目录
1.大而全的一个web框架 采用的是MVT模式 入手简单
2.Django的卖点是超高的开发效率,其性能扩展有限;采用Django的项目,在流量达到一定规模后,都需要对其进行重构,才能满足性能的要求。
3.Django中的ORM非常方便,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。
4.Django内置的ORM跟框架内的其他模块耦合程度高。应用程序必须使用Django内置的ORM,
5.Django适用的是中小型的网站,或者是作为大型网站快速实现产品雏形的工具。
Django模板的设计哲学是彻底的将代码、样式分离; Django从根本上杜绝在模板中进行编码、处理数据的可能用户请求进来先走到 wsgi 然后将请求交给 jango的中间件 穿过django中间件(方法是process_request)
接着就是 路由匹配 路由匹配成功之后就执行相应的 视图函数
在视图函数中可以调用orm做数据库操作 再从模板路径 将模板拿到 然后在后台进行模板渲染
模板渲染完成之后就变成一个字符串 再把这个字符串经过所有中间件(方法:process_response) 和wsgi 返回给用户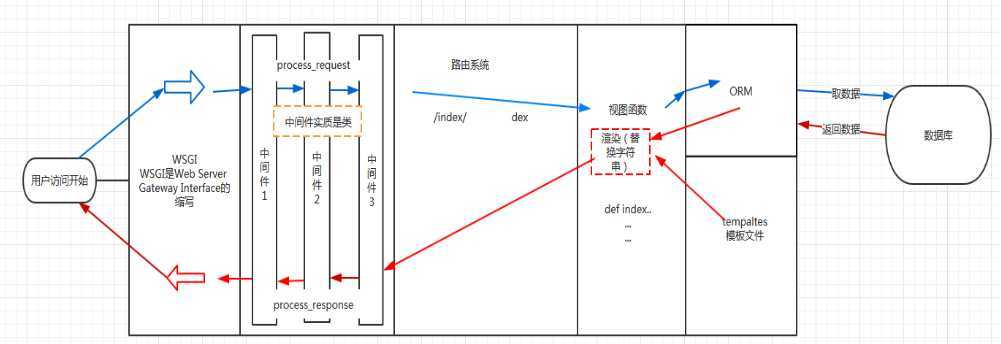
MVC:model 模型、view(视图)、controller(控制器)
MTV:model、tempalte、view .Admin是对model中对应的数据表进行增删改查提供的组件
.model组件:负责操作数据库
.form组件:1.生成HTML代码2.数据有效性校验3校验信息返回并展示
.ModelForm组件即用于数据库操作,也可用于用户请求的验证当请求一个页面时, Django会建立一个包含请求元数据的 HttpRequest 对象.
当Django 加载对应的视图时, HttpRequest对象将作为视图函数的第一个参数.
每个视图会返回一个HttpResponse对象.websocket是给浏览器新建的一套(类似与http)协议,协议规定:(\r\n分割)浏览器和服务器连接之后不断开,
以此完成:服务端向客户端主动推送消息。
websocket协议额外做的一些操作
握手 ----> 连接钱进行校验
加密 ----> payload_len=127/126/<=125 --> mask key
本质
创建一个连接后不断开的socket
当连接成功之后:
客户端(浏览器)会自动向服务端发送消息,包含: Sec-WebSocket-Key: iyRe1KMHi4S4QXzcoboMmw==
服务端接收之后,会对于该数据进行加密:base64(sha1(swk + magic_string))
构造响应头:
HTTP/1.1 101 Switching Protocols\r\n
Upgrade:websocket\r\n
Connection: Upgrade\r\n
Sec-WebSocket-Accept: 加密后的值\r\n
WebSocket-Location: ws://127.0.0.1:8002\r\n\r\n
发给客户端(浏览器)
建立:双工通道,接下来就可以进行收发数据
发送数据是加密,解密,根据payload_len的值进行处理
payload_len <= 125
payload_len == 126
payload_len == 127
获取内容:
mask_key
数据
根据mask_key和数据进行位运算,就可以把值解析出来。
客户端向服务端发送消息时,会有一个'sec-websocket-key'和'magic string'的随机字符串(魔法字符串)
# 服务端接收到消息后会把他们连接成一个新的key串,进行编码、加密,确保信息的安全性django
大而全的框架它的内部组件比较多,内部提供:ORM、Admin、中间件、Form、ModelForm、Session、
缓存、信号、CSRF;功能也都挺完善的
flask
,微型框架,内部组件就比较少了,但是有很多第三方组件来扩展它,
比如说有那个wtform(与django的modelform类似,表单验证)、flask-sqlalchemy(操作数据库的)、
flask-session、flask-migrate、flask-script、blinker可扩展强,第三方组件丰富。所以对他本身来说有那种短小精悍的感觉
- tornado,异步非阻塞。
