通过压缩响应json数据,从而加快响应速度,并且django-compression-middleware支持多种浏览器(除了IE11)。
下载django-compression-middleware
在settings配置:
MIDDLEWARE = [
...
"django.middleware.common.CommonMiddleware",
"django.contrib.auth.middleware.AuthenticationMiddleware",
"compression_middleware.middleware.CompressionMiddleware",
...
]使用django-compression-middleware之前:
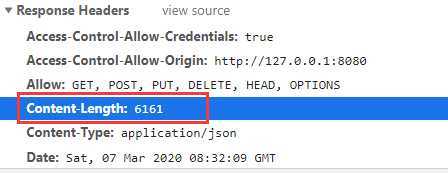
使用django-compression-middleware之后:
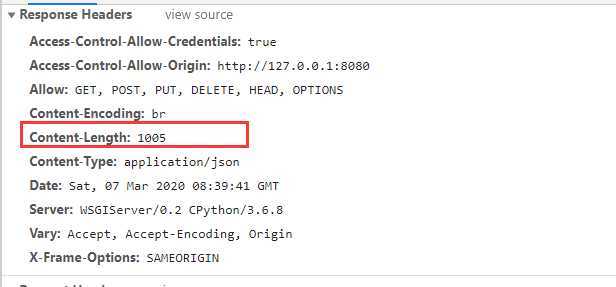
可以看到,压缩后后响应体,Content-length相比原来缩小了六分之一。需要知道的是Django文档GZipMiddleware章节所说,压缩可能会导致网站出现安全漏洞。
PageNumberPagination解决,详见restFramework之------分页。django-debug-toolbar,一个调试的组件,配置详见Django:基于调试组插件go-debug-toolbar。举个简单小例子,比方出版社和书是一对多关系class Bookser(serializers.Serializer):
"""序列化器"""
id = serializers.IntegerField(read_only=True)
pub_name = serializers.CharField(source="publisher.name", read_only=True)
title = serializers.CharField(max_length=32)
put_time = serializers.DateField()
class Book(APIView):
"""视图函数"""
def get(self,request):
books = models.Book.objects.all()
ser_obj = Bookser(instance = books,many=True)
return Response(ser_obj.data)
# 这里做的是查询书信息和出版社。这里看到,做了13次查询获得结果:
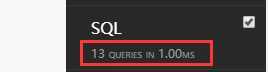
通过select_related查询:
class Book(APIView):
def get(self,request):
books = models.Book.objects.select_related("publisher")
res = []
for book in books:
res.append({"id":book.id,"pub_name":book.publisher.name,"title":book.title,"put_time":book.put_time})
ser_obj = Bookser(instance=res, many=True)
return Response(ser_obj.data)通过select_related查询次数就一次:

class Bookser(serializers.Serializer):
"""序列化多对多"""
id = serializers.IntegerField(read_only=True)
pub_name = serializers.CharField(source="publisher.name", read_only=True)
title = serializers.CharField(max_length=32)
put_time = serializers.DateField()
author = serializers.SerializerMethodField(read_only=True)
# 获取每个书对象对应作者
def get_author(self,obj):
author = obj.authors.all()
auth = AuthorSerializer(author, many=True)
return auth.data
class Book(APIView):
"""视图函数"""
def get(self,request):
books = models.Book.objects.all()
# 序列化 books对象,获得书和作者数据
ser_obj = Bookser(instance = books,many=True)
return Response(ser_obj.data)这里看到,做了25次查询获得结果:
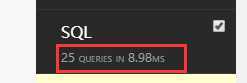
通过prefetch_related查询:
class Book(APIView):
def get(self,request):
res = []
books = models.Book.objects.prefetch_related("authors")
for book in books:
res.append(
{
"id":book.id,
"title": book.title,
"put_time": book.put_time,
"author": [{"author_name":author.author_name,"id":author.id} for author in book.authors.all()]
}
)
return Response(res)通过prefetch_related查询次数就2次:
小结:
通过select_related和prefetch_related需要注意:
如果不建立数据库连接池,效果会更明显,因为减少了数据库往返次数
若果结果集过大,使用prefetch_related反而会使速度变慢
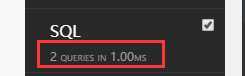
对一个数据库查询不一定比两个或多个快。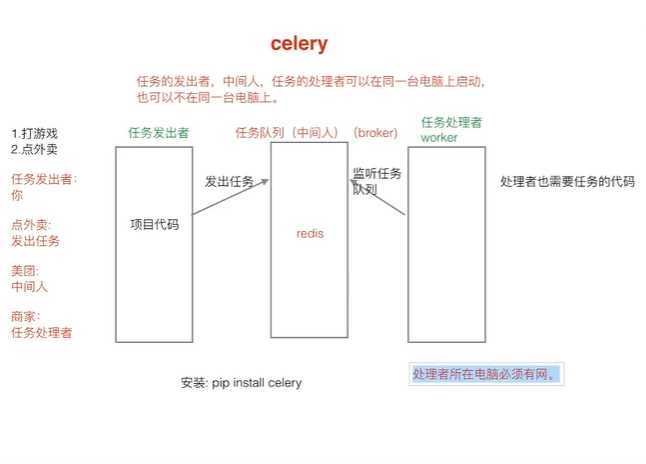
下载:
pip install celery
pip install django-celery
pip install redis文件目录:
djangoSerializers
|__ api
|___ __init__.py
|___ taksk.py
|___ views.py
|___ ...
