概述
spark中的三大数据类型:
RDD:分布式数据集
累加器:分布式只写变量,可以支持多个分区同时向该RDD写入数据,并将数据返回
广播变量:分布式只读变量
累加器
示例程序如下:系统通过引用一个外部的自由变量sum,将多个分区的数据累加到sum上。
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(sparkConf) val raw: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) //raw.reduce(_+_); var sum = 0; raw.foreach(i => sum = i+sum) println(sum) } }
打印结果为0;分析如下:
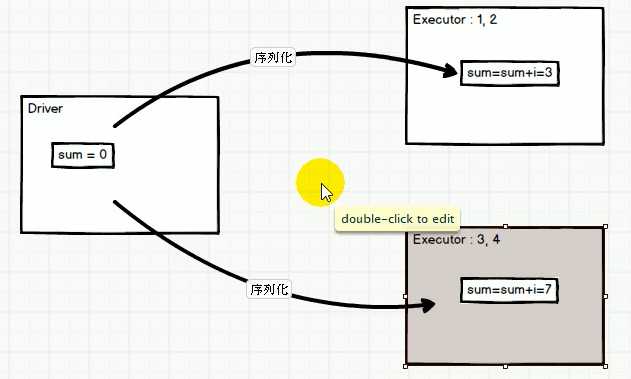
sum变量被读取到各个分区,在executor分别端进行累加,但是这个“更改”无法在executor端之间传递,也无法反馈到driver端。
将sum类型改为累加器类型:
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(sparkConf) val raw: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) //raw.reduce(_+_); val sum: LongAccumulator = sc.longAccumulator raw.foreach{ i => sum.add(i) } println(sum.value) }
输出结果为10;这说明sum在各个分区内的修改,在driver与executor端之间形成同步。
查看其原码:
def longAccumulator: LongAccumulator = { val acc = new LongAccumulator register(acc) acc } class LongAccumulator extends AccumulatorV2[jl.Long, jl.Long]{...}
/**
* The base class for accumulators, that can accumulate inputs of type `IN`, and produce output of
* type `OUT`.
*
* `OUT` should be a type that can be read atomically (e.g., Int, Long), or thread-safely
* (e.g., synchronized collections) because it will be read from other threads.
*/
abstract class AccumulatorV2[IN, OUT] extends Serializable{...}
它继承了抽象类AccumulatorV2,这是一个泛型类,泛型参数IN,OUT分别表示该累加器的输入类型(接受什么样的变量类型作为输入)和输出类型(以什么样的变量类型输出)。而且要注意:输出类型要是一个线程安全的类,因为这涉及到多个线程同时对他访问。
自定义累加器
自定义一个累加器,从多个分区接收字符串(IN)的输入,对其中的字符串进行过滤,过滤后的字符串保存在一个List集合(OUT)里。该集合应保证线程安全。然后实现该抽象类的所有抽象方法即可:
package accumulator import java.util import org.apache.spark.util.AccumulatorV2 class StrAccumulator extends AccumulatorV2[String,java.util.Vector[String]]{ val vector = new util.Vector[String]() //是否为初始状态(是否被写入) override def isZero: Boolean = vector.isEmpty //复制 override def copy(): AccumulatorV2[String, util.Vector[String]] = new StrAccumulator //重置 override def reset(): Unit = vector.clear() //定义变量的写入 override def add(v: String): Unit = { vector.add(v) } //两个累加器的合并 override def merge(other: AccumulatorV2[String, util.Vector[String]]): Unit = vector.addAll(other.value) //定义变量的输出 override def value: util.Vector[String] = vector }
测试代码如下:
首先创建累加器变量,在通过sc注册该变量;
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(sparkConf) val raw: RDD[String] = sc.makeRDD(Array("hadoop", "hbase", "hive", "scala")) //创建累加器变量 val accumulator = new StrAccumulator(); //注册该累加器变量 sc.register(accumulator) raw.foreach(str => accumulator.add(str)) val value: util.Vector[String] = accumulator.value for(i <-0 until value.size()) println(value.elementAt(i)) }
打印结果如下:
hadoop
hive
hbase
广播变量
Spark中分布式执行的代码需要传递到各个Executor的Task上运行。对于一些只读、固定的数据(比如从DB中读出的数据),每次都需要Driver广播到各个Task上,这样效率低下。广播变量允许将变量只广播(提前广播)给各个Executor。该Executor上的各个Task再从所在节点的BlockManager获取变量,而不是从Driver获取变量,从而提升了效率。
一个Executor只需要在第一个Task启动时,获得一份Broadcast数据,之后的Task都从本节点的BlockManager中获取相关数据。

不使用广播变量的情形
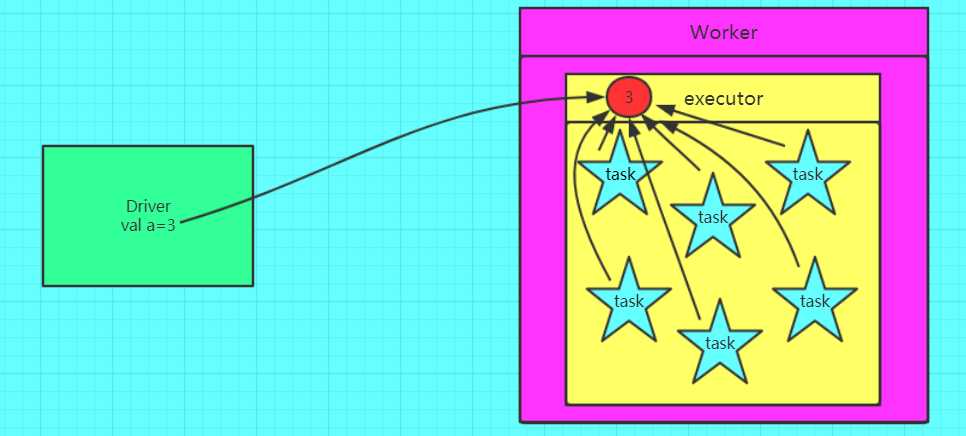
使用广播变量的情形
图片出自:https://www.cnblogs.com/frankdeng/p/9301653.html
示例代码:利用广播变量,实现join操作。把rdd2作为一个参照,它需要分发到各个executor上执行,因此声明为广播变量。
object Demo3 { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf(). setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(sparkConf) val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 1), (2, 2), (3, 3), (4, 4))) val tuples = List((1, "a"), (2, "b"), (3, "c"), (4, "d")) //创建广播变量 val rdd2: Broadcast[List[(Int, String)]] = sc.broadcast(tuples) val value: RDD[(Int, (Int, Any))] = rdd1.map {
//使用广播变量 case (key, value) => { var v2: Any = null for (t <- rdd2.value) { if (t._1 == key) v2 = t._2 } (key, (value, v2)) } } value.foreach(println) } }
原文:https://www.cnblogs.com/chxyshaodiao/p/12375044.html