本文分为两个部分,第一个部分是有关今年新出的有关深度造假视频的数据集的新论文,第二个部分是今年新出的关于检测深度造假的方法的论文。
关于伪造人脸和视频(Deepfake)去年已经有不少的方法,但由于数据集不统一,测试基准不统一,一直没有没有一个很好的对比结果。随着FaceForensics++数据集的慢慢完善,还有DFDC数据集兼Kaggle比赛的进行,越来越多的方法多开始使用这两个主流数据集开始对比。但是因为数据集质量不足等各种问题,对于创建一较为合格的主流数据集也是今年的一个挑战。
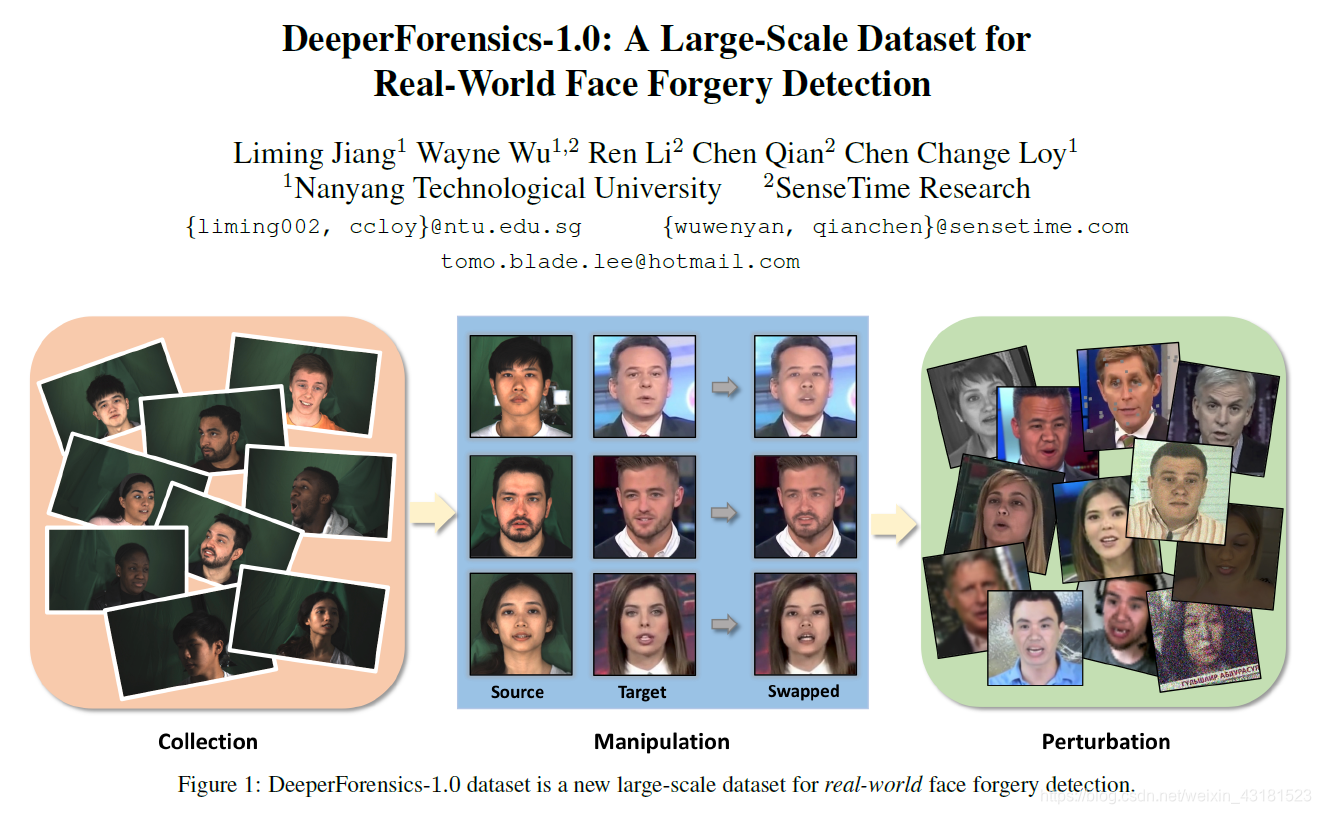
文章链接:DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
GitHub地址:https://github.com/EndlessSora/DeeperForensics-1.0
该文章由新加坡南洋理工大学和商汤科技合作研究发布,该文主要根据现有的相关的数据集的缺点和主要面临的挑战,提出了Deeperforensics-1.0数据集,并提出了新的测试基准。