django和flask的共同点就是,他们2个框架都没有写socket,所以他们都是利用第三方模块wsgi。
但是内部使用的wsgi也是有些不同的:django本身运行起来使用wsgiref,而flask使用werkzeug wsgi
还有一个区别就是他们的请求管理不太一样:django是通过将请求封装成request对象,再通过参数传递,而flask是通过上下文管理机制
Tornado
是一个轻量级的Web框架,异步非阻塞+内置WebSocket功能。
'目标':通过一个线程处理N个并发请求(处理IO)。
内部组件
#内部自己实现socket
#路由系统
#视图
#模板
#cookie
#csrf
django中可以通过channel实现websocketjango中提供了6种缓存方式:
开发调试(不加缓存)
内存
文件
数据库
Memcache缓存(python-memcached模块)
Memcache缓存(pylibmc模块)
安装第三方组件支持redis:
django-redis组件
设置缓存
# 全站缓存(中间件)
MIDDLEWARE_CLASSES = (
‘django.middleware.cache.UpdateCacheMiddleware’, #第一
'django.middleware.common.CommonMiddleware',
‘django.middleware.cache.FetchFromCacheMiddleware’, #最后
)
# 视图缓存
from django.views.decorators.cache import cache_page
import time
@cache_page(15) #超时时间为15秒
def index(request):
t=time.time() #获取当前时间
return render(request,"index.html",locals())
# 模板缓存
{% load cache %}
<h3 style="color: green">不缓存:-----{{ t }}</h3>
{% cache 2 'name' %} # 存的key
<h3>缓存:-----:{{ t }}</h3>
{% endcache %} pip install django-redis
apt-get install redis-serv
在setting添加配置文件
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache", # 缓存类型
"LOCATION": "127.0.0.1:6379", # ip端口
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient", #
"CONNECTION_POOL_KWARGS": {"max_connections": 100} # 连接池最大连接数
# "PASSWORD": "密码",
}
}
}
使用
from django.shortcuts import render,HttpResponse
from django_redis import get_redis_connection
def index(request):
# 根据名字去连接池中获取连接
conn = get_redis_connection("default")
conn.hset('n1','k1','v1') # 存数据
return HttpResponse('...')同源:域名、协议、端口完全相同。
跨域:域名、协议、端口有其中的一样不同。
什么是同源策略
同协议、同domain(或ip)、同端口,视为同一个域,一个域内的脚本仅仅具有本域内的权限。
理解:本域脚本只能读写本域内的资源,而无法访问其它域的资源。这种安全限制称为同源策略。
前端解决跨域访问的常用方式
1.jsonp
2.iframe 元素会创建包含另外一个文档的内联框架(即行内框架)
3.代理:如vue-cli项目中的config/index.js文件中的proxyTable设置所要跨域访问的地址
ors跨域(场景:前后端分离时,本地测试开发时使用)
如果网站之间存在跨域,域名不同,端口不同会导致出现跨域,但凡出现跨域,浏览器就会出现同源策略的限制
解决:在我们的服务端给我们响应数据,加上响应头---> 在中间件加的
设想这样一种情况:A网站是一家银行,用户登录以后,又去浏览其他网站。如果其他网站可以读取A网站的 Cookie,会发生什么?
