大数据处理架构如何 |
Hadoop是一个开源的框架,主要处理、存储和分析大量分布式的非结构化数据。他的核心是分布式文件系统HDFS和MapReduce。

图一:hadoop
Hadoop将数据敲碎成多个部分,每个部分都可以同时进行处理和分析。Hadoop内存储的默认文件是Hadoop分布式文件系统。由于类似的文件系统不要求将数据结合进行相关联的行和列,所以他们在存储大量非结构化和半结构化的数据显得得心应手。
数据一旦进入聚类器,MapReduce就可以开始分析了。客户将映射任务提交给聚类器中被称为“任务追踪者”的节点。任务追踪者请示名称节点,决定未来完成任务,他需要获取什么数据,以及该数据在聚类器的位置。接下来的处理并行执行。
完成指定任务后,每个结点都将结果存储起来。客户紧接着通过“任务追踪者”开始运行还原程序。映射阶段储存你在本地每个结点上的结果这是都将被整合起来确定初始查询的答案,并放入下一个聚类器的节点。
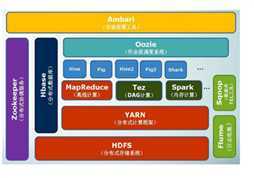
图二:Hadoop生态系统
Hadoop的主要优点在于企业可以由此处理分析大量的非结构化和半结构化数据,并且成本低廉、快速有效。
Hadoop及其无数组件的缺点就是不成熟,仍处于研发阶段。运行、管理Hadoop聚类器,完成对非结构化数据的高级分析需要的操作人员专业知识、技巧和大量培训。随着各个社区不断改善Hadoop组件,并且越来越多的新组件开发,Hadoop将面临分裂问题。
参考文献:
[1]:周忠良. 金融大数据与案例分析。
https://account.cnblogs.com/resetpassword/link?id=55defe9b-f8fd-4540-f305-08d7c32fed65&code=601911
原文:https://www.cnblogs.com/ambdyx/p/12488819.html