set & map
前面介绍了二分搜索树的底层实现,这里介绍两个高层的数据结构:集合 和 映射
类似于栈和队列,这种就像我们定义好了相应的使用接口 ,以及它本身所具有的性质,然后我们就可以使用它。
但是这种高层的数据结构的底层其实是可以多种多样的,比如说 栈和队列 的底层实现既可以是 动态数组 也可以是 链表,这里的 Set 和 Map 也是如此。
它这个容器中的元素 不能重复, 它的主要应用就是 可以帮助我们去重,
上一节的二分搜索树 中我们知道,它里面不能放重复的元素,所以 二分搜索树是个非常好的 实现 ‘集合’ 的底层数据结构!!

这里最主要的是 add() 操作,它不能添加重复元素,
容易发现,这些接口,二分搜索树都是可以实现的,我们这里是 用 二分搜索树 封装一下,就实现自己的集合了,

1 package zcb.demo01; 2 import java.util.LinkedList; 3 import java.util.Queue; 4 import java.util.Stack; 5 6 public class BinarySearchTree<T extends Comparable<T>> { 7 //这里对树中存储的类型做了限制,它必须具有可比较性。 8 private class Node{ 9 public T t; 10 public Node left,right; 11 12 //Node 构造函数 13 public Node(T t){ 14 this.t = t; 15 this.left = null; 16 this.right = null; 17 } 18 19 } 20 21 //二分搜索树 的成员变量:1,根节点,2,size 22 private Node root; 23 private int size; 24 //二分搜索树的构造函数 25 public BinarySearchTree(){ 26 //此时一个元素都没有存 27 this.root = null ; 28 this.size = 0; 29 } 30 31 public int getSize(){ 32 return this.size; 33 } 34 public boolean isEmpty(){ 35 return this.size == 0; 36 } 37 38 //向二分搜索树 中添加新的元素e 39 public void add(T t){ 40 this.root = add(this.root,t); 41 } 42 //向 以node 为根节点 的 二分查找树中插入 元素 43 //返回 插入新节点后 二分搜索树的根 44 private Node add(Node node,T t) { 45 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 46 this.size ++; 47 return new Node(t); 48 } 49 if (t.compareTo(node.t) < 0){ 50 node.left = add(node.left, t); 51 } 52 else if(t.compareTo(node.t) >0 ){ 53 node.right = add(node.right, t); 54 } 55 return node; 56 } 57 58 59 //看 二分搜索树 中是否存在某个元素 t 60 public boolean contains(T t){ 61 62 return contains(this.root,t); 63 } 64 65 //看 以node 为根的二分搜索树 中是否存在某个元素 t 66 private boolean contains(Node node,T t){ 67 if(node == null){ 68 return false; 69 } 70 if(t.compareTo(node.t) == 0) 71 return true; 72 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 73 return contains(node.left,t); 74 else //此时只可能出现在右子树。 75 return contains(node.right,t); 76 } 77 78 // 二分搜索树的前序遍历 79 public void preOrder(){ 80 preOrder(this.root); 81 82 } 83 //遍历 以 node 为根节点的二分搜索树 84 private void preOrder(Node node){ 85 if(node == null) 86 return; 87 else 88 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 89 90 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 91 preOrder(node.right); 92 } 93 94 // 二分搜索树的前序遍历 (使用非递归 NR 实现,利用 栈 来实现!!!) 95 public void preOrderNR(){ 96 Stack<Node> stk = new Stack<>(); 97 stk.push(this.root); //将根节点的值压入栈中。 98 99 while (!stk.isEmpty()){ 100 Node temp = stk.pop(); 101 System.out.println(temp.t); //访问 102 103 if(temp.right != null) 104 stk.push(temp.right); 105 if(temp.left != null) 106 stk.push(temp.left); 107 } 108 } 109 110 111 //二分搜索树的中序遍历 先左 中 然后再右 112 public void midOrder(){ 113 midOrder(this.root); 114 } 115 //中序遍历 遍历以node 为根节点的树 116 private void midOrder(Node node){ 117 if(node == null) 118 return; 119 120 //先遍历该节点的左子树 121 midOrder(node.left); 122 System.out.println(node.t); 123 midOrder(node.right); 124 } 125 126 //二分搜索树后序遍历 先左 右 然后 当前节点 127 public void lastOrder(){ 128 lastOrder(this.root); 129 } 130 //后序遍历 遍历 以node 为根节点的二叉搜索树 131 private void lastOrder(Node node){ 132 if(node == null) 133 return; 134 135 //先遍历 左子树 136 lastOrder(node.left); 137 lastOrder(node.right); 138 System.out.println(node.t); 139 } 140 141 //二分搜索树的 层序遍历 142 public void levelOrder(){ 143 Queue<Node> queue = new LinkedList<>(); //因为 Queue本质是个接口,我们要选择它的一个实现类 144 145 queue.add(this.root); 146 147 while (!queue.isEmpty()){ 148 Node temp = queue.remove(); 149 System.out.println(temp.t); //访问 150 151 if(temp.left != null) 152 queue.add(temp.left); 153 if(temp.right != null) 154 queue.add(temp.right); 155 } 156 } 157 158 //寻找二分搜索树中的最小值 159 public T getMinimum(){ 160 if(this.size == 0) 161 throw new IllegalArgumentException("此时,树中为空!"); 162 163 return getMinimum(this.root).t; 164 } 165 //返回以 node为根节点中的 最小值 。 