KMeans(K均值)是典型的基于距离的排他划分方法:给定一个n个对象的数据集,它可以构建数据的k个划分,每个划分就是一个聚类,并且k<=n,同时还满足两个要求:
1.每个组至少包含一个对象
2.每个对象必须属于且仅属于一个组
1.首先创建一个初始化分,随机的选择k个对象,每个对象初始的代表一个聚类中心。对于其他对象,根据其与各个聚类中心的距离,将它们赋给最近的聚类。
递归重定位,尝试通过对象在划分间移动来改进划分。重定位即:当有新的对象加入聚类或者已有对象离开聚类的时候,重新计算聚类的平均值,然后对对象进行重新分配。这个过程不断重复,直到聚类中的数据不再变化为止。
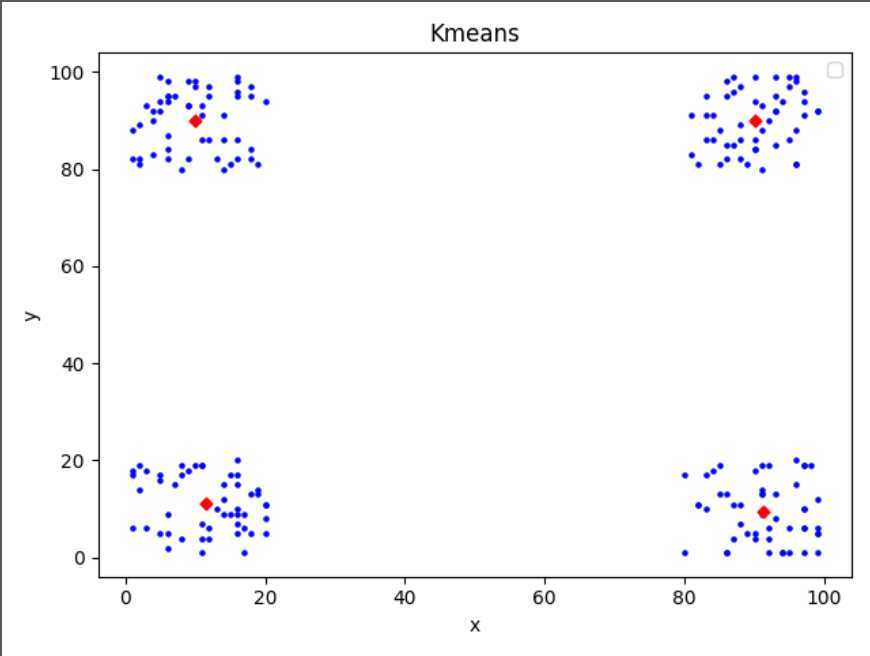
from numpy import * from sklearn.cluster import KMeans import matplotlib.pyplot as plt def file2matrix(filePath, lineSplit): dataSet = [] fr = open(filePath, ‘r‘) content = fr.read() for line in content.splitlines(): dataSet.append([line.split(‘\t‘)[0], line.split(‘\t‘)[1]]) fr.close() return dataSet def drawScatter(plt, dataMat, size, color, mrkr): X = dataMat[:,0] Y = dataMat[:,-1] plt.scatter(X.tolist(), Y.tolist(), c=color, marker=mrkr, s=size) plt.xlabel("x") plt.ylabel("y") plt.title("Kmeans") plt.legend() k = 4 dataSet = file2matrix("/Users/FengZhen/Desktop/accumulate/机器学习/推荐系统/kmeans聚类测试集.txt", "\t") dataMat = mat(dataSet) print(dataMat) # 执行kmeans算法 kmeans = KMeans(init=‘k-means++‘, n_clusters=k) kmeans.fit(dataMat) print(kmeans.cluster_centers_) #绘制计算结果 drawScatter(plt, dataMat, size=20, color=‘b‘, mrkr=‘.‘) drawScatter(plt, kmeans.cluster_centers_, size=20, color=‘red‘, mrkr=‘D‘) plt.show()
原文:https://www.cnblogs.com/EnzoDin/p/12452487.html