针对现有的数据集,如:UADFV, DeepFake-TIMIT, Celeb-DF, FaceForensics++, Deep Fake Detection和DFDC preview dataset,它们主要的缺点如下:
所以作者认为,随着造假换脸视频技术的发展,这些数据集不足以训练一个合格的模型,可以在实际生化中进行有效的伪造检测。
该数据集包括60,000个视频,总共1760万帧。构造数据集满足:
构造的主要过程就是本文开头的图片显示的三个过程:收集——变换——加入干扰(模拟实际视频的情况)
7种干扰为下图: 且每一种干扰都分为5个强度,使得最后的数据集扩充。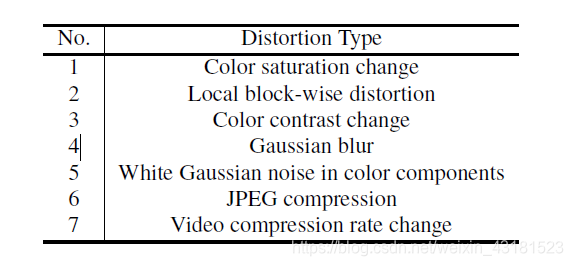
所以在构建数据集时主要面临的挑战为:
针对以上两个挑战,作者通过100人的知情同意下,收集新的人脸数据作为 source videos,用FaceForensics++数据集的youtube视频作为target