166 private Node getMinimum(Node node){ 167 if(node.left == null) 168 return node; 169 return getMinimum(node.left); 170 } 171 172 173 //寻找二分搜索树中的最大值 174 public T getMaximum(){ 175 if(this.size == 0) 176 throw new IllegalArgumentException("此时,树中为空!"); 177 return getMaximum(this.root).t; 178 } 179 //返回以 node为根节点中的 最大值 。 180 private Node getMaximum(Node node){ 181 if(node.right == null) 182 return node; 183 return getMaximum(node.right); 184 } 185 186 //从二分搜索树中 删除最小值所在的节点。返回最小值 187 public T removeMin(){ 188 T ret = getMinimum(); //获取最小值 189 190 //删除最小值所在的节点。 191 this.root = removeMin(this.root); 192 return ret; 193 } 194 //删除掉 以 node为根节点的树中的最小节点, 195 //并将删除节点后的 新的二分搜索树的根节点 返回出来 196 private Node removeMin(Node node){ 197 if(node.left == null) { 198 Node temp = node.right; //此时node.right 可能为null ,也可能不为空, 199 node.right = null; 200 this.size --; 201 return temp; 202 } 203 204 node.left = removeMin(node.left); 205 return node; 206 } 207 208 //从二分搜索树中 删除最大值所在的节点。返回最大值 209 public T removeMax(){ 210 T ret = getMaximum(); 211 212 this.root = removeMax(this.root); 213 return ret; 214 } 215 216 //删除 以 node 为根节点 的二叉树, 217 //返回 删除最小值节点 之后的新的 二叉树的 根节点 218 private Node removeMax(Node node){ 219 if(node.right == null){ 220 Node temp = node.left; //此时node.left 可能为null ,也可能不为空, 221 node.left = null; 222 this.size --; 223 return temp; 224 } 225 node.right = removeMax(node.right); 226 return node; 227 } 228 229 //从二分搜索树上 删除任意元素 t 230 public void remove(T t){ 231 this.root = remove(this.root,t); 232 } 233 // 删除 以 Node 为根节点的二分搜索树中的任意值 234 // 返回删除之后 新的二分搜索树的 根节点 235 private Node remove(Node node,T t){ 236 if(node == null) 237 return null; //没找到要删除的t ,此时什么都不干! 238 if(t.compareTo(node.t) < 0) { 239 node.left = remove(node.left, t); 240 return node; 241 } 242 else if(t.compareTo(node.t) >0) { 243 node.right = remove(node.right, t); 244 return node; 245 }else{ 246 //此时就找到了要删除的元素! 247 if(node.left == null){ //此时,是只有右子树的情况 右子树也可能为null 248 Node temp = node.right; 249 node.right = null; 250 this.size --; 251 return temp; 252 } 253 if(node.right == null){ //此时,是只有左子树的情况 左子树也可能为null 254 Node temp = node.left; 255 node.left = null; 256 this.size --; 257 return temp; 258 } 259 //此时 是该节点既有左子树,又有右子树,而且左右子树都不为null 260 Node temp = getMinimum(node.right); // 找到当前节点 的右子树中的 最小节点。 261 temp.right = removeMin(node.right); //删除 右子树的最小节点,并将右子树的根节点 连在temp。right上。 262 temp.left = node.left; 263 //此时的node 就可以被删除了。 264 node.left = node.right = null; //或者用 node =null; 直接删除 265 // this.size --; 它是不需要的,因为我们在 removeMin 中已经进行了 this.size-- ; 266 return temp; 267 } 268 } 269 270 271 @Override 272 public String toString(){ 273 StringBuilder builder = new StringBuilder(); 274 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 275 return builder.toString(); 276 } 277 278 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 279 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 280 if(node == null){ 281 builder.append(generateDepthInfo(depth)+"|null \n"); 282 return; 283 } 284 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 285 286 generateBinarySearchTreeString(node.left,depth+1,builder); 287 generateBinarySearchTreeString(node.right,depth+1,builder); 288 } 289 //生成 关于深度的字符串。 290 private String generateDepthInfo(int depth){ 291 StringBuilder res = new StringBuilder(); 292 for (int i =0;i<depth;i++ ){ 293 res.append("="); //一个= 对应一个深度。 294 } 295 return res.toString(); 296 } 297 298 }