|__ djangoSerializers
|___ __init__.py
|___ settings.py
|___ urls.py
|___ wsgi.py
|___ celery.py在settings配置:
# 1.建立celery
INSTALLED_APPS = [
'djcelery'
]
# 2. 基本配置
import djcelery
djcelery.setup_loader() # 加载djcelery
# 数据库调度
BROKER_TRANSPORT='redis' #指定redis
CELERYBEAT_SCHEDULER='djcelery.schedulers.DatabaseScheduler' # celey处理器,固定
CELERY_BROKER_URL = 'redis://127.0.0.1:6379/0' # Broker配置,使用Redis作为消息中间件
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/1' # BACKEND配置,这里使用redis
CELERY_IMPORTS = ('api.tasks')
# CELERY_RESULT_SERIALIZER = 'json' # 结果序列化方案
#允许的内容类型,
CELERY_ACCEPT_CONTENT=['pickle','json']
#任务的序列化方式
CELERY_TASK_SERIALIZER = 'json'
#celery时区
CELERY_TIMEZONE = 'Asia/Shanghai'
在同级的__init__.py文件配置
from __future__ import absolute_import
from .celery import app as celery_app
# 这是为了确保在django启动时启动 celerytasks.py定义worker函数。
from __future__ import absolute_import
from djangoSerializers.celery import app
import time
@app.task
def add(x,y):
"""任务处理"""
time.sleep(30)
return x + y视图中使用任务处理函数:
from djangoSerializers.celery import app
from rest_framework.response import Response
class CeleryView(APIView):
def get(self,request):
#执行异步任务
result = add.delay(2,5)
# 获取任务id
task_id = result.id
# 获取任务状态
status = app.AsyncResult(task_id).status
return Response({"code":200,"msg":"OK","status":status,"task_id":task_id})任务状态有:
'PENDING': '等待开始',
'STARTED': '任务开始',
'SUCCESS': '成功',
'FAILURE': '失败',
'RETRY': '重试',
'REVOKED': '任务取消',在终端执行:
python manage.py help
通过执行如下命令,启动worker节点:
python3 manage.py celery worker -l INFO查看执行状态:
class SearchCeleryView(APIView):
def get(self,request):
# 获取任务id
task_id = request.query_params.get('taskid')
# 查看任务状态
status = app.AsyncResult(task_id).status
# 查看任务执行结果,没有执行完是None
result = app.AsyncResult(task_id).result
print(status,result)
return Response({"status":status,"result":result})# 在settings我们之前配置了允许数据类型pickle,否则会报错:kombu.exceptions.ContentDisallowed: Refusing to deserialize untrusted content of type pickle (application/x-python-serialize)定时任务:
# 定义队列名字
CELERY_QUEUES = {
'beat_tasks': {
'exchange': 'beat_tasks',
'exchange_type': 'direct',
'binding_key': 'beat_tasks'
},
'work_queue': {
'exchange': 'work_queue',
'exchange_type': 'direct',
'binding_key': 'work_queue'
}
}
# 默认执行队列
CELERY_DEFAULT_QUEUE = 'work_queue'# 有些情况下可以防止死锁
CELERYD_FORCE_EXECV = True
# 设置并发的worker数量
CELERYD_CONCURRENCY = 4
# 允许重试
CELERY_ACKS_LATE = True
# 每个worker最多执行100个任务被销毁,可以防止内存泄漏
CELERYD_MAX_TASKS_PER_CHILD = 100
# 单个任务的最大运行时间,超过就杀死
CELERYD_TASK_TIME_LEMIT = 12 * 30CELERYBEAT_SCHEDULE = {
'helloworld':{
# 指向处理任务的函数
"task": "api.tasks.hellworld",
# 执行时间 5秒一次
"schedule": timedelta(seconds=5),
# args传参
"args":{},
# 指定任务队列 在beat_tasks队列上的
"options": {
"queue": 'beat_tasks'
}
}
}@app.task
def hellworld():
time.sleep(3)
print("hello world is run...")
return "hello world"# 启动worker来处理任务
python3 manage.py celery worker -l INFO
# 启动定时任务,当到时间时,把任务放入broker中,broker检测到了,让worker去工作。
python manage.py celery beat -l info 原文:https://www.cnblogs.com/xujunkai/p/12441647.html