videos,并设计一种新的方法DeepFake Variational AutoEncoder(DF-VAE)【此方法在后文会简要介绍】,以变换收集到的现有视频。下图是具体与现有数据集的对比表格: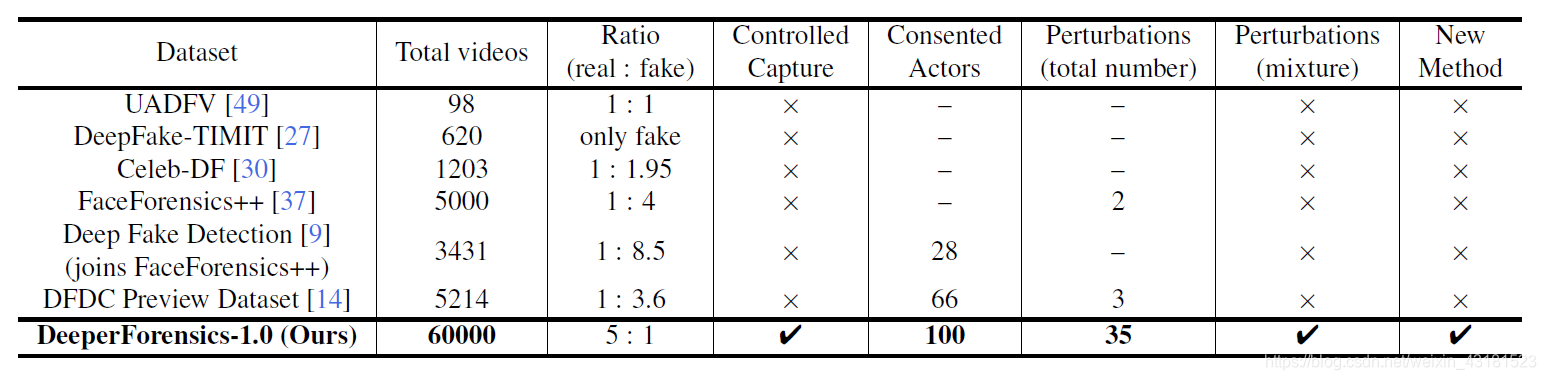
Sourse视频收集过程

上图是证明了使用相同方法的情况下,运用经过允许拍摄的多表情,多头部姿势,多光照条件的人物视频素材构造的源视频数据集经过换脸后的假视频的效果会更加逼真。
此外,还通过故意添加失真和扰动来模拟实际视频的情况,从而使数据集有多样性。同时,使用隐藏测试集(这些视频在人类观察者中获得很高的欺骗性)对五个代表性开源伪造检测方法(C3D ,时间分段网络(TSN),In?ated 3D ConvNet(I3D)、ResNet + LSTM和 XceptionNet)进行基准测试。
为了解决先前数据集中假视频的低视觉质量问题,该文在制作高质量换脸方法时考虑了三个关键要求:

该方法主要框架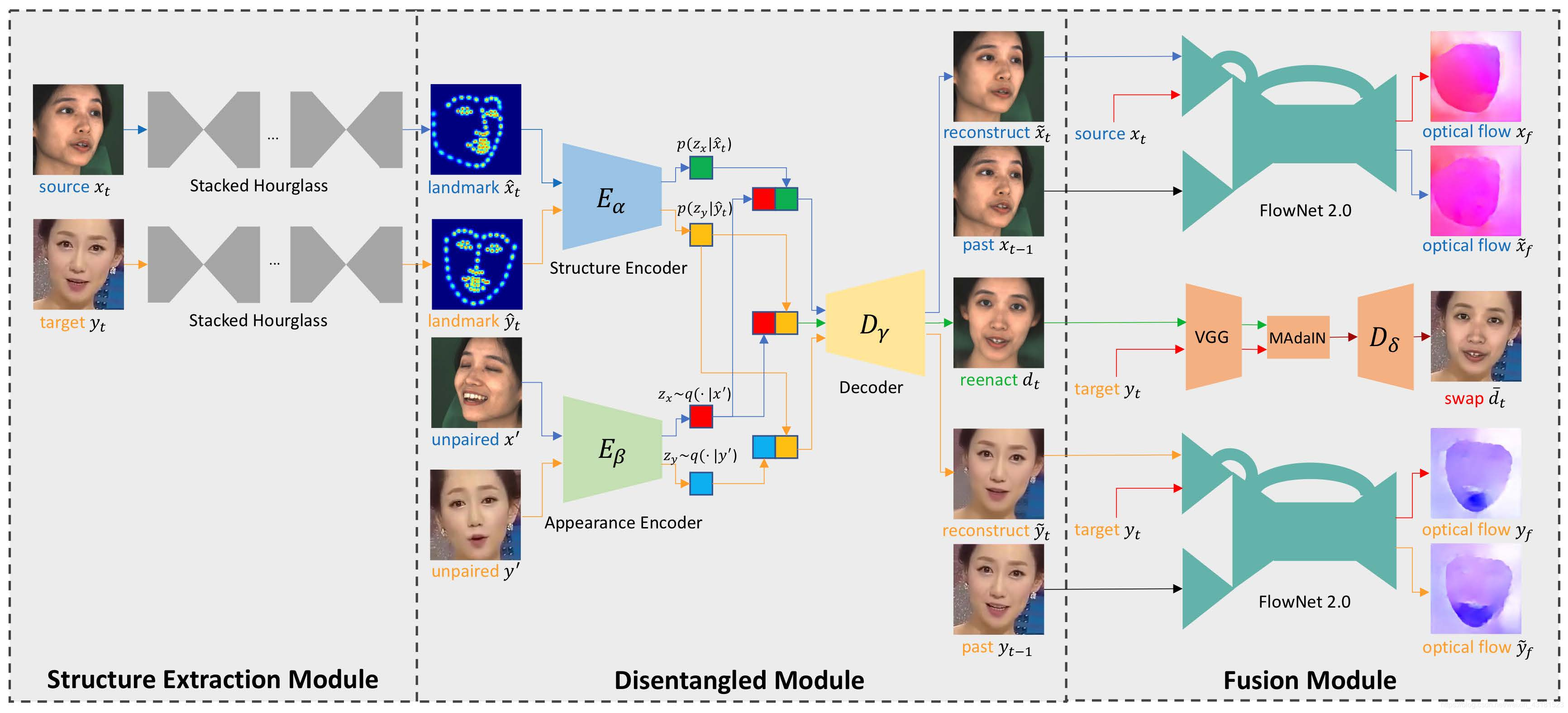
DeepFake–VAE的主要框架:在训练是,通过提取landmark并构造未配对的样本作为条件,分别以蓝色和橙色箭头重构源和目标的脸部。重建后利用光学流的差异最小化,以改善时间连续性。作为推论,交换latent codes并以绿色箭头获得重构的脸部。后续的MAdaIN模块将重构的面孔与原始背景融合在一起,最终成交换的脸部。
为了使面部重构效果更加具有鲁棒性,作者认为应该彻底弄清面部的结构(即表情和姿势)和外观表示形式(即纹理,肤色等)并且分离它们,但是这种分离非常困难,因为结构和外观表示方式并不是独立的。该方法的创新和突破也是在于此。这也是在框架中第二个模块的设计,由两个编码器Eα,Eβ和一个解码器DY,显式结构热图以及未配对的数据构造共同迫使Eα学习结构信息,而Eβ学习外观信息。
相较以往的Deepfake方法,该方法模型训练和视频生成的时间是1/5,但质量没有下降。