很显然,如果 Cookie 包含隐私(比如存款总额),这些信息就会泄漏。更可怕的是,Cookie 往往用来保存用户的登录状态,如果用户没有退出登录,其他网站就可以冒充用户,为所欲为。因为浏览器同时还规定,提交表单不受同源政策的限制。
由此可见,"同源政策"是必需的,否则 Cookie 可以共享,互联网就毫无安全可言了。
https://www.cnblogs.com/kiscon/p/8633076.html分类:
1** 信息,服务器收到请求,需要请求者继续执行操作
2** 成功,操作被成功接收并处理
3** 重定向,需要进一步的操作以完成请求
4** 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在处理请求的过程中发生了错误
常见的状态码
200 -请求成功
202 -已接受请求,尚未处理
204 -请求成功,且不需返回内容
301 - 资源(网页等)被永久转移到其他url
400 - 请求的语义或是参数有错
403 - 服务器拒绝请求
404 - 请求资源(网页)不存在
500 - 内部服务器错误
502 - 网关错误,一般是服务器压力过大导致连接超时
503 - 由于超载或系统维护,服务器暂时的无法处理客户端的请求。- user-agent这个头信息识别发出请求的浏览器或其他客户端,并可以向不同类型的浏览器返回不同的内容。
- host这个头信息指定原始的 URL 中的主机和端口。
- referer
这个头信息指示所指向的 Web 页的 URL。例如,如果您在网页 1,点击一个链接到网页 2,当浏览器请求网页 2 时,网页 1 的 URL 就会包含在 Referer 头信息中。
- cookie 这个头信息把之前发送到浏览器的 cookies 返回到服务器。
- content-type #Http: 80端口
#https: 443端口
# http信息是明文传输,https则是具有安全性的ssl加密传输协议。
#- 自定义证书
- 服务端:创建一对证书
- 客户端:必须携带证书
#- 购买证书
- 服务端: 创建一对证书,。。。。
- 客户端: 去机构获取证书,数据加密后发给咱们的服务单
- 证书机构:公钥给改机构WSGI:
web服务器网关接口,是一套协议。用于接收用户请求并将请求进行初次封装,然后将请求交给web框架
实现wsgi协议的模块:
1. wsgiref,本质上就是编写一个socket服务端,用于接收用户请求(django)
2.werkzeug,本质上就是编写一个socket服务端,用于接收用户请求(flask)
uwsgi:
与WSGI一样是一种通信协议,它是uWSGI服务器的独占协议,用于定义传输信息的类型
uWSGI:
是一个web服务器,实现了WSGI协议,uWSGI协议,http协议,process_request : 请求进来时,权限认证
process_view : 路由匹配之后,能够得到视图函数
process_exception : 异常时执行
process_template_responseprocess : 模板渲染时执行
process_response : 请求有响应时执行
反向解析路由字符串
路由系统中name的作用:反向解析
url(r'^home', views.home, name='home')
在模板中使用:{ % url 'home' %}
在视图中使用:reverse(“home”)
当后期要修改url设置规则时,在不使用name字段的时候,不但要修改urls.py文件中的url路由,还要讲html文件中所有的相同路径进行修改,在实际应用中将会有大量的url路由,这样修改下来将会十分的麻烦。
但是,如果使用name字段只需要在urls.py 文件中将path()中的url路由修改了就行了,html文件中的则不需要修改,因为这种方式下是通过name字段来映射url的,故不用再去修改html文件了。而一般情况下name的值又是不会变化的,故后期修改起来将会十分的方便。
即使不同的APP使用相同的URL名称,URL的命名空间模式也可以让你唯一反转命名的URL。
FBV和CBV本质是一样的
基于函数的视图叫做FBV,基于类的视图叫做CBV
在python中使用CBV的优点:
cbv的好处
提高了代码的复用性,可以使用面向对象的技术,比如Mixin(多继承)
可以用不同的函数针对不同的HTTP方法处理,而不是通过很多 if 判断,提高代码可读性
第一步先引入模块from django.utils.decorators import method_decorator`
第2步 加语法糖@method_decorator(wrapper)`
from django.shortcuts import render,HttpResponse
from django.views import View
from django.utils.decorators import method_decorator
def wrapper(func):
def inner(*args, **kwargs):
print(11111)
ret = func(*args, **kwargs)
print(22222)
return ret
return inner
# @method_decorator(wrapper,name='get') # 方式3给get加 用的不多
class LoginView(View):
@method_decorator(wrapper) #方式1
def get(self,request):
print('小小小小')
return HttpResponse('登录成功')
def post(self,request):
print(request.POST)
return HttpResponse('登录成功')
- 没什么区别,因为他们的本质都是函数。CBV的.as_view()返回的view函数,view函数中调用类的dispatch方法,
在dispatch方法中通过反射执行get/post/delete/put等方法。D
非要说区别的话:
- CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
request.method ——》 请求的方式 8种 GET POST PUT DELETE OPTIONS
request.GET ——》 字典 url上携带的参数
request.POST ——》 字典 form表单通过POST请求提交的数据
request.path_info ——》 URL路径 不带参数
request.body ——》 请求体
request.FILES 上传的文件 {}
request.COOKIES cookie