1 package zcb.demo01; 2 3 public interface MySet<T> { 4 // 自定义集合 的接口 5 6 void add(T t); // 添加元素 7 void remove(T t); // 删除元素 8 boolean contains(T t); // 是否包含某个元素 9 int getSize(); // 获取size 10 boolean isEmpty(); //判断是否 为空 11 }
MySet.java 是我们自定义集合的 接口,
1 package zcb.demo01; 2 /** 3 * 基于二分搜索树 的集合 4 */ 5 public class MySet_BST <T extends Comparable<T> > implements MySet<T> { 6 //<T extends Comparable<T> >意思是里面的元素 必须是可比较的 7 // implements MySet<T> 意思是 这个类 实现了 MySet 这个接口 8 9 private BinarySearchTree<T> bst; // 这个类 主要基于 bst 这个对象 对外不可见 10 11 //这个类的 构造函数 12 public MySet_BST(){ 13 bst = new BinarySearchTree<>(); // new的时候可以不加 泛型 14 } 15 16 // 下面就是 一 一 覆盖我们要实现的 接口中的方法了, 17 @Override 18 public int getSize(){ 19 return bst.getSize(); 20 } 21 22 @Override 23 public boolean isEmpty() { 24 return bst.isEmpty(); 25 } 26 27 @Override 28 public void add(T t) { 29 bst.add(t); 30 } 31 32 @Override 33 public void remove(T t) { 34 bst.remove(t); 35 } 36 @Override 37 public boolean contains(T t) { 38 return bst.contains(t); 39 } 40 41 // 用于输出 42 @Override 43 public String toString() { 44 return bst.toString(); 45 } 46 47 48 49 }
MySet_BST.java 实现了上面的接口, 是我们 实际要用的类,
1 package zcb.demo01; 2 3 public class test { 4 public static void main(String[] args) { 5 MySet_BST<String> mySet_bst = new MySet_BST<>(); 6 mySet_bst.add("tom"); 7 mySet_bst.add("t"); 8 mySet_bst.add("tm"); 9 System.out.println(mySet_bst.getSize()); 10 mySet_bst.add("tom"); 11 System.out.println(mySet_bst.getSize()); 12 13 } 14 }
这里之所以要用 链表再来实现 集合,是因为 二分搜索树 和 链表 同属于动态数据结构 如下:

实现完之后,我们就可以 比较二者的性能,以直观的了解到 二分搜索树的优势所在,
1 package zcb.demo01; 2 3 public interface MySet<T> { 4 // 自定义集合 的接口 5 6 void add(T t); // 添加元素 7 void remove(T t); // 删除元素 8 boolean contains(T t); // 是否包含某个元素 9 int getSize(); // 获取size 10 boolean isEmpty(); //判断是否 为空 11 }
1 package zcb.demo01; 2 public class MySet_LL<T> implements MySet<T>{ 3 private LinkedList<T> linkedList; // 自定义集合 的底层结构 4 public MySet_LL(){ 5 linkedList = new LinkedList(); 6 } 7 // 下面一一 覆盖MySet 接口中的方法即可 8 @Override 9 public int getSize() { 10 return linkedList.getSize(); 11 } 12 @Override 13 public boolean isEmpty() { 14 return linkedList.isEmpty(); 15 } 16 @Override 17 public boolean contains(T t) { 18 return linkedList.contains(t); 19 } 20 // 链表 里本身是 可以包含重复元素的, 21 @Override 22 public void add(T t) { 23 if(!linkedList.contains(t)) 24 linkedList.addFirst(t); // 如果不包含 该元素才添加,否则不添加 25 } 26 @Override 27 public void remove(T t) { 28 linkedList.removeByEle(t); 29 } 30 31 // 输出 32 @Override 33 public String toString() { 34 return linkedList.toString(); 35 } 36 }
上面接口的实现类,
实现类用到的 链表类:
1 package zcb.demo01; 2 public class LinkedList <T> { // 注意 链表这种数据结构 和二分搜索树不一样,它并不要求 元素具有可比性, 3 private class Node{ 4 public T data;//具体数据 5 public Node next; //引用(指针) 6 7 //Node 节点的构造器 8 public Node(T data,Node next){ 9 this.data = data; 10 this.next = next; 11 } 12 public Node(T data){ 13 this(data,null); 14 } 15 public Node(){ 16 this(null,null); 17 } 18 19 @Override 20 public String toString(){ 21 return this.data.toString(); 22 } 23 24 } 25 26 private Node dummyHead; //虚拟头节点 27 private int size; 28 //LinkedList 的构造器 29 30 public LinkedList (){ //此时,当链表初始化的时候就已经存在一个 虚拟的头节点了。 31 dummyHead = new Node(null,null); 32 this.size = 0; 33 } 34 //获取链表中的元素个数 35 public int getSize(){ 36 return this.size; 37 } 38 //返回链表是否为空 39 public boolean isEmpty(){ 40 return this.size ==0; 41 } 42 //在链表 中间 索引(idx) 添加新元素 43 public void insertByIdx(int idx,T newData){ 44 if(idx < 0 || idx > this.size){ 45 throw new IllegalArgumentException("idx 错误!"); 46 } 47 Node tempPtr = new Node(); 48 tempPtr = this.dummyHead; 49 for (int i =0;i< idx;i++){ 50 tempPtr = tempPtr.next; 51 } 52 Node node = new Node(newData,tempPtr.next); 53 tempPtr.next = node; 54 55 this.size ++; 56 } 57 58 //在链表头添加 新的元素 newData 59 public void addFirst(T newData){ 60 insertByIdx(0,newData); 61 } 62 //在链表尾部 添加新元素 63 public void addLast(T newData){ 64 this.insertByIdx(this.size,newData); 65 } 66 67 68 // 获取链表中的元素 69 public T getByIdx(int idx){ 70 if(idx <0 && idx >= this.size) 71 throw new IllegalArgumentException("idx 索引错误!!!"); 72 73 Node curPtr = dummyHead.next; 74 for (int i=0;i<idx;i++){ 75 curPtr = curPtr.next; 76 } 77 return curPtr.data; 78 } 79 //获取链表的第一个元素 80 public T getFirst(){ 81 return getByIdx(0); 82 } 83 //获取 链表的最后一个元素 84 public T getLast(){ 85 return getByIdx(this.size-1); 86 } 87 88 89 //修改链表的第idx 元素为 newData 90 public void setNewData(int idx,T newData){ 91 if(idx <0 && idx>=this.size) 92 throw new IllegalArgumentException("索引错误"); 93 94 Node curPtr = dummyHead.next; 95 for (int i=0;i<idx;i++){ 96 curPtr = curPtr.next; 97 } 98 curPtr.data = newData; 99 } 100 101 //查找 链表中是否存在 元素 data 102 public boolean contains(T data){ 103 Node curPtr = dummyHead.next; 104 while (curPtr != null){ 105 if(curPtr.data.equals(data)) //?????? 106 return true; 107 curPtr = curPtr.next; 108 } 109 return false; 110 } 111 112 //删除 指定的元素 (只删第一个) 113 public void removeByEle(T t){ 114 Node tempPtr = this.dummyHead; 115 // 首先是要查找到 该元素的位置 116 while ( tempPtr.next != null){ 117 if(tempPtr.next.data == t){ 118 // 找到了 119 break; 120 } 121 tempPtr = tempPtr.next; 122 } 123 // 找到之后,就要删除它了, 124 if(tempPtr.next != null){ 125 // 确实找了该元素 126 Node delNode = tempPtr.next; // 待删除的节点 127 tempPtr.next = delNode.next; 128 129 delNode.next = null; 130 this.size --; //删完之后 要 -- 131 } 132 } 133 134 //删除 指定索引的元素 返回删除的元素 135 public T removeByIdx(int idx){ 136 Node tempPtr = this.dummyHead; 137 for (int i=0;i<idx;i++){ 138 tempPtr = tempPtr.next; 139 } 140 Node delNode = tempPtr.next; 141 tempPtr.next = delNode.next; 142 delNode.next = null; //手动释放 143 this.size --; 144 145 return delNode.data; 146 } 147 148 //删除第一个元素 149 public T removeFirst(){ 150 return this.removeByIdx(0); 151 } 152 //删除最后一个元素 153 public T removeLast(){ 154 return this.removeByIdx(this.size-1); 155 } 156 157 @Override 158 public String toString(){ 159 StringBuilder builder = new StringBuilder(); 160 builder.append(String.format("LinkList‘s Data is below: [size:%d] \n", this.size)); 161 // Node tempPtr = this.dummyHead.next; 162 163 // while (tempPtr !=null){ 164 // builder.append(tempPtr.data +"->"); 165 // tempPtr =tempPtr.next; 166 // } 167 for (Node tempPtr = this.dummyHead.next;tempPtr != null;tempPtr = tempPtr.next) 168 builder.append(tempPtr.data +"->"); 169 170 builder.append("null"); 171 return builder.toString(); 172 } 173 174 }