为了检查DeeperForensics-1.0数据集的质量,作者聘用了100人来测试,其中大多数专门从事计算机视觉研究。测试者针对DeeperForensics-1.0和六个以前的数据集中各随机选择30个视频进行测试。尽管Celeb-DF 的真实性得分也很高,但此数据集规模却更大。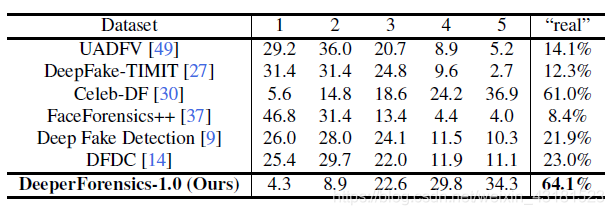
目前这个新的数据集开没有开放下载,其用到的DF-VAE方法也会在将来开源。我将会持续跟踪这个项目。
关于伪造人脸和视频去年已经有不少的方法,但由于数据集不统一,测试基准不统一,所以一直没有没有一个很好的对比。随着FaceForensics++数据集的慢慢完善,还有DFDC数据集兼Kaggle比赛的进行,越来越多的方法多开始使用这两个主流数据集开始对比。但是因为数据集质量不足等各种问题,对于创建一较为合格的主流数据集也是今年的一个挑战。
该文章由韩国成均馆大学发表于Arxiv:http://arxiv.org/pdf/2001.01265v1.pdf
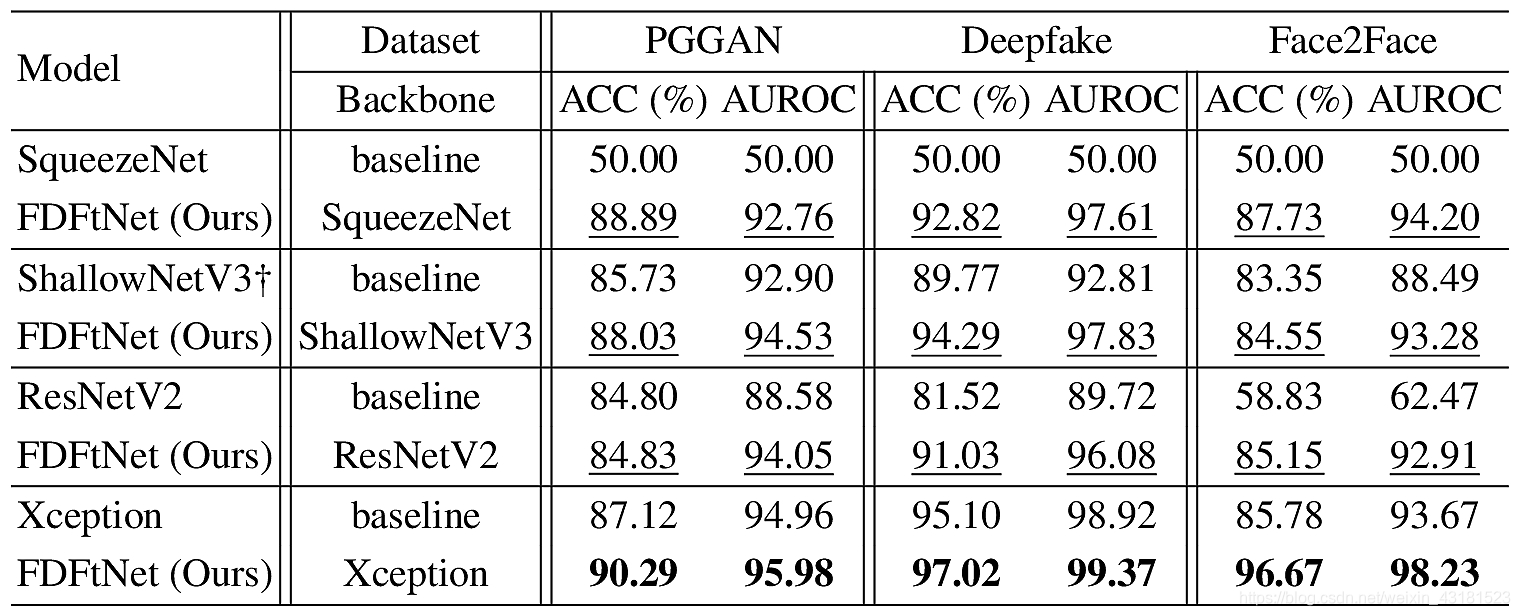