request.session session
request.META 请求头
redirect 重定向
def cs(request):
return redirect('/cs1/') #重定向到url为cs1的地址
def cs1(request):
return HttpResponse('666') #返回字符串666
def cs1(request):
render(request,'xx.html')#返回html页面
返回QuerySet对象的方法有:
all()全部
filter()过滤
exclude() 排除的意思
order_by()
reverse() queryset类型的数据来调用,对查询结果反向排序,
distinct() values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录 去重
特殊的QuerySet:
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元组序列
返回具体对象的:
get()
first()第一个
last()最后一个
返回布尔值的方法有:
exists() queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False
返回数字的方法有:
count()
model对象可以点出来 queryset对象相互转换 只要是返回的queryset类型,就可以继续链式调用queryset类型的其他的查找方法,其他方法也是一样的
<1> all(): 查询所有结果,结果是queryset类型
查询所有的数据 .all方法 返回的是queryset集合
all_objs = models.Student.objects.all() # 类似于列表 -- queryset集合
for i in all_objs:
print(i.name)
print(all_objs)
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象,结果也是queryset类型 Book.objects.filter(title='linux',price=100) #里面的多个条件用逗号分开,并且这几个条件必须都成立,是and的关系,
models.Student.objects.all().filter(id=7) queryset类型可以调用fitler在过滤
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,不是queryset类型,是行记录对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。捕获异常try。 Book.objects.get(id=1)
<4> exclude(**kwargs): 排除的意思,它包含了与所给筛选条件不匹配的对象,没有不等于的操作昂,用这个exclude,返回值是queryset类型 Book.objects.exclude(id=6),返回id不等于6的所有的对象,或者在queryset基础上调用,Book.objects.all().exclude(id=6)
exclude(**kwargs): 排除,objects控制器和queryset集合都可以调用,返回结果是queryset类型
query = models.Student.objects.exclude(id=1)
print(query)
query = models.Student.objects.filter(age=38).exclude(id=6)
print(query)
<5> order_by(*field): 排序 queryset类型的数据来调用,对查询结果排序,默认是按照id来升序排列的,返回值还是queryset类型
models.Book.objects.all().order_by('price','id') #直接写price,默认是按照price升序排列,按照字段降序排列,就写个负号就行了order_by('-cs'),order_by('price','id')是多条件排序,按照price进行升序,price相同的数据,按照id进行升序
<6> reverse(): queryset类型的数据来调用,对查询结果反向排序,返回值还是queryset类型
# 只可以排序之后反转
# query = models.Student.objects.all().order_by('id').reverse()
# print(query)
<7> count(): queryset类型的数据来调用,返回数据库中匹配查询(QuerySet)的对象数量。
<8> first(): queryset类型的数据来调用 ,返回第一条记录结果为model对象类型 Book值
<9> last(): queryset类型的数据来调用,返回最后一条记录,结果为model对象类型
<10> exists(): queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False
空的queryset类型数据也有布尔值True和False,但是一般不用它来判断数据库里面是不是有数据,如果有大量的数据,你用它来判断,那么就需要查询出所有的数据,效率太差了,用count或者exits
例:all_books = models.Book.objects.all().exists() #翻译成的sql是SELECT (1) AS `a` FROM `app01_book` LIMIT 1,就是通过limit 1,取一条来看看是不是有数据
<11> values(*field): 用的比较多,queryset类型的数据来调用,返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列,只要是返回的queryset类型,就可以继续链式调用queryset类型的其他的查找方法,其他方法也是一样的。 里面可以加子段显示
<12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 里面可以加子段显示
<13> distinct(): values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录 去重,结果还是queryset 里面不可以传参 显示nanme等等可以用来去重
query = models.Student.objects.all().values('age').distinct()
print(query)
def filter(self, *args, **kwargs)