1 package zcb.demo01; 2 3 public class test { 4 public static void main(String[] args) { 5 MySet_LL<String> mySet_ll = new MySet_LL<>(); 6 7 mySet_ll.add("tom"); 8 mySet_ll.add("egon"); 9 mySet_ll.add("m"); 10 mySet_ll.add("om"); 11 System.out.println( mySet_ll.toString()); 12 mySet_ll.add("tom"); 13 System.out.println( mySet_ll.toString()); 14 mySet_ll.remove("egon"); 15 System.out.println( mySet_ll.toString()); 16 17 18 19 } 20 }
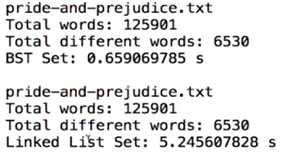
如果集合 是 链表为底层结构的话:
对于 增 add: 它的时间复杂度为 O(n), 本来是O(1),但是因为我们要保证集合中不能有重复元素,所以要先扫描一下全部链表,于是时间复杂度就是 On 了,
对于 查 contains: On
对于 删 remove: On
下面是 二分搜索树的时间复杂度分析:
如果集合 是 链表为底层结构的话:
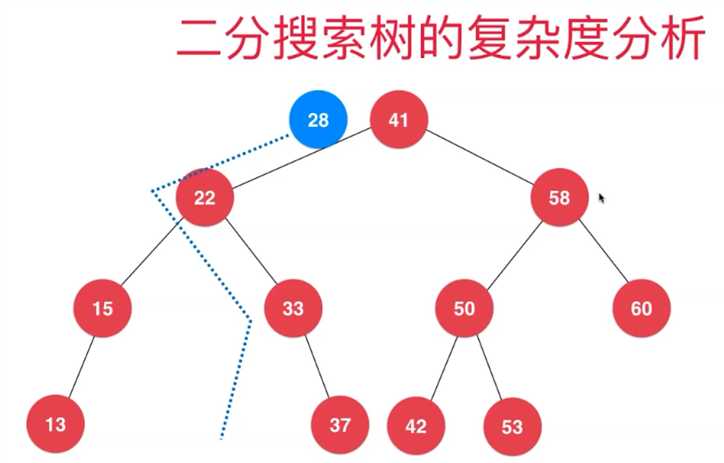
比如,要添加28进来,其实就是相当于 在走一个链表,只不过这个链表的最大长度 是这个树的 高度,
它每次操作都可以 抛弃一半的数据,
所以对于二分搜索树,它的时间复杂度是 O(h), 其中的h 是这棵树的高度,
于是,

下面是 得出 h 和 n 的关系,即二分搜索树 的高度 和n 的关系,
1,满的二分搜索树:满的二分搜索树:(满 :即除了叶子节点,所有的节点,左右孩子都不为空 )
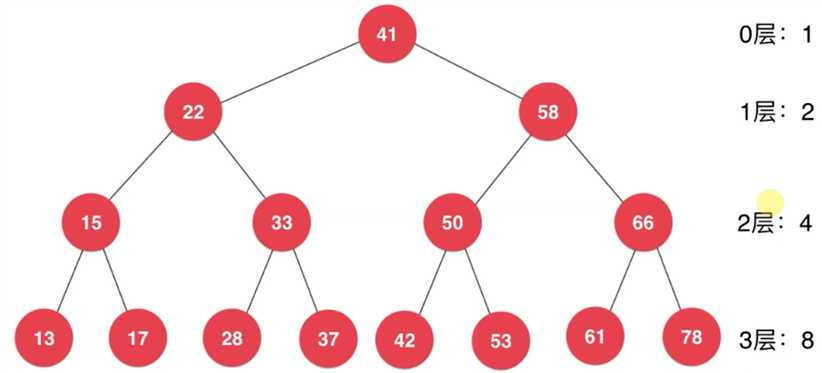
此时:
n = 2^0 + 2^1 + 2^2+...+ 2^(h - 1) = 2^h - 1
所以,此时 h = log2(n + 1)
通常,我们称之为 O( log2(n ) ) 关系 !!! 而且在log 情况下,它的底数 我们也是不关注的,所以 我们一般说 这个h 是O (log n ) 关系,
所以,二分搜索树 的时间复杂度是 O(log n ) !
log n 和 n 的差距:

就是如果100万输入规模,log n 的算法需要1s跑完的话, n 的算法要5万秒,大概14个小时 ,
可能你会觉得二者都在同一天,那么换过来,
如果log n 的算法需要1天的话,那么 n 的算法可能要137 年 才能跑完,
所以,二者的差距还是很大的, 要有个概念,log n 是个非常快的时间复杂度 了,
有时,很多算法的 时间复杂度是 n logn ,它是 比 n方 的 快了好多倍,其实,它和 log n 和 n之间是一致的,
但是,并不是每个二分搜索树都是 满的,(满的 当然好),
需要知道 对于同样的数据,我们可以创建出不同的二分搜索树,
例如:
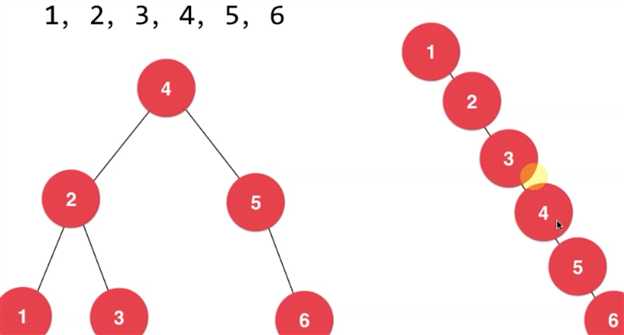
如果,我们的二分搜索树 是右面的情况(也是 最坏的情况),那么它和链表 是无异的, 时间复杂度 也是很高的,
二分搜索树 可能退化 成链表, 就是说,如果一个数据是 按照顺序进来的话,那么,它就是退化成了 链表的情况,也是最差的情况了,

这也是 二分搜索树的局限性所在,解决这个问题的方法 就是可以创建个 平衡二叉树 (后面涉及),
总结下:
二分搜索树 的时间复杂度 最准确的说法是:O h ,这个 h是树的高度,
但是,对于大多数的情况,h 都可以达到 log n 的级别,
这里使用java 中提供的集合 TreeSet ,它的底层是 由一个 红黑树 的,所以不会出现 上面的最差情况,
1 package zcb.demo01; 2 import java.util.TreeSet; 3 4 public class test{ 5 public static void main(String[] args) { 6 String [] words = {"gin", "zen", "gig", "msg"}; 7 Solution.uniqueMorseRepresentations(words); 8 } 9 } 10 class Solution { 11 public static int uniqueMorseRepresentations(String[] words) { 12 TreeSet <String> set = new TreeSet <String>(); // java自带的 TreeSet集合 13 14 String [] codes = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."}; 15 for(String item : words){ // 遍历数组 16 StringBuilder builder = new StringBuilder(); 17 for(int i =0;i<item.length();i++){ // 遍历 字符串 18 builder.append( codes[item.charAt(i) - ‘a‘] ); 19 } 20 set.add(builder.toString()); 21 } 22 return set.size(); 23 } 24 }
上面我们用 二分搜索树为 底层结构 实现的 集合 是个有序集合, 用 链表 为底层结构 实现的集合 是个无序集合,
通常,有序的都是基于 搜索树来实现的, 但是,有很多问题,不需要使其有序, 这时可以通过 链表实现,但是,它的效率,太低,可以采用其他结构,例如 哈希表 来实现,
哈希表 会比 搜索树还要稍微快点,
可以这样认为,搜索树 因为插入和删除 ,和查找及其快,所以 是要付出代价的,这个代价就是 它的时间复杂度稍微 低于 哈希表,
补充: 集合 其实还有 多重集合,集合中的元素可以重复,
一一映射:
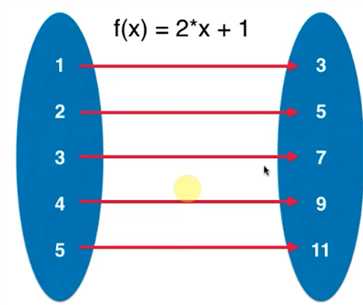
在很多语言里面,称这种结构是 字典, (在 java c++ 中称为是Map)
![]()
生活中使用 映射的场景:(一个key 一个value)
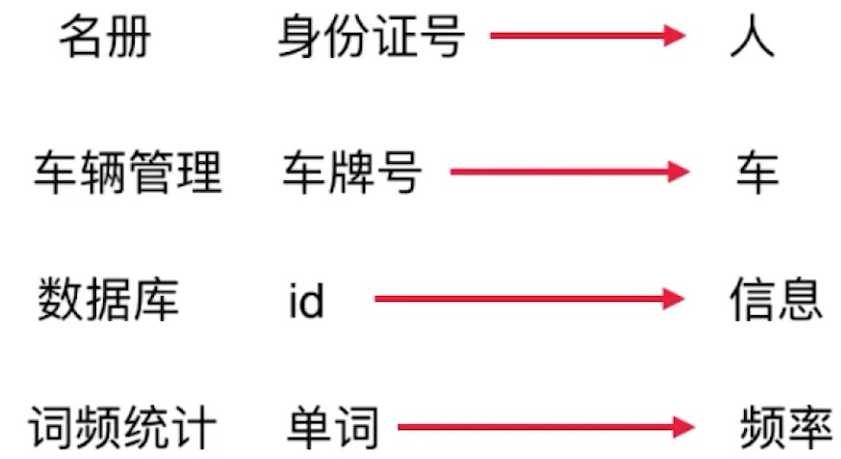
所以,存储 (键 值 ) 数据对 的数据结构 ,我们称之为 映射 (Map),
我们使用 它的主要目的是 快速根据key 来找到value ,
虽然,它是存储两个值,我们依然可以快速的通过 链表 或者二分搜索树 来实现它,

定义Map 接口如下:

1 package zcb.demo02; 2 3 public interface Map<K,V> { 4 void add(K key,V val); 5 V remove(K key); 6 V get(K key); 7 boolean contains(K key); 8 void set(K key,V val); 9 int getSize(); 10 boolean isEmpty(); 11 }