作者提出了一种基于轻量级的微调神经网络,用于分类真假,称为伪造检测微调网络(FDFtNet)。
它能够检测许多新的伪造人脸图像生成模型,并且可以轻松实现。结合现有的图像分类网络,并在一些数据集上进行微调。方法的核心是引入一个基于图像的自我关注模块,称为Fine-Tune Transformer,该模块仅使用关注模块和下采样层。该模块被添加到预训练模型中,并根据一些数据进行微调,以搜索新的特征空间集以检测伪图像(视频)。它们在基于GANs的数据集(PGGAN)和基于Deepfake的数据集(Deepfake和Face2Face)上使用FDFtNet进行了实验,其输入图像分辨率为64×64(低分辨率更有难度)。
该方法与其他伪造检测方法的主要区别是:利用众所周知的可重用的预训练模型,并且仅用少量数据就对主网络进行了微调,以提高伪造检测性能。FDFtNet模块以黄色和绿色显示:(2)是微调结构,(3)MobileNet V3附加到(1)预训练模型(主网络)上。
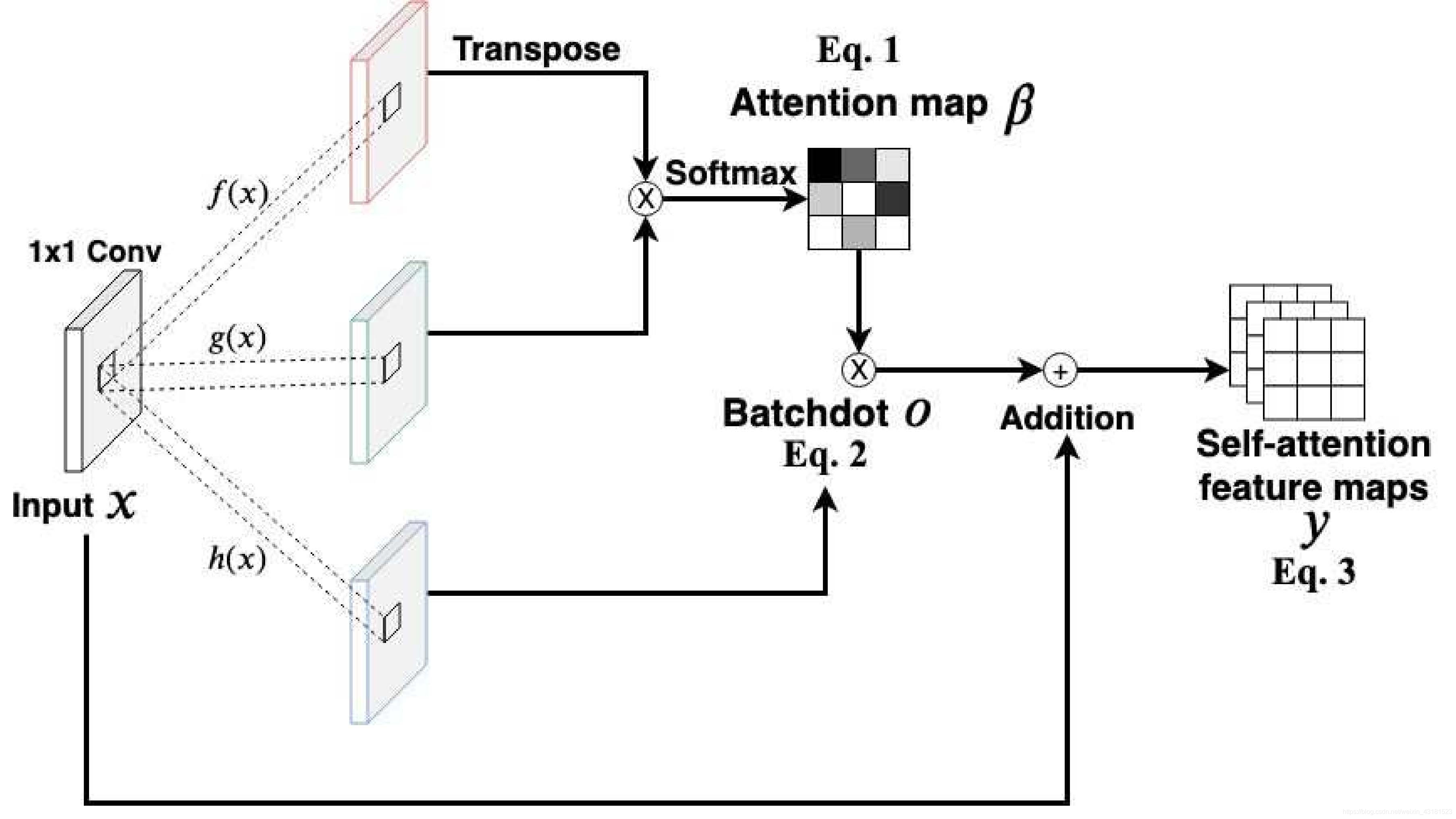