# 条件查询(符合条件)
# 查出符合条件
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询(排除条件)
# 排除不想要的
# 条件可以是:参数,字典,Q
1.使用execute执行自定义的SQL
直接执行SQL语句(类似于pymysql的用法)
# 更高灵活度的方式执行原生SQL语句
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT DATE_FORMAT(create_time, '%Y-%m') FROM blog_article;")
ret = cursor.fetchall()
print(ret)
2.使用extra方法 :queryset.extra(select={"key": "原生的SQL语句"})
3.使用raw()方法
1.执行原始sql并返回模型
2.依赖model多用于查询
F:主要用来获取原数据进行计算。 同表 字段比较 更新)
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
修改操作也可以使用F函数,比如将每件商品的价格都在原价格的基础上增加10
from django.db.models import F
from app01.models import Goods
Goods.objects.update(price=F("price")+10) # 对于goods表中每件商品的价格都在原价格的基础上增加10元
F查询专门对对象中某列值的操作,不可使用__双下划线!
Q:用来进行复杂查询 Q查询(与或非)
Q查询可以组合使用 “&”, “|” 操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象,
Q对象可以用 “~” 操作符放在前面表示否定,也可允许否定与不否定形式的组合。
Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
Q(条件1) | Q(条件2) 或
Q(条件1) & Q(条件2) 且
Q(条件1) & ~Q(条件2) 非
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def filter(self, *args, **kwargs)
# 条件查询(符合条件)
# 查出符合条件
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询(排除条件)
# 排除不想要的
# 条件可以是:参数,字典,Q
方式一:手动使用queryset的using方法
from django.shortcuts import render,HttpResponse
from app01 import models
def index(request):
models.UserType.objects.using('db1').create(title='普通用户')
# 手动指定去某个数据库取数据
result = models.UserType.objects.all().using('db1')
print(result)
return HttpResponse('...')
方式二:写配置文件
class Router1:
# 指定到某个数据库取数据
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.model_name == 'usertype':
return 'db1'
else:
return 'default'
# 指定到某个数据库存数据
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
再写到配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
DATABASE_ROUTERS = ['db_router.Router1',]
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
obj_list里面是列表 列表里有对象
models.Book.objects.bulk_create(obj_list) #批量创建
使用django的信号机制,可以在添加、删除数据前后设置日志记录
pre_init # Django中的model对象执行其构造方法前,自动触发
post_init # Django中的model对象执行其构造方法后,自动触发
pre_save # Django中的model对象保存前,自动触发
post_save # Django中的model对象保存后,自动触发
pre_delete # Django中的model对象删除前,自动触发
post_delete # Django中的model对象删除后,自动触发
db first: 先创建数据库,再更新表模型
code first:先写表模型,再更新数据库
https://www.cnblogs.com/jassin-du/p/8988897.html
1、修改seting文件,在setting里面设置要连接的数据库类型和名称、地址
2、运行下面代码可以自动生成models模型文件
- python manage.py inspectdb
3、创建一个app执行下下面代码:
- python manage.py inspectdb > app/models.py
SQL:
# 优点:
执行速度快
# 缺点:
编写复杂,开发效率不高
---------------------------------------------------------------------------
ORM:
# 优点:
让用户不再写SQL语句,提高开发效率
可以很方便地引入数据缓存之类的附加功能
# 缺点:
在处理多表联查、where条件复杂查询时,ORM的语法会变得复杂。
没有原生SQL速度快
目的:防止用户直接向服务端发起POST请求
- 用户先发送GET获取csrf token: Form表单中一个隐藏的标签 + token
- 发起POST请求时,需要携带之前发送给用户的csrf token;
- 在中间件的process_view方法中进行校验。
在html中添加{%csrf_token%}标签
filter : 类似管道,只能接受两个参数第一个参数是|前的数据
simple_tag : 类似函数
1、模板继承:{ % extends 'layouts.html' %}
2、自定义方法
'filter':只能传递两个参数,可以在if、for语句中使用
'simple_tag':可以无线传参,不能在if for中使用
