1、通过http向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
2、如果服务器能正常响应,会得到一个Response,Response的内容就是要获取的页面内容
3、解析内容:正则表达式、页面解析库、json
4、保存数据:文本或者存入数据库2.什么是Request和Response?
本地 向 服务器 发送Request,服务器根据请求返回一个Response,页面就显示出来了
1、浏览器发送消息给该网址所在的服务器,这个过程叫做Http Request
2、服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器,这个过程叫做HTTP Response
3、浏览器收到服务器的Response消息后,会对信息进行相应处理,然后显示3.Request中包含什么呢?
1、请求方式:主要有GET和POST两种方式,POST请求的参数不会包含在url里面
2、请求URLURL:统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一确定
3、请求头信息,包含了User-Agent(浏览器请求头)、Host、Cookies信息
4、请求体,GET请求时,一般不会有,POST请求时,请求体一般包含form-data4.Response中包含什么信息?
1、响应状态:状态码 正常响应200 重定向
2、响应头:如内容类型、内容长度、服务器信息、设置cookie等
3、响应体信息:响应源代码、图片二进制数据等等5.常见的http状态码
200状态码 服务器请求正常
301状态码:被请求的资源已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302状态码:请求的资源临时从不同的URI响应请求,但请求者应继续使用原有位置来进行以后的请求
401状态码:请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403状态码:服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。
404状态码:请求失败,请求所希望得到的资源未被在服务器上发现。
500状态码:服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器的程序码出错时出现。
503状态码:由于临时的服务器维护或者过载,服务器当前无法处理请求。6.HTTP 的请求和响应都包含哪些内容
HTTP请求头:
Accept:浏览器能够处理的内容类型
Accept-Charset:浏览器能够显示的字符集
Accept-Encoding:浏览器能够处理的压缩编码
Accept-Language:浏览器当前设置的语言
Connection:浏览器与服务器之间连接的类型
Cookie:当前页面设置的任何Cookie
Host:发出请求的页面所在的域
Referer:发出请求的页面的URL
User-Agent:浏览器的用户代理字符串
HTTP响应头部信息:
Date:表示消息发送的时间,时间的描述格式由rfc822定义
server:服务器名字。
Connection:浏览器与服务器之间连接的类型
content-type:表示后面的文档属于什么MIME类型
Cache-Control:控制HTTP缓存7. 你遇到的反爬虫策略有哪些?及应对策略有什么?
反爬虫策略
1.通过headers反爬虫
2.基于用户行为的发爬虫:例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
3.动态网页反爬虫,例如:我们需要爬取的数据是通过ajax请求得到,或者通过JavaScript生成的对部分数据进行加密处理的,例如:我们要抓的数据一部分能够抓到,另外的部分加密处理了,是乱码的。
应对策略:
1.对于基本网页的抓取可以自定义headers,添加headers的数据,代理来解决。
2.有些网站的数据抓取必须进行模拟登陆才能抓取到完整的数据,所以要进行模拟登陆。
3.对于限制抓取频率的,可以设置抓取的频率降低一些,
4.对于限制ip抓取的可以使用多个代理ip进行抓取,轮询使用代理
5.针对动态网页的可以使用selenium+phantomjs进行抓取,但是比较慢,所以也可以使用查找接口的方式进行抓取。
6.对部分数据进行加密的,可以使用selenium进行截图,饭后使用python自带的 pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。8. 谈一谈你对 Selenium 和 PhantomJS 了解
Selenium 是一个Web 的自动化测试工具,可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。Selenium库里有个叫 WebDriver 的API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像BeautifulSoup 或者其他Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
PhantomJS是一个基于 Webkit 的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。相比传统的Chrome或 Firefox 浏览器等,资源消耗会更少。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。主程序退出后,selenium 不保证 phantomJS 也成功退出,最好手动关闭 phantomJS 进程。(有可能会导致多个 phantomJS 进程运行,占用内存)。WebDriverWait 虽然可能会减少延时,但是目前存在 bug(各种报错),这种情况可以采用 sleep。phantomJS爬数据比较慢,可以选择多线程。如果运行的时候发现有的可以运行,有的不能,可以尝试将 phantomJS 改成 Chrome。9. 为什么 requests 请求需要带上 header?