1 package zcb.demo02; 2 3 public class Map_LL <K,V> implements Map<K,V> { 4 private class Node{ 5 public K key;//具体数据 6 public V val; 7 public Node next; //引用(指针) 8 9 //Node 节点的构造器 10 public Node(K key,V val,Node next){ 11 this.key = key; 12 this.val = val; 13 this.next = next; 14 } 15 public Node(K key,V val){ 16 this(key,val,null); 17 } 18 public Node(){ 19 this(null,null,null); 20 } 21 22 @Override 23 public String toString(){ 24 return this.key.toString() + ": "+this.val.toString(); 25 } 26 } 27 private Node dummyHead; //虚拟头节点 28 private int size; 29 30 public Map_LL(){ 31 dummyHead = new Node(); 32 size = 0; 33 } 34 35 // 辅助 私有函数 getNode 指定key 可以返回相应的 Node 36 private Node getNode(K key){ 37 Node tempPtr = this.dummyHead.next; 38 while (tempPtr != null){ 39 if(tempPtr.key.equals(key) ){ 40 return tempPtr; 41 } 42 tempPtr = tempPtr.next; 43 } 44 return null; 45 } 46 47 //获取映射中的元素个数 48 public int getSize(){ 49 return this.size; 50 } 51 //返回映射是否为空 52 public boolean isEmpty(){ 53 return this.size ==0; 54 } 55 56 //映射中 是否包含某个key 57 public boolean contains(K key){ 58 Node node = this.getNode(key); 59 return node != null; 60 } 61 //根据key 得到 val 62 public V get(K key){ 63 Node node = this.getNode(key); 64 if(node != null){ 65 return node.val; 66 } 67 return null; 68 } 69 // 添加新元素 70 public void add(K key,V val){ 71 // 先判断是否 已经存在 该key 72 Node node = this.getNode(key); 73 if(node == null){ 74 // 可以直接在链表 头添加节点,时间复杂度低 75 // 下面是一步操作 76 this.dummyHead.next = new Node(key,val,this.dummyHead.next); 77 this.size ++; 78 }else{ 79 //已经存在 ,就更新 val 80 node.val = val; 81 } 82 } 83 84 // 更新某个 val 85 public void set(K key,V val){ 86 Node node = getNode(key); 87 if(node == null){ 88 throw new IllegalArgumentException(key + "不存在"); 89 }else{ 90 node.val = val; 91 } 92 } 93 94 // 移除某个key ,返回对应的val 95 public V remove(K key){ 96 Node tempPtr = this.dummyHead; 97 while (tempPtr.next != null){ 98 if(tempPtr.next.key.equals(key)){ 99 break; 100 } 101 tempPtr = tempPtr.next; 102 } 103 if(tempPtr.next != null){ 104 Node delNode = tempPtr.next; 105 tempPtr.next = delNode.next; 106 delNode.next = null; // delNode 里面存的地址要清空 107 this.size --; 108 return delNode.val; 109 }else{ 110 return null; 111 } 112 } 113 114 // toString 115 @Override 116 public String toString(){ 117 StringBuilder builder = new StringBuilder(); 118 Node tempPtr = this.dummyHead.next; 119 while (tempPtr != null){ 120 builder.append(tempPtr.key +":"+tempPtr.val +" | "); 121 tempPtr = tempPtr.next; 122 } 123 return builder.toString(); 124 } 125 126 127 }
1 package zcb.demo02; 2 3 public class test { 4 public static void main(String[] args) { 5 Map_LL<String,String> map_ll = new Map_LL<>(); 6 7 map_ll.add("name","egon"); 8 map_ll.add("age","18"); 9 System.out.println(map_ll); 10 map_ll.set("name","a"); 11 System.out.println(map_ll); 12 map_ll.add("school","XXX"); 13 System.out.println(map_ll); 14 map_ll.remove("name"); 15 System.out.println(map_ll); 16 17 System.out.println(map_ll.contains("name")); 18 19 System.out.println(map_ll.getSize()); 20 System.out.println(map_ll.isEmpty()); 21 22 } 23 24 25 }