'inclusion_tags':可以使用模板和后端数据
3、防xss攻击: '|safe'、'mark_safe'
- 作用:
- 对用户请求数据格式进行校验
- 自动生成HTML标签
- 区别:
- Form,字段需要自己手写。
class Form(Form):
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
- ModelForm,可以通过Meta进行定义
class MForm(ModelForm):
class Meta:
fields = "__all__"
model = UserInfo
- 应用:只要是客户端向服务端发送表单数据时,都可以进行使用,如:用户登录注册
方式一:重写构造方法,在构造方法中重新去数据库获取值
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = fields.ChoiceField(
# choices=[(1,'普通用户'),(2,'IP用户')]
choices=[]
)
def __init__(self,*args,**kwargs):
super(UserForm,self).__init__(*args,**kwargs)
self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id','title')
方式二: ModelChoiceField字段
from django.forms import Form
from django.forms import fields
from django.forms.models import ModelChoiceField
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
依赖:
class UserType(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错:
TypeError: __init__() missing 1 required positional argument: 'on_delete'
举例说明:
user=models.OneToOneField(User)
owner=models.ForeignKey(UserProfile)
需要改成:
user=models.OneToOneField(User,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值
owner=models.ForeignKey(UserProfile,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值
参数说明:
on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值
CASCADE:此值设置,是级联删除。
PROTECT:此值设置,是会报完整性错误。
SET_NULL:此值设置,会把外键设置为null,前提是允许为null。
SET_DEFAULT:此值设置,会把设置为外键的默认值。
SET():此值设置,会调用外面的值,可以是一个函数。
一般情况下使用CASCADE就可以了。
contenttype是django的一个组件(app),它可以将django下所有app下的表记录下来
可以使用他再加上表中的两个字段,实现一张表和N张表动态创建FK关系。
- 字段:表名称
- 字段:数据行ID
应用:路飞表结构优惠券和专题课和学位课关联
//方式一给每个ajax都加上上请求头
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
data:{csrfmiddlewaretoken:'{{ csrf_token }}',name:'alex'}
success:function(data){
console.log(data);
}
});
}
方式二:需要先下载jQuery-cookie,才能去cookie中获取token
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
headers:{
'X-CSRFToken':$.cookie('csrftoken') // 去cookie中获取
},
success:function(data){
console.log(data);
}
});
}
方式三:搞个函数ajaxSetup,当有多的ajax请求,即会执行这个函数
$.ajaxSetup({
beforeSend:function (xhr,settings) {
xhr.setRequestHeader("X-CSRFToken",$.cookie('csrftoken'))
}
});
函数版本
<body>
<input type="button" onclick="Do1();" value="Do it"/>
<input type="button" onclick="Do2();" value="Do it"/>
<input type="button" onclick="Do3();" value="Do it"/>
<script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/jquery.cookie.js"></script>
<script>
$.ajaxSetup({
beforeSend: function(xhr, settings) {
xhr.setRequestHeader("X-CSRFToken", $.cookie('csrftoken'));
}
});
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
function Do2(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
function Do3(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
</script>
</body>
vue-resource的interceptors拦截器的作用正是解决此需求的妙方。
在每次http的请求响应之后,如果设置了拦截器如下,会优先执行拦截器函数,获取响应体,然后才会决定是否把response返回给then进行接收
1、v-if指令:判断指令,根据表达式值得真假来插入或删除相应的值。
2、v-show指令:条件渲染指令,无论返回的布尔值是true还是false,元素都会存在在html中,只是false的元素会隐藏在html中,并不会删除.