原因是:模拟浏览器,欺骗服务器,获取和浏览器一致的内容
header 的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法: requests.get(url,headers=headers)。10.Scrapy优缺点:
优点:
1.scrapy 是异步的
2.采取可读性更强的xpath代替正则
3.强大的统计和log系统
4.同时在不同的url上爬行
5.支持shell方式,方便独立调试
6.写middleware,方便写一些统一的过滤器
6.通过管道的方式存入数据库
缺点:
1.基于python的爬虫框架,扩展性比较差
2.基于twisted框架,运行中的exception是不会干掉reactor,并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉12. 简述 移动端 app 数据的抓取流程
1、例如:爬取手机淘宝, 核心还是一个 WEB页面:https://m.taobao.com/#index
2、有很多资讯类的 APP,核心都是一个 WEB页面。直接用爬虫的方法抓就可以了。
3、非 WEB页面的 APP,用 APP自动化的一些东西试试
4、不然就只有抓包了。13.在 requests 模块中,requests.content 和 requests.text 什么区别?
1.response.content: 这个是直接从网络上面抓取的数据,没有经过任何解码,所以是一个bytes类型,其实在硬盘上和在网络上传输的字符串都是bytes类型
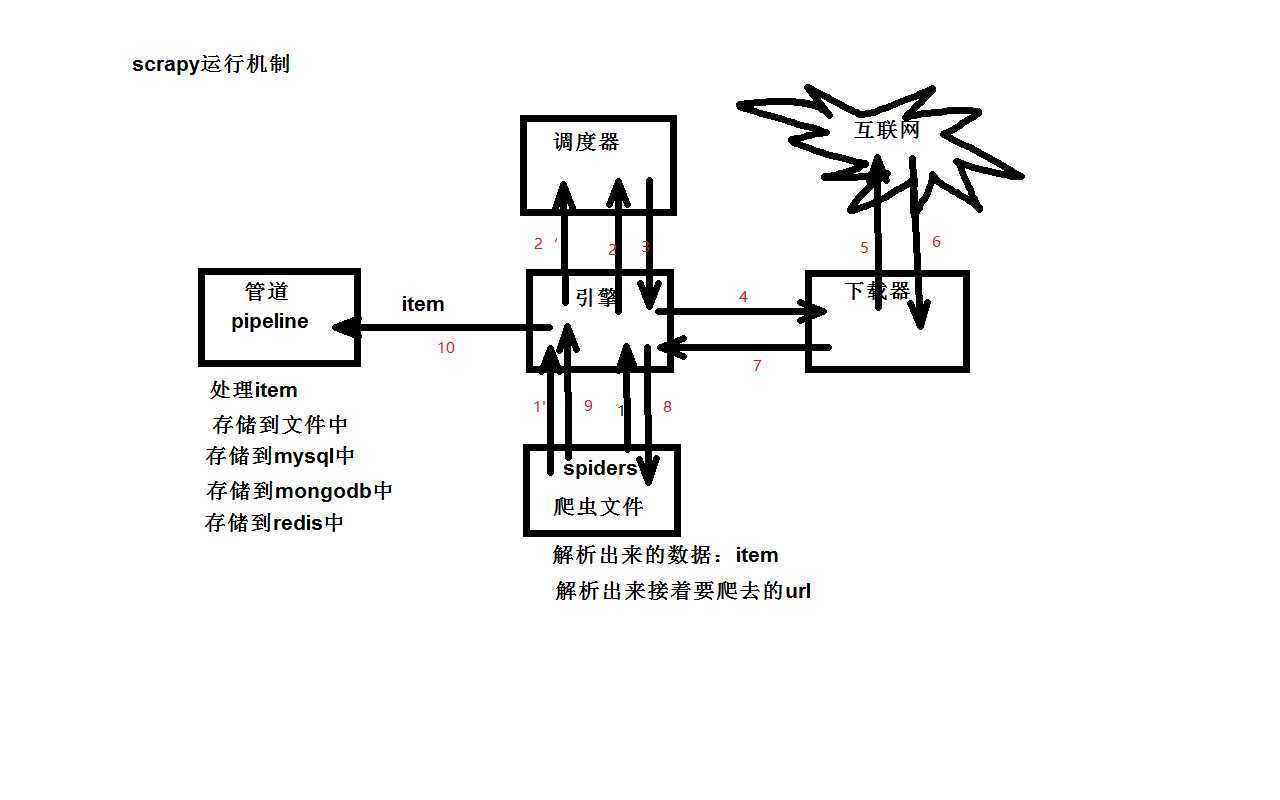
2.response.text: 这个是str的数据类型,是requests库将response.content进行解码的字符串,解码需要指定一个编码方式,requests会根据自己的猜测来判断编码的方式,所以有时候可能会猜测错误,就会导致解码产生乱码,这时候就应该使用‘response.content.decode(‘utf-8‘)‘进行手动解码14.说一说 scrapy 的工作流程
15.scrapy 的去重原理
1.Scrapy本身自带有一个中间件;
2.scrapy源码中可以找到一个dupefilters.py去重器;
3.需要将dont_filter设置为False开启去重,默认是false去重,改为True,就是没有开启去重;
4 .对于每一个url的请求,调度器都会根据请求得相关信息加密得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进 行 比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中;5.如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。15.scrapy 中间件有几种类,你用过哪些中间件
概述:在scrapy运行的整个过程中,对scrapy框架运行的某些步骤做一些适配自己项目的动作.