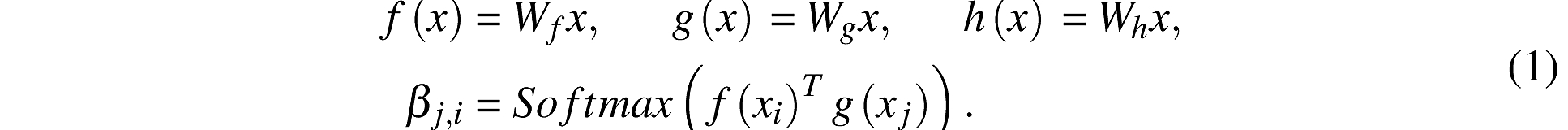
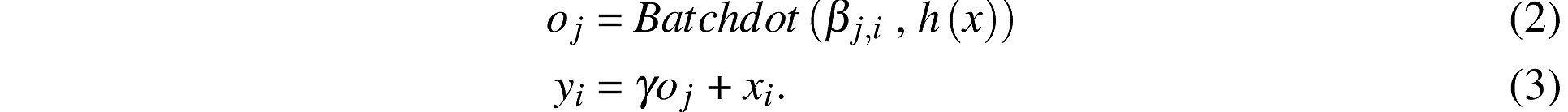
下图是改文章的FFT的说明(使用了三次):Conv,BN,DConv和GAP分别表示卷积,批量归一化,深度可分离卷积和全局平均池化操作。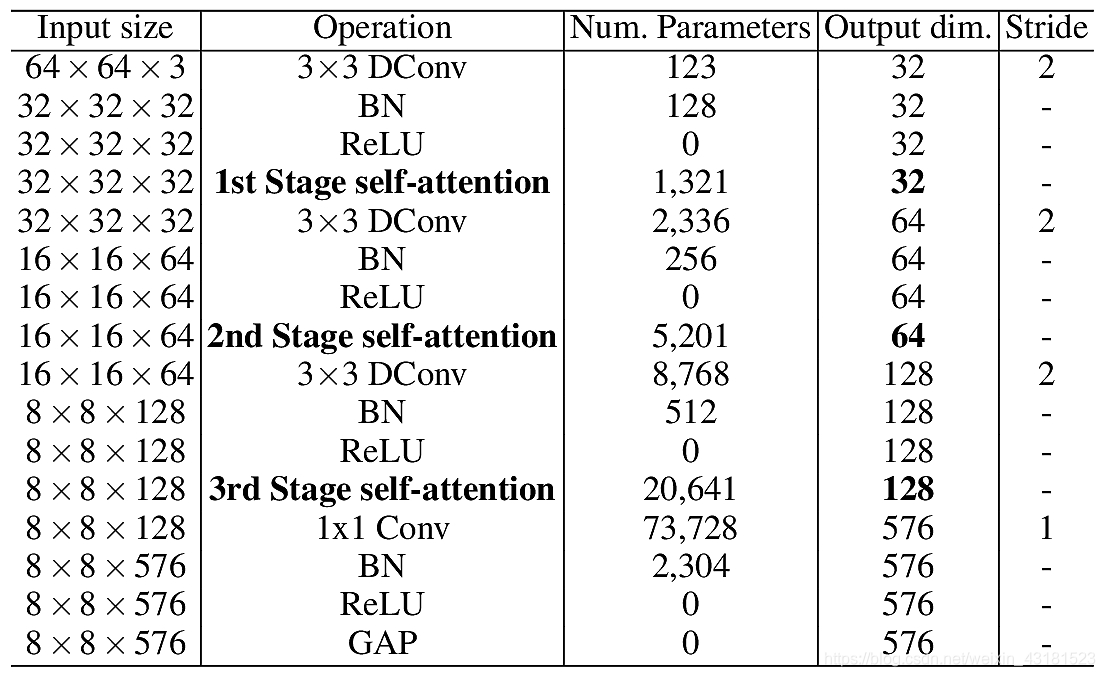
作者选择MBblockV3,因为它是用于在预训练特征空间上有效提取特征空间。FTT和MBblockV3分别重复使用了M次和N次。它们每个都添加到最终分类层之前。经过他们的实验,N = 4,为微调提供了最佳性能,另外还对激活函数进行了修改。
下图是MBblockV3的具体说明:W = H = 8,C = 256。 W,H和C表示输入大小。如果3x3 DConv的步幅为2,则跳过加法运算,并且将W和H除以2。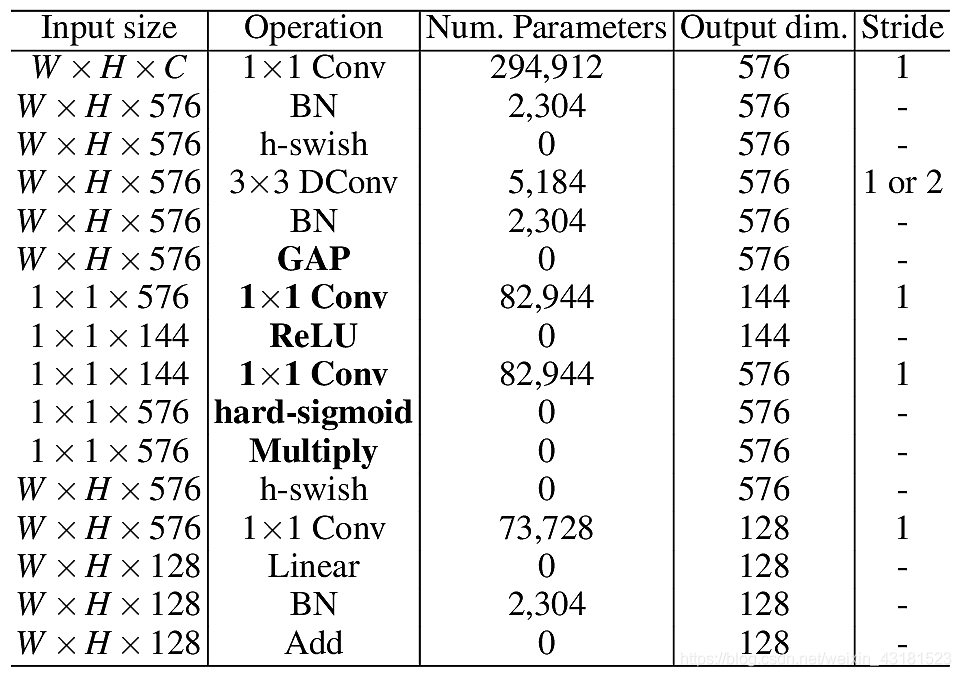
