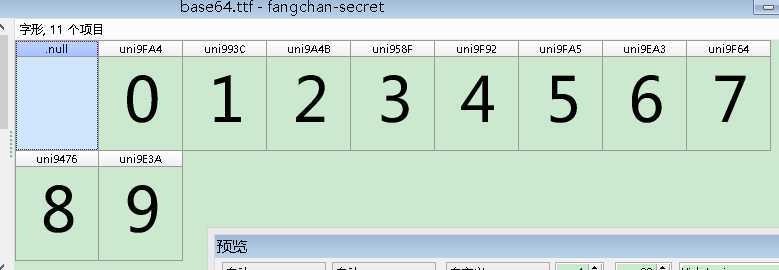
3、通过 FontCreator 软件打开字体文件,可看到字符与unicode的映射关系:
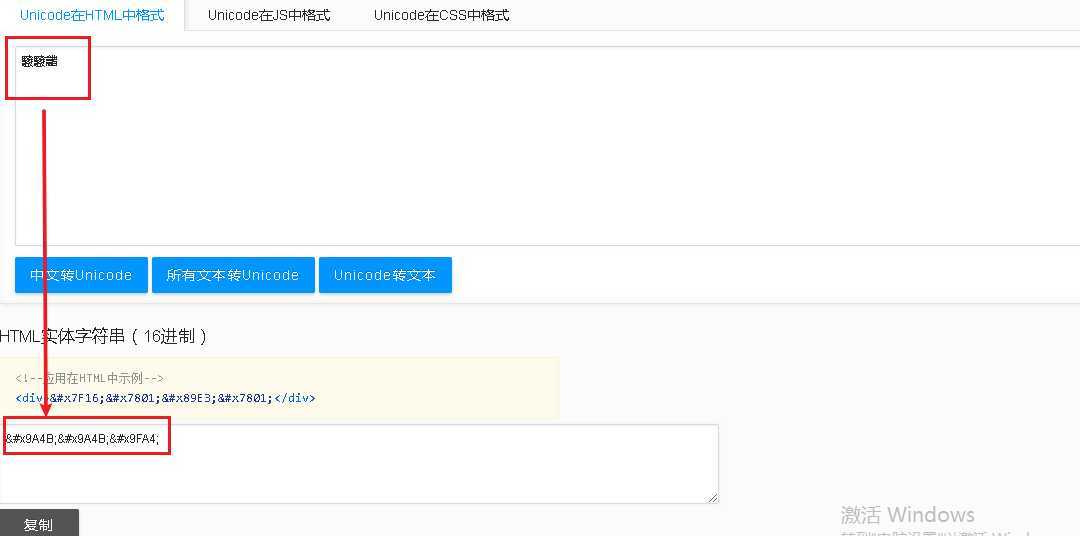
4、将待解密字符转换为unicode编码:驋驋龤:驋驋龤
可通过此网站(https://www.css-js.com/tools/unicode.html)在线转换,得到结果:
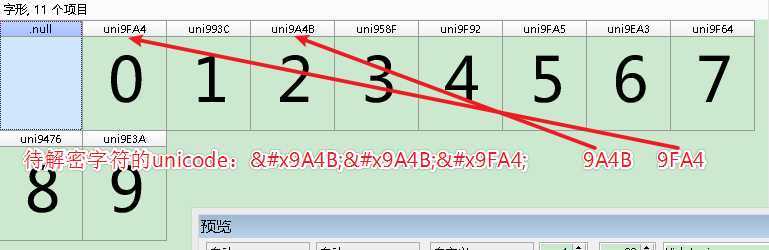
5、根据待解密字符的unicode编码(驋驋龤)在FontCreator 软件中查找对应的字符,得知 驋驋龤 解密后为 220。
原文:https://www.cnblogs.com/blogCblog/p/12497035.html