1 package zcb.demo02; 2 3 public class Map_BST<K extends Comparable<K>,V> implements Map<K,V> { 4 private class Node { 5 public K key; 6 public V val; 7 public Node left,right; 8 9 // 构造器 10 public Node(K key,V val,Node left,Node right){ 11 this.key = key; 12 this.val = val; 13 this.left = left; 14 this.right = right; 15 } 16 17 @Override 18 public String toString(){ 19 return this.key +": "+this.val; 20 } 21 } 22 23 private Node root; 24 private int size; 25 26 public Map_BST(){ 27 root = null; 28 size = 0; 29 } 30 31 @Override 32 public int getSize(){ 33 return size; 34 } 35 @Override 36 public boolean isEmpty(){ 37 return size == 0; 38 } 39 40 @Override 41 public void add(K key,V val){ 42 root = add(root,key,val); 43 } 44 // 实际进行递归 的函数 45 public Node add(Node node,K key,V val){ //返回值必须是 根节点 46 if(node == null){ 47 size ++; 48 return new Node(key,val,null,null); 49 } 50 51 if(key.compareTo(node.key) < 0 ){ 52 //向左 53 node.left = add(node.left,key,val); 54 }else if(key.compareTo(node.key) >0 ){ 55 //向右 56 node.right = add(node.right,key,val); 57 }else{ 58 node.val = val; // 如果key 已经存在 直接 更新val 59 } 60 61 return node; 62 } 63 64 // 辅助函数 返回 以node 为根节点, key 所在的节点 65 private Node getNode(Node node, K key){ 66 if(node == null){ 67 return null; 68 } 69 if(key.compareTo(node.key) < 0 ){ 70 // 向左 71 return getNode(node.left,key); 72 }else if(key.compareTo(node.key) > 0 ){ 73 // 向右 74 return getNode(node.right,key); 75 }else{ 76 return node; 77 } 78 79 } 80 81 // 映射中 是否包含某个key 82 @Override 83 public boolean contains(K key){ 84 Node node = getNode(root,key); 85 return node != null; 86 } 87 88 // 返回 映射中 key 对应的val 89 @Override 90 public V get(K key){ 91 Node node = getNode(root,key); 92 return node == null ? null:node.val; 93 } 94 95 // 更新 映射中 key 对应的val 96 @Override 97 public void set(K key,V val){ 98 Node node = getNode(root,key); 99 if(node == null) 100 throw new IllegalArgumentException(key + " 不存在 "); 101 // else 102 // node.val = val; 103 node.val = val; 104 } 105 106 // 删除映射 中的 key, 并返回它对应的 val 107 @Override 108 public V remove(K key){ 109 Node node = getNode(root,key); 110 if(node != null){ 111 root = remove(root,key); 112 return node.val; 113 } 114 return null; 115 } 116 // 实际进行递归的函数 117 public Node remove(Node node,K key){ 118 if(node == null){ 119 return null; 120 } 121 if(node.key.compareTo(key) < 0){ 122 // 向左 123 node.left = remove(node.left,key); 124 return node; 125 }else if(node.key.compareTo(key) > 0){ 126 // 向右 127 node.right = remove(node.right,key); 128 return node; 129 }else{ 130 // 找到了 要删除的node 131 132 // 待删节点的左子树 为null 的情况 (此时直接将 右面子树放到待删节点的位置即可) 133 if(node.left == null){ 134 Node rightNode = node.right; 135 node.right = null; // 136 size --; 137 return rightNode; //此时返回的是 node 右子树的根节点,而不返回node了 138 }else if(node.right == null){ 139 // 右子树 为null 的话, 140 Node leftNode = node.left; 141 node.left = null; 142 size --; 143 return leftNode; 144 }else{ 145 //左右 子树都不为 null 146 // 此时在 左子树中找出最大的 或者 右子树中最小的 替换要删除的node 147 Node min_rt = minimum(node.right); //minimum 是找出最小节点 148 149 min_rt.right = removeMin(node.right); //removeMin 删除最小节点 并返回 根节点 150 min_rt.left = node.left; 151 node.left = node.right = null; 152 size --; 153 154 return min_rt; 155 } 156 } 157 } 158 159 // 找出树中的最小节点 返回的 不是根节点 160 private Node minimum(Node node){ 161 if(node == null){ 162 return null; 163 } 164 if(node.left == null){ 165 //node 即为最小的节点 166 return node; 167 } 168 return minimum(node.left); 169 } 170 // 删除 树中的最小 节点 并 返回根节点 171 private Node removeMin(Node node){ 172 if(node == null){ 173 return null; 174 } 175 if(node.left == null){ 176 // 此时node 即为最小节点 177 Node rightNode = node.right; 178 node.right = null; 179 size --; 180 return rightNode; 181 } 182 node.left = removeMin(node.left); 183 return node; 184 } 185 186 }