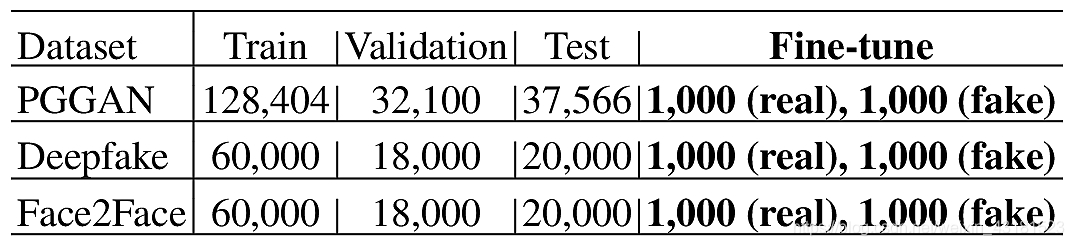
所有数据集都有训练,验证,测试和微调集。 每个数据集的大小如上图所示。训练集仅分别针对1000个样本对真实和伪造图像进行了微调。

代码地址:https://anonymous.4open.science/r/FDFtNet/
https://github.com/cutz-j/FDFtNet
(目前还不完整,作者正在编辑中…,我也正在测试他的代码)
顺便最后提一下,最近也有人发表了有关这一方面的综述类的文章,感兴趣的可以看一下,顺便也贴上去年这方面的综述文章也是第一篇,可以对比学习,追踪感兴趣的部分来研究。
今年综述:DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
去年综述:Deep Learning for Deepfakes Creation and Detection
原文:https://www.cnblogs.com/panicwq/p/12382651.html