例如scrapy内置的HttpErrorMiddleware,可以在http请求出错时做一些处理.
中间件的分类:scrapy的中间件理论上有三种(Schduler Middleware,Spider Middleware,Downloader Middleware),在应用上一般有以下两种
? ? ? ?1.爬虫中间件Spider Middleware
? ? ? ?主要功能是在爬虫运行过程中进行一些处理.,downloadtimeout,RobotsTxtMiddleware
,HttpAuthMiddleware,DownloaderStats
2.下载器中间件Downloader Middleware
? ? ? ? ?主要功能在请求到网页后,页面被下载时进行一些处理,如:DownloaderMiddleware,user-agent中间件,代理ip中间件,重试中间件
17.scrapy 和 scrapy-redis 有什么区别?为什么选择 redis 数据库?
1) scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。而scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。
2)?为什么选择redis数据库,因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。18. 分布式爬虫原理?
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为 master,而把用于跑爬虫程序的机器称为 slave。
我们知道,采用 scrapy 框架抓取网页,我们需要首先给定它一些 start_urls,爬虫首先访问 start_urls里面的 url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个 starts_urls 里面做文章就行了。
我们在 master 上搭建一个 redis 数据库(注意这个数据库只用作 url 的存储,不关心爬取的具体数据,不要和后面的 mongodb 或者 mysql 混淆),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置 slave 上 scrapy-redis 获取 url 的地址为 master 地址。这样的结果就是,尽管有多个 slave,然而大家获取 url 的地方只有一个,那就是服务器 master 上的 redis 数据库。并且,由于 scrapy-redis 自身的队列机制,slave 获取的链接不会相互冲突。这样各个 slave 在完成抓取任务之后,再把获取的结果汇总到服务器上(这时的数据存储不再在是 redis,而是 mongodb 或者mysql等存放具体内容的数据库了)这种方法的还有好处就是程序移植性强,只要处理好路径问题,把 slave 上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情。19.分布式爬虫主要解决什么问题
ip、带宽、cpu、io
20.robots协议是什么?
Robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也就是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。因其不是命令,故需要搜索引擎自觉遵守。
21. mysql的索引在什么情况下失效
1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2.对于多列索引,不是使用的第一部分,则不会使用索引
3.like查询以%开头
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引22.MySQL 有什么引擎,各引擎之间有什么区别?
主要 MyISAM 与 InnoDB 两个引擎,其主要区别如下:
1、InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM就不可以了;
2、MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及到安全性较高的应用;
3、InnoDB 支持外键,MyISAM 不支持;
4、MyISAM 是默认引擎,InnoDB 需要指定;
5、InnoDB 不支持 FULLTEXT 类型的索引;
6、InnoDB 中不保存表的行数,如 select count() from table 时,InnoDB;需要扫描一遍整个表来计算有多少行,但是 MyISAM 只要简单的读出保存好的行数即可。注意的是,当 count()语句包含 where 条件时 MyISAM 也需要扫描整个表;
7、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM表中可以和其他字段一起建立联合索引;
8、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重建表;
9、InnoDB 支持行锁(某些情况下还是锁整表,如 update table set a=1 where user like ‘%lee%‘
23.HTTPS 是如何实现安全传输数据的
客户端(通常是浏览器)先向服务器发出加密通信的请求
服务器收到请求,然后响应
客户端收到证书之后会首先会进行验证
服务器收到使用公钥加密的内容,在服务器端使用私钥解密之后获得随机数pre-master secret,然后根据radom1、radom2、pre-master secret通过一定的算法得出session Key和MAC算法秘钥,作为后面交互过程中使用对称秘钥。同时客户端也会使用radom1、radom2、pre-master secret,和同样的算法生成session Key和MAC算法的秘钥。
然后再后续的交互中就使用session Key和MAC算法的秘钥对传输的内容进行加密和解密。24. 如何循环抓取一个网站的 1000 张图片?