1 package zcb.demo02; 2 3 public class test { 4 public static void main(String[] args) { 5 Map_BST<String,String> map_bst = new Map_BST<>() ; 6 7 8 map_bst.add("name","egon"); 9 System.out.println(map_bst.getSize()); 10 map_bst.add("name","a"); 11 System.out.println(map_bst.getSize()); 12 System.out.println("========================================="); 13 14 map_bst.add("age","18"); 15 System.out.println(map_bst.getSize()); 16 System.out.println( map_bst.contains("name")); 17 System.out.println("========================================="); 18 19 map_bst.remove("name"); 20 System.out.println(map_bst.getSize()); 21 System.out.println(map_bst.contains("name")); 22 System.out.println("========================================="); 23 24 System.out.println(map_bst.get("age")); 25 map_bst.set("age","12"); 26 System.out.println(map_bst.get("age")); 27 System.out.println("========================================="); 28 29 map_bst.remove("name"); 30 map_bst.remove("age"); 31 System.out.println(map_bst.isEmpty()); 32 33 System.out.println("========================================="); 34 35 map_bst.set("name","bb"); // 此时会 抛出一个异常,告诉我们 name 不存在 36 37 } 38 39 40 }

有序映射 指 的是映射中key 是有序的, (二分搜索树为底层实现结构)
无序映射 指 的是映射中key 是无序的, (链表为底层实现结构 ,But 因为链表的效率 太低,通常使用 哈希表来实现 )
映射中的 键是可以重复的,
二者是十分类似的,

package zcb.demo02; import java.util.ArrayList; import java.util.TreeSet; public class test { public static void main(String[] args) { int [] arr1 = {1,2,2,1}; int [] arr2 = {2,2}; int[] ret = Solution.intersection(arr1,arr2); System.out.println(ret); } } class Solution { public static int[] intersection(int[] nums1, int[] nums2) { TreeSet<Integer> set = new TreeSet<>(); for(int item:nums1){ set.add(item); } ArrayList<Integer> arr = new ArrayList<>(); for (int item:nums2){ if(set.contains(item) ){ // set 包含item arr.add(item); set.remove(item); //一定要有, } } int [] res = new int []{ arr.size()}; for (int i=0;i<arr.size();i++){ res[i] = arr.get(i); } return res; } }
这个是允许有重复元素的集合,
1 package zcb.demo02; 2 import java.util.ArrayList; 3 import java.util.TreeMap; 4 public class test { 5 public static void main(String[] args) { 6 int [] arr1 = {1,2,2,1}; 7 int [] arr2 = {2,2}; 8 int [] res = Solution.intersect(arr1,arr2); 9 System.out.println(res); 10 } 11 } 12 class Solution { 13 public static int[] intersect(int[] nums1, int[] nums2) { 14 TreeMap<Integer,Integer> treeMap = new TreeMap<>(); 15 for (int item:nums1){ 16 if(!treeMap.containsKey(item)){ //如果不包含 item 17 treeMap.put(item,1); 18 }else{ 19 treeMap.put(item,treeMap.get(item) + 1); 20 } 21 } 22 23 ArrayList<Integer> arr = new ArrayList<>(); 24 // 遍历 nums2 25 for(int item:nums2){ 26 if(treeMap.containsKey(item)){ 27 arr.add(item); 28 treeMap.put(item,treeMap.get(item) - 1); 29 if(treeMap.get(item) == 0){ 30 treeMap.remove(item); 31 } 32 } 33 } 34 35 int [] res = new int[arr.size()]; 36 for (int i =0;i<arr.size();i++){ 37 res[i] = arr.get(i); 38 } 39 return res; 40 } 41 }
补:其实 ,与哈希表相关的很多问题都可以用TreeSet 和 TreeMap 来解决 (它们是基于平衡二叉树(更准确是红黑树) 实现的集合 和映射 ),也就是我们的集合 和 映射, 也可以使用HashSet 和 HashMap 来解决,(它们是基于Hash 表实现的集合 和映射 )
我们这里自定的集合 用的底层结构是 ArrayList (动态数组), 自定义的 映射的底层结构是 搜索二叉树,
关于哈希表 ,平衡二叉树 和 红黑树,后面有,
原文:https://www.cnblogs.com/zach0812/p/12344716.html
