什么是引用计数?
# 直接引用
x = 10 # 10的引用计数为1
y = x # 10的引用计数为2
z = y # 10的引用计数为3
print(id(x))
print(id(y))
print(id(z))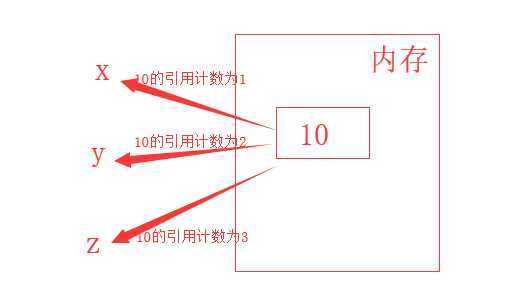
# 间接引用
x = 10 # 10的引用计数为1
# 列表中存的是值的内存地址
l = [x, 'a'] # 10的引用计数为2
print(id(l[0]))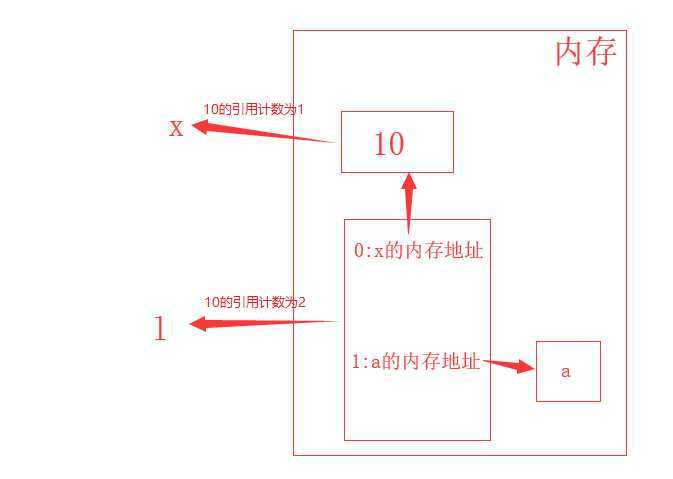
引用计数扩展阅读
标记-清除
# 循环引用
l1 = [111, ]
l2 = [222, ]
l1.append(l2) # l1=[值111的内存地址, l2列表的内存地址]
l2.append(l1) # l1=[值222的内存地址, l1列表的内存地址]
print(id(li[1]))
print(id(l2))
print(id(l2[1]))
print(id(l1))
print(l2)
print(l1[1])
del l1 # 列表1的引用计数减1,列表1的引用计数变为1
del l2 # 列表2的引用计数减1,列表2的引用计数变为1分代回收
降低了引用计数回收内存时的扫描频率,提高了回收效率,分代回收采用的是用“空间换时间”的策略。
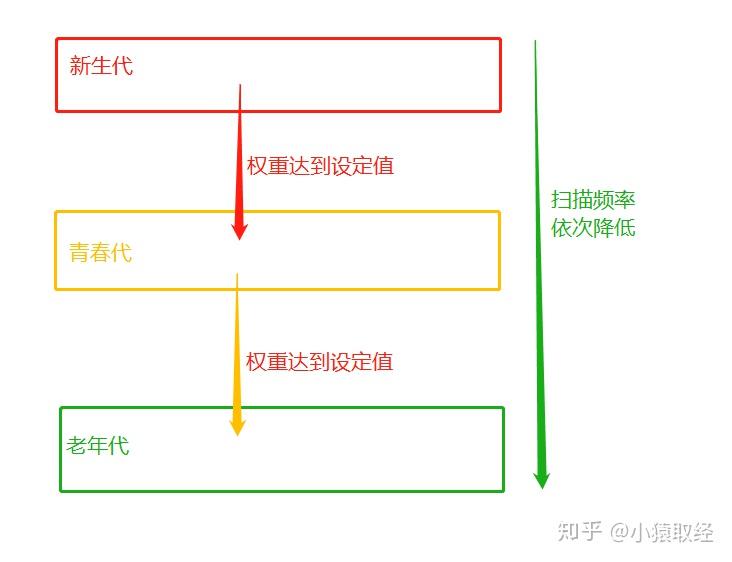
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
'''
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,
该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。
'''原文:https://www.cnblogs.com/guanxiying/p/12419094.html