流程大概是这样
找到所有页数
---- 遍历所有的页数
---- 遍历当前页的所有相册 ( 给每个相册建立一个目录 )
---- 遍历当前相册的所有图片 ( 遍历此相册的所有页 ( 遍历当前页的所有照片并
找到图片的 url))
---- 获得图片 url 就存起来 , 然后通过图片 url 下载图片。
---- 引用计数当图片下载量达到
1000 张时,停止爬取
25.登陆古诗文网:手动识别验证码。完成模拟登陆。
import requests
from bs4 import BeautifulSoup
import urllib.request
import pytesseract
from PIL import Image
from PIL import ImageEnhance
def shibie(filepath):
# 打开图片
img = Image.open(filepath)
img = img.convert('RGB')
enhancer = ImageEnhance.Color(img)
enhancer = enhancer.enhance(0)
enhancer = ImageEnhance.Brightness(enhancer)
enhancer = enhancer.enhance(2)
enhancer = ImageEnhance.Contrast(enhancer)
enhancer = enhancer.enhance(8)
enhancer = ImageEnhance.Sharpness(enhancer)
img = enhancer.enhance(20)
# 处理图片,提高图片的识别率
# 转化为灰度图片
img = img.convert('L')
# img.show()
# 对图片进行二值化处理
threshold = 140
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
out = img.point(table, '1')
# out.show()
# exit()
# 将图片转化为RGB模式
img = img.convert('RGB')
return pytesseract.image_to_string(img)
i = 0
while 1:
# 创建一个会话
s = requests.Session()
# 发送get请求
deng_url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
r = s.get(deng_url, headers=headers)
# 生产soup对象
soup = BeautifulSoup(r.text, 'lxml')
# 获取验证码的url
image_src = 'https://so.gushiwen.org' + soup.find('img', id='imgCode')['src']
# 将这个图片下载到本地
r = s.get(image_src, headers=headers)
with open('code.png', 'wb') as fp:
fp.write(r.content)
# 获取页面中隐藏的两个数据
view_state = soup.find('input', id='__VIEWSTATE')['value']
view_generator = soup.find('input', id='__VIEWSTATEGENERATOR')['value']
# code = input('请输入验证码')
code = shibie('code.png')
# 抓包,抓取post请求,然后通过代码模拟发送post请求
post_url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': view_state,
'__VIEWSTATEGENERATOR': view_generator,
'from': 'http://so.gushiwen.org/user/collect.aspx',
'email': '1090509990@qq.com',
'pwd': '123456',
'code': code,
'denglu': '登录',
}
r = s.post(url=post_url, headers=headers, data=data)
i += 1
print('这是第%s次登录' % i)
# print(r.text)
if '退出登录' in r.text:
break
print('登录成功')
python26.bs4方法学习
html插件 emmet
(1)根据标签名查找
soup.a 查找得到的是第一个符合要求的标签
(2)获取属性、内容
soup.a['href']
soup.a.attrs 所有的属性和值,返回了一个字典
soup.a.string
soup.a.text
soup.a.get_text()
获取标签内容,如果标签里面只有内容,这三个都是一样的
如果标签里面还有标签,那么string获取的为None,另外两个获取的是纯文本信息
(3)find
返回一个对象,这个对象可以直接获取其属性和文本内容
soup.find('a') 根据标签名查找,找到的是第一个
soup.find('a', id='xxx')
soup.find('a', class_='xxx') 找到的是第一个
soup.find('a', title='xxx') 找到的是第一个
(4)find_all
返回的是一个列表,列表里面都是每一个对象
find_all('a')
find_all(['a', 'b'])
find_all('b', class_='xxx') 找到所有的指定class的标签