3、v-else指令:配合v-if或v-else使用。
4、v-for指令:循环指令,相当于遍历。
5、v-bind:给DOM绑定元素属性。
6、v-on指令:监听DOM事件。
restful其实就是一套编写接口的'协议',规定如何编写以及如何设置返回值、状态码等信息。
# 最显著的特点:
# 用restful:
给用户一个url,根据method不同在后端做不同的处理
比如:post创建数据、get获取数据、put和patch修改数据、delete删除数据。
# 不用restful:
给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/
# 当然,还有协议其他的,比如:
'版本'来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数
'状态码'200/300/400/500
'url中尽量使用名词'restful也可以称为“面向资源编程”
'api标示'
api.luffycity.com
www.luffycity.com/api/
'一个接口通过1次相同的访问,再对该接口进行N次相同的访问时,对资源不造影响就认为接口具有幂等性。'
GET, #第一次获取结果、第二次也是获取结果对资源都不会造成影响,幂等。
POST, #第一次新增数据,第二次也会再次新增,非幂等。
PUT, #第一次更新数据,第二次不会再次更新,幂等。
PATCH,#第一次更新数据,第二次不会再次更新,非幂等。
DELTE,#第一次删除数据,第二次不在再删除,幂等。
'远程过程调用协议'
是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
进化的顺序: 现有的RPC,然后有的RESTful规范
# 在编写接口时可以不使用django rest framework框架,
# 不使用:也可以做,可以用django的CBV来实现,开发者编写的代码会更多一些。
# 使用:内部帮助我们提供了很多方便的组件,我们通过配置就可以完成相应操作,如:
'序列化'可以做用户请求数据校验+queryset对象的序列化称为json
'解析器'获取用户请求数据request.data,会自动根据content-type请求头的不能对数据进行解析
'分页'将从数据库获取到的数据在页面进行分页显示。
# 还有其他组件:
'认证'、'权限'、'访问频率控制
#- 路由,自动帮助开发者快速为一个视图创建4个url
www.oldboyedu.com/api/v1/student/$
www.oldboyedu.com/api/v1/student(?P<format>\w+)$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)/$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)(?P<format>\w+)$
#- 版本处理
- 问题:版本都可以放在那里?
- url
- GET
- 请求头
#- 认证
- 问题:认证流程?
#- 权限
- 权限是否可以放在中间件中?以及为什么?
#- 访问频率的控制
匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。
如果要封IP,使用防火墙来做。
登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,则无法防止。
#- 视图
#- 解析器 ,根据Content-Type请求头对请求体中的数据格式进行处理。request.data
#- 分页
#- 序列化
- 序列化
- source
- 定义方法
- 请求数据格式校验
#- 渲染器
a. 继承APIView(最原始)但定制性比较强
这个类属于rest framework中的顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制,
但凡是数据库、分页等操作都需要手动去完成,比较原始。
class GenericAPIView(APIView)
def post(...):
pass
b.继承GenericViewSet(ViewSetMixin,generics.GenericAPIView)
首先他的路由就发生变化
如果继承它之后,路由中的as_view需要填写对应关系
在内部也帮助我们提供了一些方便的方法:
get_queryset
get_object
get_serializer
get_serializer_class
get_serializer_context
filter_queryset
注意:要设置queryset字段,否则会抛出断言的异常。
代码
只提供增加功能 只继承GenericViewSet
class TestView(GenericViewSet):
serialazer_class = xxx
def creat(self,*args,**kwargs):
pass # 获取数据并对数据
c. 继承 modelviewset --> 快速快发
-ModelViewSet(增删改查全有+数据库操作)
-mixins.CreateModelMixin(只有增),GenericViewSet
-mixins.CreateModelMixin,DestroyModelMixin,GenericViewSet
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。
示例:只提供增加功能
class TestView(mixins.CreateModelMixin,GenericViewSet):
serializer_class = XXXXXXX
***
modelviewset --> 快速开发,复杂点的genericview、apiview
- 如何编写?写类并实现authenticators
请求进来认证需要编写一个类,类里面有一个authenticators方法,我们可以自定义这个方法,可以定制3类返回值。
成功返回元组,返回none为匿名用户,抛出异常为认证失败。
源码流程:请求进来先走dispatch方法,然后封装的request对象会执行user方法,由user触发authenticators认证流程
- 方法中可以定义三种返回值:
- (user,auth),认证成功
- None , 匿名用户
- 异常 ,认证失败
- 流程:
- dispatch
- 再去request中进行认证处理
# 对匿名用户,根据用户IP或代理IP作为标识进行记录,为每个用户在redis中建一个列表
{
throttle_1.1.1.1:[1526868876.497521,152686885.497521...],
throttle_1.1.1.2:[1526868876.497521,152686885.497521...],
throttle_1.1.1.3:[1526868876.497521,152686885.497521...],
}
每个用户再来访问时,需先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
'如何封IP':在防火墙中进行设置
--------------------------------------------------------------------------
# 对注册用户,根据用户名或邮箱进行判断。
{
throttle_xxxx1:[1526868876.497521,152686885.497521...],
throttle_xxxx2:[1526868876.497521,152686885.497521...],
throttle_xxxx3:[1526868876.497521,152686885.497521...],
}
每个用户再来访问时,需先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
\如1分钟:40次,列表长度限制在40,超过40则不可访问
Flask自由、灵活,可扩展性强,透明可控,第三方库的选择面广,
开发时可以结合最流行最强大的Python库,
# 依赖jinja2模板引擎
# 依赖werkzurg协议
# blueprint把实现不同功能的module分开.也就是把一个大的App分割成各自实现不同功能的module.
# 在一个blueprint中可以调用另一个blueprint的视图函数, 但要加相应的blueprint名.
# Flask组件
flask-session session放在redis
flask-SQLAlchemy 如django里的ORM操作
flask-migrate 数据库迁移
flask-script 自定义命令
blinker 信号-触发信号
# 第三方组件
Wtforms 快速创建前端标签、文本校验
dbutile 创建数据库连接池
gevnet-websocket 实现websocket
# 自定义Flask组件
自定义auth认证
参考flask-login组件
# a、简单来说,falsk上下文管理可以分为三个阶段:
1、'请求进来时':将请求相关的数据放入上下问管理中
2、'在视图函数中':要去上下文管理中取值
3、'请求响应':要将上下文管理中的数据清除
# b、详细点来说:
1、'请求刚进来':
将request,session封装在RequestContext类中
app,g封装在AppContext类中
并通过LocalStack将requestcontext和appcontext放入Local类中
2、'视图函数中':
通过localproxy--->偏函数--->localstack--->local取值
3、'请求响应时':
先执行save.session()再各自执行pop(),将local中的数据清除
# g是贯穿于一次请求的全局变量,当请求进来将g和current_app封装为一个APPContext类,
# 再通过LocalStack将Appcontext放入Local中,取值时通过偏函数在LocalStack、local中取值;
# 响应时将local中的g数据删除:
RequestContext #封装进来的请求(赋值给ctx)
AppContext #封装app_ctx
LocalStack #将local对象中的数据维护成一个栈(先进后出)
Local #保存请求上下文对象和app上下文对象
# 因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。
# 还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表
# local是一个字典,字典里key(stack)是唯一标识,value是一个列表
请求进来时,可以根据URL的不同,交给不同的APP处理。蓝图也可以实现。
#app1 = Flask('app01')
#app2 = Flask('app02')
#@app1.route('/index')
#@app2.route('/index2')
源码中在DispatcherMiddleware类里调用app2.__call__,
原理其实就是URL分割,然后将请求分发给指定的app。
之后app也按单app的流程走。就是从app.__call__走。
gevent-websocket
#快速创建前端标签、文本校验;如django的ModelForm
# flask中的信号blinker
信号主要是让开发者可是在flask请求过程中定制一些行为。
或者说flask在列表里面预留了几个空列表,在里面存东西。
简言之,信号允许某个'发送者'通知'接收者'有事情发生了
@ before_request有返回值,blinker没有返回值
# 10个信号
request_started = _signals.signal('request-started') #请求到来前执行
request_finished = _signals.signal('request-finished') #请求结束后执行
before_render_template = _signals.signal('before-render-template')#模板渲染前执行
template_rendered = _signals.signal('template-rendered')#模板渲染后执行
got_request_exception = _signals.signal('got-request-exception') #请求执行出现异常时执行
request_tearing_down = _signals.signal('request-tearing-down')#请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext-tearing-down')# 请求上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal('appcontext-pushed') #请求app上下文push时执行
appcontext_popped = _signals.signal('appcontext-popped') #请求上下文pop时执行
message_flashed = _signals.signal('message-flashed')#调用flask在其中添加数据时,自动触发
原文:https://www.cnblogs.com/saoqiang/p/12453745.html