find_all('b', class_='xxx', limit=2) 只取前两个
(5)select
返回的是一个列表,列表里面都是对象
选择,选择器的东西
css,层叠样式表,jquery里面也有
常见的选择器:
标签选择器
类选择器
.类名
id选择器
#id名
属性选择器
input[name=user]
a[title=lala]
层级选择器
div .dudu #hehe a
【注】后面的节点是前面节点子孙节点就可以
div > .dudu > #hehe > div
【注】后面的节点必须是前面节点的直接子节点
【注1】select方法返回的是一个列表
【注2】节点对象也拥有select方法
下载三国演义
滚滚长江东逝水,浪花淘尽英雄,是非成败转头空,青山依旧在,几度夕阳红
白发渔樵江渚上,惯看秋月春风,一壶浊酒喜相逢,古今多少事,都付笑谈中
智联招聘
https://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC&kw=c&p=2
jl : 城市定位
kw : 岗位关键字
p : 搜索页码
内容有:职位名称、公司名称、职位月薪、工作地点、发布时间
python27.xpath学习
xml和html的不同
(1)html标签被预定义,xml标签需要自己定义
(2)html设计用来显示数据,xml设计用来传输数据
xpath教程
常用路径表达式
/ : 从根节点开始查找
// : 从任意位置开始查找
. : 从当前节点开始查找
.. : 从上一级节点开始查找
@ :选取指定属性
bookstore/book : 查找bookstore下面的所有book节点,该book必须是bookstore的直接子节点
//book : 查找所有的book
bookstore//book : 查找bookstore下面的所有book节点,但是该book是bookstore的子节点或者子孙节点
//@lang : 查找所有有lang属性的节点
bookstore/book[1] : 取出bookstore下面的第一个本book
bookstore/book[last()] : 取出bookstore下面的最后一个本book
bookstore/book[last()-1] : 取出bookstore下面的倒数第二本book
//title[@lang] : 查找所有的有lang属性的title节点
//title[@lang='eng'] :查找所有lang属性为eng的title节点
* :匹配所有的节点
@* : 匹配所有的属性节点
xpath在html中应该如何使用
插件的安装
点击三个点==》更多工具==》扩展程序,将xpath.crx拖到谷歌窗口即可安装成功,成功之后,在浏览器右上角有×的标志
启动和关闭插件
ctrl+shift+x
xpath使用
属性定位
input[@id="kw"]
层级定位、索引定位
//div[@class="head_wrapper"]/div[@id="u1"]/a[1]
//div[@class="head_wrapper"]//a
模糊匹配
contains
//a[contains(@class,"lb")]
查找所有的a,class属性值包含lb的a
//a[contains(text(),"新")]
查找所有的a,文本内容包含 新 的a
starts-with
//a[starts-with(@class,"lb")]
查找所有的a。class属性值以lb开头的
//a[starts-with(text(),"更多")]
查找所有的a,文本内容以更多开头
获取文本内容
//div[@id="u1"]/a[1]/text()
获取属性值
//div[@id="u1"]/a[2]/@href
//div[@id="u1"]/img[1]/@src
代码学习
pip install lxml
python28.正则表达式
为什么引入正则表达式?写一个规则,这个规则就能匹配所有符合这个规则的字符串
规则:
单字符匹配
\d : 一个数字字符 digit (牢记)
\D : 非数字字符
\w : 数字、字母、下划线 word (牢记)
\W : 非\w
\s : 匹配任意空白字符 space (牢记)
\S : 非空白字符
[] : [1-5] [a-d] [aeiou] (牢记)
[0-9] [a-zA-Z_0-9]
. : 匹配除了换行符以外任意字符 (牢记)
数量修饰
{m} : 修饰前面的字符出现m次
{m,} : 修饰前面的字符出现至少m次
'1234567' \d{3,5} 贪婪
{m,n} : 修饰前面的字符最少出现m次,最多n次
{0,} : * 能够出现任意多次
{1,} : + 至少一次
{0,1} : ? 可有可无
边界:
^ : 以某某开头
$ :以某某结尾
分组(子模式)
() 由小括号括起来的正则
视为一个整体 (\d{3}){2}
子模式
\1 \2
贪婪模式
.* 尽可能多的匹配
.+
.*? 非贪婪 尽可能少的匹配
.+? 非贪婪
修正符
re.I : 忽略大小写
re.M : 多行模式
re.S : 单行模式
导入一个模块 re
re.compile() : 生成正则对象(牢记)
re.match() :从字符串开头匹配
re.search() : 从字符串任意位置匹配,只找一个(牢记)
re.findall() :从字符串中查找所有匹配的内容(牢记)
返回一个列表,只找到子模式匹配到的内容
re.sub() :正则替换
正则匹配邮箱: /^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/;
正则匹配手机号码: 1\d{10}
python原文:https://www.cnblogs.com/lpdeboke/p/12408497.html